Salesforce AI Research
@SFResearch
We advance state-of-the-art #AI techniques that pave the path for innovative products at Salesforce. Focus areas include #AgenticAI, #NLP, #TrustedAI.
🔬 Our research team is pioneering AI agents from the ground up. We're developing autonomous systems that could revolutionize data-driven sustainability decisions across industries—all while maintaining ethical standards & sustainability in our research process. Learn more:…

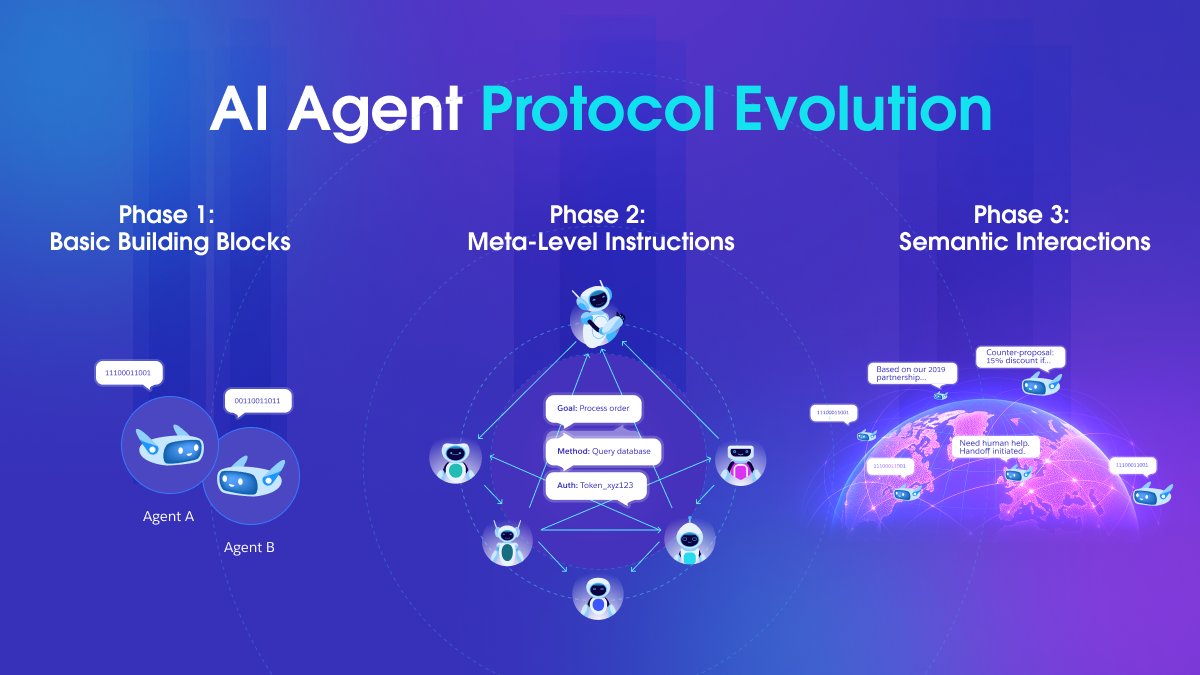
While everyone talks about AI protocols, the real competitive advantage goes to organizations mapping their work ontology NOW. @silviocinguetta explains why companies with well-defined business taxonomies will rapidly deploy interoperable agents tomorrow. This insight on…
Enterprise AI can't thrive in the "Agentic Wild West" we're living in today. In order to collaborate across companies, AI agents will need universal protocols. My thoughts on the interoperable #FutureofAI: sforce.co/3Iv7Ss6
📰 @VentureBeat deep dive on MCPEval is live! 📄 Paper: bit.ly/3TKXpLR 📰 Article: bit.ly/40tFg96 "We now need to figure out how to evaluate [agents] properly" - the challenge MCPEval solves by bringing testing to the same environment where agents actually…

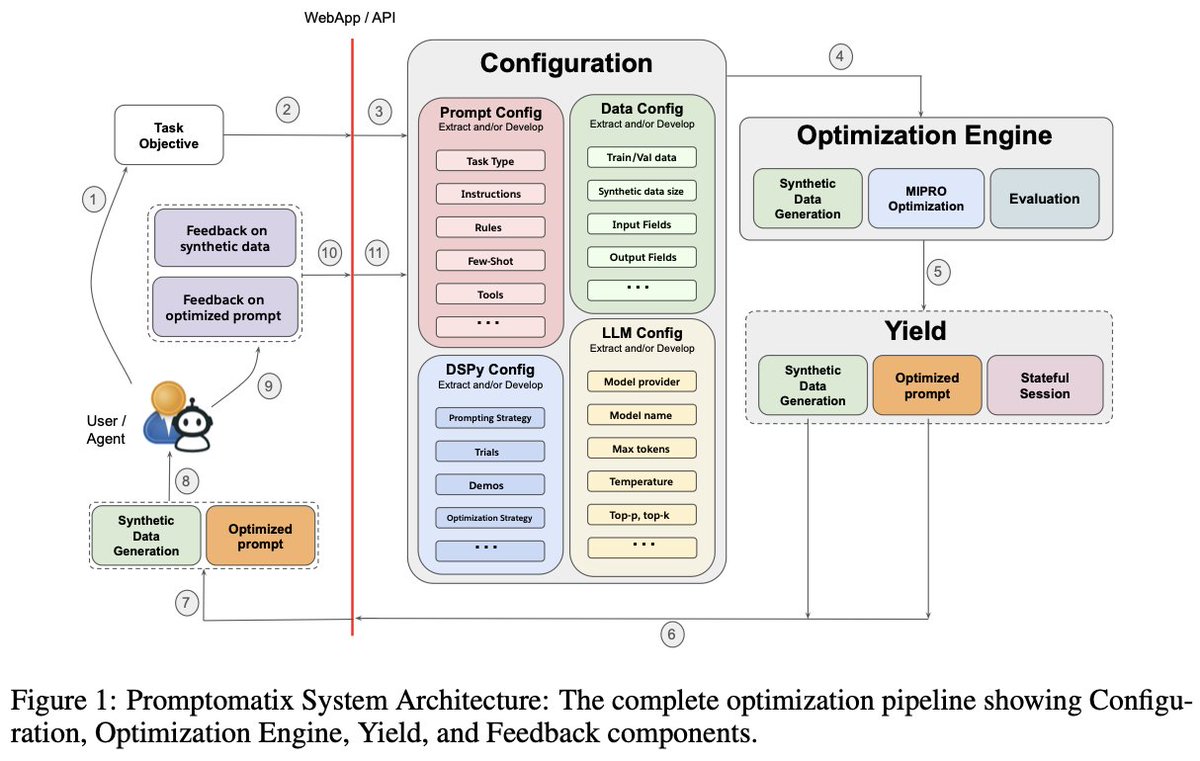
💡 Promptomatix: An Automatic Prompt Optimization Framework for Large Language Models 💡 📄 Paper: bit.ly/44IAvuO 💻 Code: bit.ly/4lLjQgd 😵💫 Have a task but experiencing prompt engineering existential dread? Few-shot or zero-shot? Chain-of-thought or ReAct?…
🏆 #ICML2025 Best Paper Award: AI Safety Should Prioritize the Future of Work 📄 Paper: arxiv.org/abs/2504.13959 🎉 Congratulations to Sanchaita Hazra @hsanchaita, Bodhisattwa Prasad Majumder @mbodhisattwa, and Tuhin Chakrabarty @TuhinChakr for winning the Outstanding Award —…

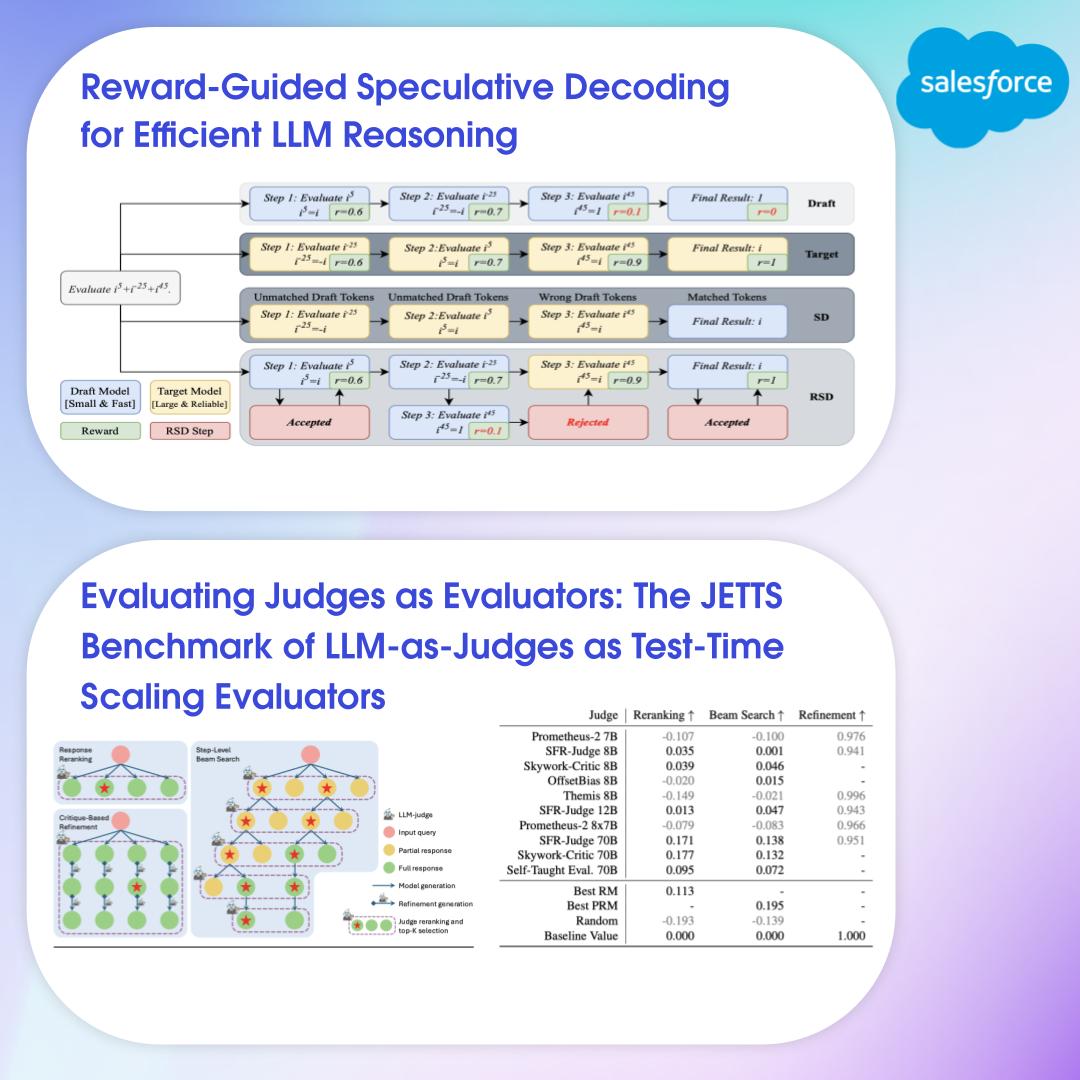
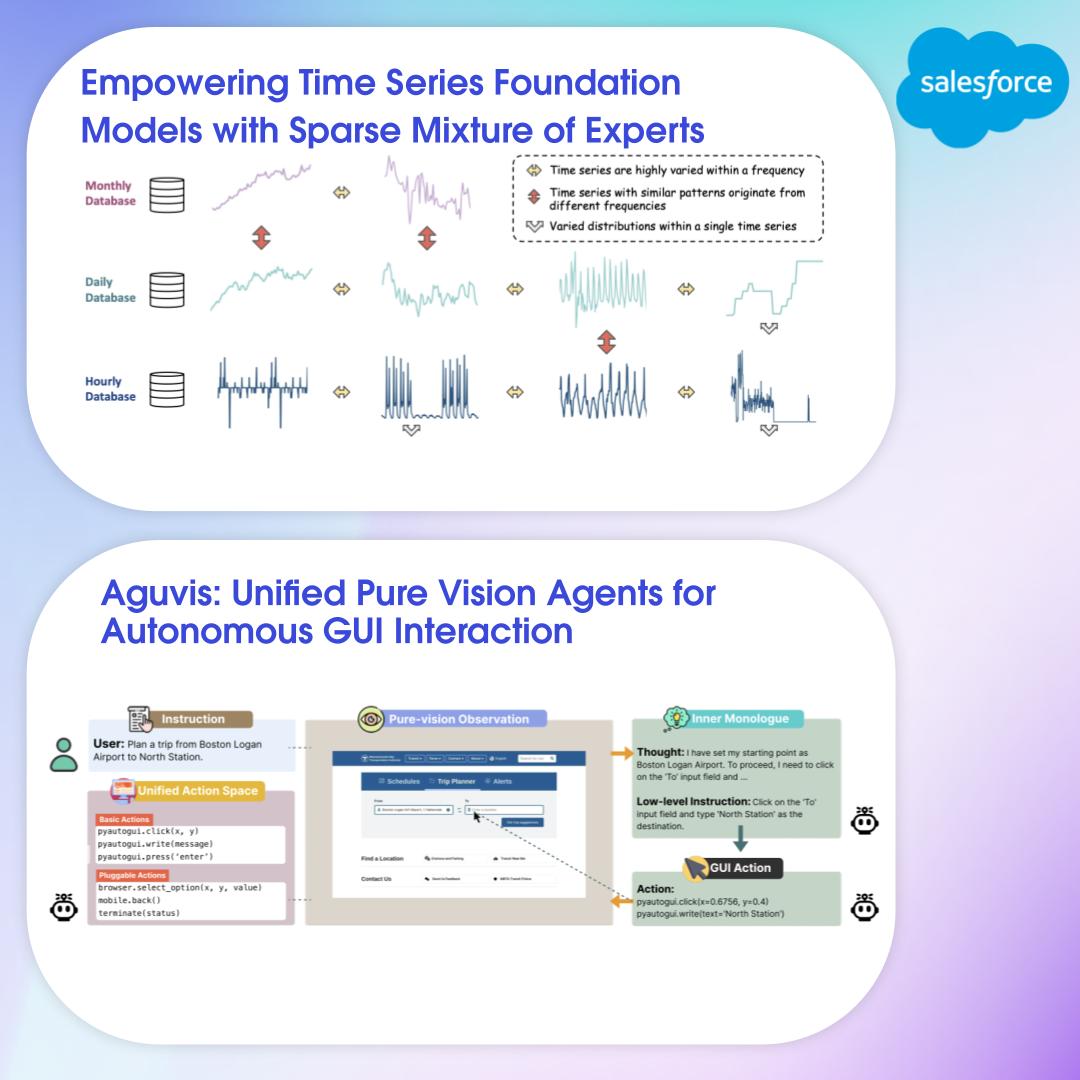
What an amazing #ICML2025 in Vancouver! Our AI Research team had incredible conversations about the future of AI and machine learning. Thanks to everyone who stopped by to discuss our accepted papers. If you missed them, here are all the links - bookmark these for your research:…


🔧 Explore @Salesforce's open source projects on @github! We're building the future through collaboration & innovation. Featured repositories: ➡️ CodeGen - AI code generation ➡️ LAVIS - Language-vision AI ➡️ Lightning Web Components ➡️ Salesforce CLI ➡️ Merlion - Time series…

⚡ Introducing MCPEval: the first automated evaluation framework for AI agents built on Model Context Protocol: 🔗 Paper: bit.ly/3TKXpLR 🔗 Code: bit.ly/44ZnUSN ✅ End-to-end task generation & verification ✅ Deep evaluation across 5 real-world domains ✅…
🧠 Human-amplifying AI starts in the research lab. Our work on reasoning & alignment shapes whether agents replace or enhance human potential. 85% query resolution reflects years of research building AI that handles complexity while preserving human empathy, creativity & judgment…
AI: Replace us or amplify us? Agentforce proves the power of Human + AI: 85% of queries resolved, 17% lower service costs. Read my FT piece on designing AI to elevate humanity. 🤝🤖 #Agentforce #AI #FutureOfWork 🔗 ft.com/content/3db52a…
🇨🇦 Excited to present our work at @COLM_conf in Montreal! Oct 7-10 at Palais des Congrès!📄 Our accepted papers: CodeXEmbed: A Generalist Embedding Model Family for Multilingual and Multi-task Code Retrieval 👥Authors: Ye Liu, Rui Meng, Shafiq Joty @JotyShafiq, Silvio Savarese…

The counterintuitive finding: explicit step-by-step planning actually hurts performance on complex problems 🤯 SPARKLE reveals RL’s real power—fundamentally changing how models integrate knowledge (+4.3% gain). This mechanistic understanding is exactly what AI needs.
🤔 Ever wonder where reinforcement learning actually boosts (or hurts) LLM’s reasoning capabilities? Meet SPARKLE—a new analysis framework that dissects gains from RL in planning, knowledge integration, and subproblem solving. 📄 Paper: arxiv.org/abs/2506.04723 🌐 Project:…
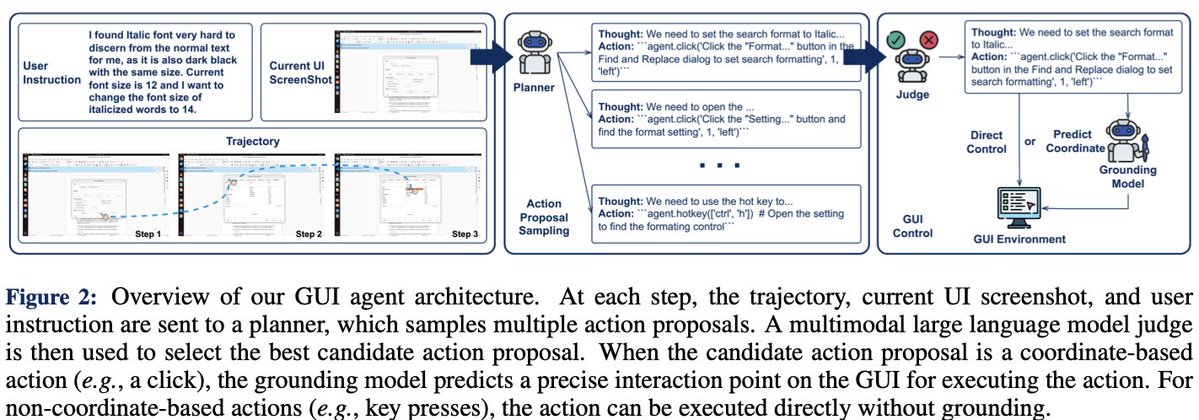
🚨 GTA1, our GUI Test-time Scaling Agent 🚨 📄 Paper: arxiv.org/abs/2507.05791 🔗 Project: os-world.github.io 💻 Code: github.com/Yan98/GTA1 🧠 7B/32B/72B models: huggingface.co/HelloKKMe 🏆 Top-1 on OSWorld benchmark (45.2% success rate), outperforming OpenAI’s CUA. GTA1…
💡 Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning💡 📝 Paper: arxiv.org/abs/2506.04723 📎 Project: sparkle-reasoning.github.io 🔗 Code: github.com/sparkle-reason… We introduce SPARKLE - a fine-grained framework to understand HOW reinforcement…

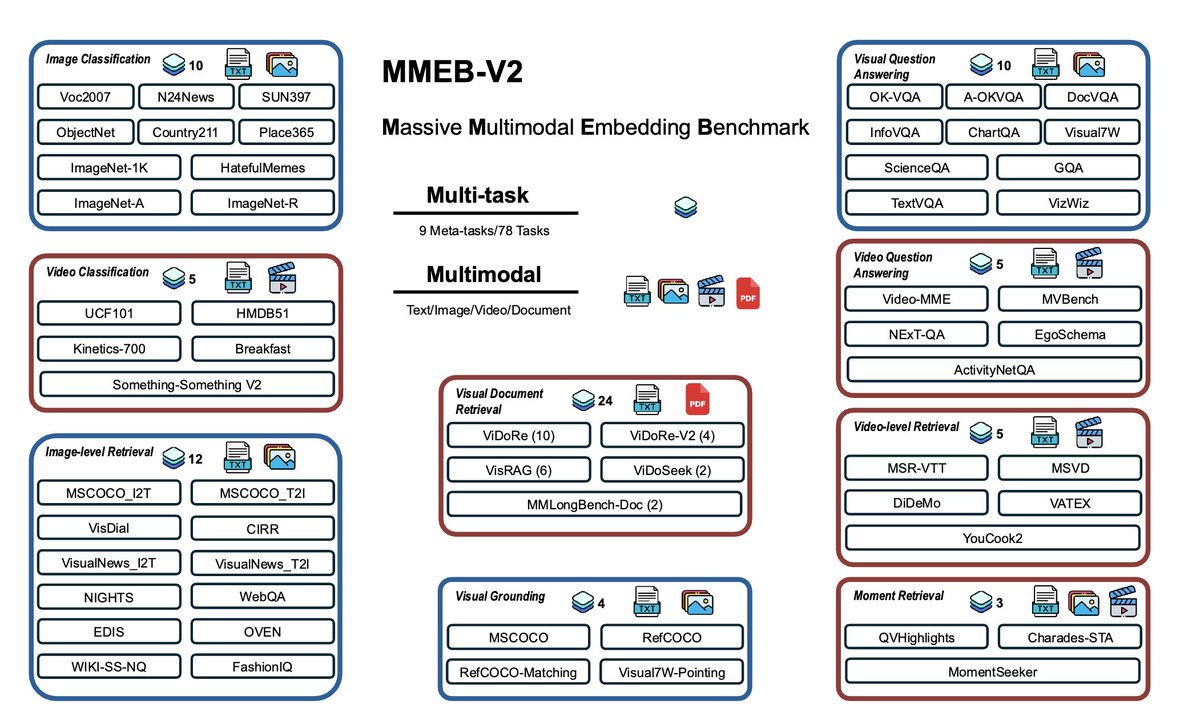
🚨 Introducing VLM2Vec-V2 & MMEB-V2 🚨 At @Salesforce, we're advancing multimodal embeddings beyond natural images to unify videos, visual documents, and images in a single 2B parameter model. 📄 Paper: arxiv.org/abs/2507.04590 💻 Code: github.com/TIGER-AI-Lab/V… 🤗 Model:…
💡LZ Penalty: version 2 dropped this week with major enhancements! Repetitive text generation remains one of the hardest unsolved problems in LLM deployment. Current penalties are Band-Aids that don’t work reliably. We built something different: a penalty that understands…

🏜️ Taming the 'Agentic Wild West': How AI Protocols Will Expand Enterprise Boundaries 🏜️ 📝 Blog: salesforce.com/blog/how-ai-pr… We're at the TCP/IP moment for AI agents. The future belongs to orgs that shape emerging standards early. Great insights from our Chief Scientist…