
Jiarui Yao
@ExplainMiracles
UIUC CS PhD, 24
Thrilled to share my first project at NVIDIA! ✨ Today’s language models are pre-trained on vast and chaotic Internet texts, but these texts are unstructured and poorly understood. We propose CLIMB — Clustering-based Iterative Data Mixture Bootstrapping — a fully automated…
(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…
Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative pros and cons of different RM types. 📰 We investigate why RMs implicitly defined by language models (LMs) often generalize worse than explicit RMs 🧵 1/6
🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder. 💡 How do we tackle these extremely long, information-dense sequences without exhausting GPU memory or hitting API limits? We introduce 👓Ego-R1: A framework…
Can LLMs make rational decisions like human experts? 📖Introducing DecisionFlow: Advancing Large Language Model as Principled Decision Maker We introduce a novel framework that constructs a semantically grounded decision space to evaluate trade-offs in hard decision-making…
(1/5) Want to make your LLM a skilled persuader? Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind"! For details: 📄Arxiv: arxiv.org/pdf/2505.22961 🛠️GitHub: github.com/ulab-uiuc/ToMAP
📢 New Paper Drop: From Solving to Modeling! LLMs can solve math problems — but can they model the real world? 🌍 📄 arXiv: arxiv.org/pdf/2505.15068 💻 Code: github.com/qiancheng0/Mod… Introducing ModelingAgent, a breakthrough system for real-world mathematical modeling with LLMs.
How to improve the test-time scalability? - Separate thinking & solution phases to control performance under budget constraint - Budget-Constrained Rollout + GRPO - Outperforms baselines on math/code. - Cuts token 30% usage without hurting performance huggingface.co/papers/2505.05…
🎉 Evaluation Agent is accepted to ACL 2025 Main! Big congrats to the co-authors! We've open-sourced the code & prompt database: 📷 github.com/Vchitect/Evalu…… Let’s push LLM evaluation for GenAI to the next level! 📷#ACL2025 #LLM #GenAI
Tired of waiting forever to evaluate your Gen models? 🚀 Meet 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗔𝗴𝗲𝗻𝘁 🤖📊 – a fast, efficient, and promptable framework that evaluates your Gen models in just one line of input! ⚡ Inspired by a human-like evaluation process, it recursively samples a few…
🚀 Can we cast reward modeling as a reasoning task? 📖 Introducing our new paper: RM-R1: Reward Modeling as Reasoning 📑 Paper: arxiv.org/pdf/2505.02387 💻 Code: github.com/RM-R1-UIUC/RM-… Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we…
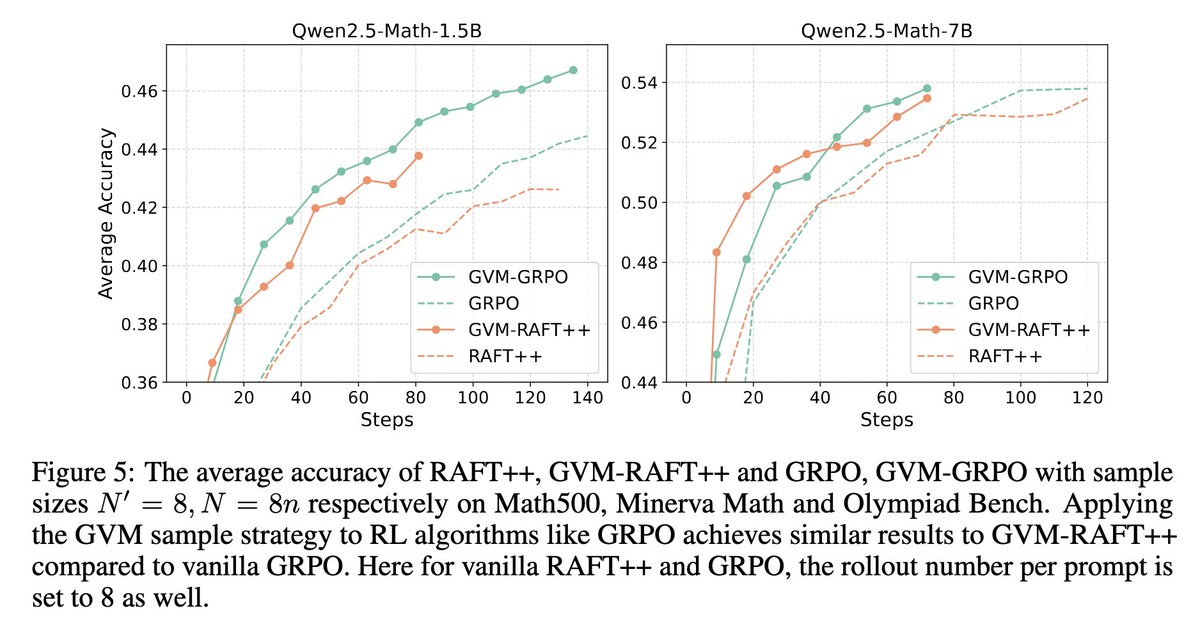
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT – Improves accuracy on math…



Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…
🚀 Introducing #SparseVideoGen: 2x speedup in video generation with HunyuanVideo with high pixel-level fidelity (PSNR = 29)! No training is required, no perceptible difference to the human eye! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…
Welcome to join our Tutorial on Foundation Models Meet Embodied Agents, with @YunzhuLiYZ @maojiayuan @wenlong_huang ! Website: …models-meet-embodied-agents.github.io
Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
🤖What makes GRPO work? Rejection Sampling→Reinforce→GRPO - RS is underrated - Key of GRPO: implicitly remove prompts without correct answer - Reinforce+Filtering > GRPO (better KL) 💻github.com/RLHFlow/Minima… 📄arxiv.org/abs/2504.11343 👀RAFT was invited to ICLR25! Come & Chat☕️
🚀Can your language model think strategically? 🧠 SMART: Boosting LM self-awareness to reduce Tool Overuse & optimize reasoning! 🌐 arxiv.org/pdf/2502.11435 📊 github.com/qiancheng0/Ope… Smaller models, bigger brains. Smarter tool use, better results! 🔥 #AI #LLM
🚀 Excited to share our latest work on Iterative-DPO for math reasoning! Inspired by DeepSeek-R1 & rule-based PPO, we trained Qwen2.5-MATH-7B on Numina-Math prompts. Our model achieves 47.0% pass@1 on AIME24, MATH500, AMC, Minerva-Math, OlympiadBench—outperforming…