Haocheng Xi
@HaochengXiUCB
First-year PhD in @berkeley_ai. Prev: Yao Class, @Tsinghua_Uni | Efficient Machine Learning & ML sys
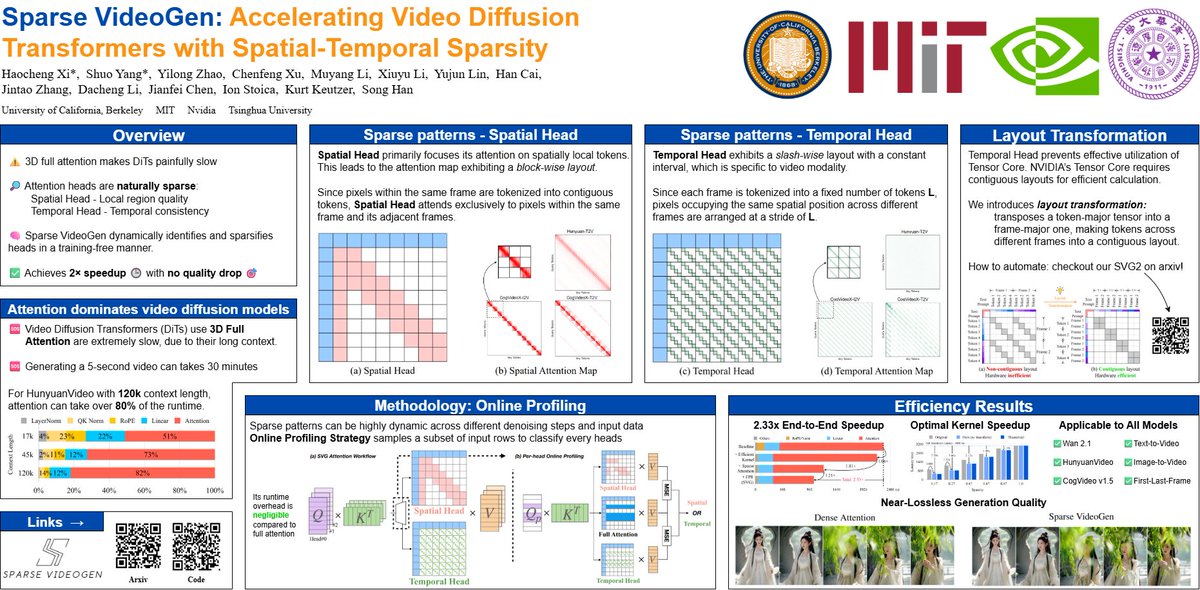
🎉 Come check out our poster at #ICML2025! 🚀 Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity 📍 East Exhibition Hall A-B — #E-3307 🗓️ Poster Session 2 | Tue, Jul 15 | 🕓 4:30–7:00 PM ⚡ We speed up video diffusion transformers by over…
Thank you @ericxtang and the @DaydreamLiveAI team for using StreamDiffusion in building such an exciting platform for creators and builders! Together with @cumulo_autumn and the rest of our team, we are continuously working to advance the open-source StreamDiffusion series for…
18 months ago, @cumulo_autumn and @Chenfeng_X released StreamDiffusion, bringing real-time AI video to consumer GPUs. Today, it powers a vibrant community of creators and builders. Our latest open-source release brings major upgrade in quality and control. Demo here 👇
Empowered by SGLang, NVILA serving now has 4.4x throughput and 2.2x faster response 🚀🚀🚀 Awesome work made by @AndyZijianZhang w/ a lot help from SGLang team!
🚀Summer Fest Day 4: Turbocharging Vision-Language Models with SGLang + NVILA 4.4× throughput, 2.2× faster response time! We've integrated NVILA into SGLang, enabling high-performance, scalable serving of vision-language models. This unlocks a 4.4× TPS boost and significantly…
The SkyRL roadmap is live! Our focus is on building the easiest-to-use high-performance RL framework for agents. We'd love your ideas, feedback, or code to guide the project: github.com/NovaSky-AI/Sky…
QuantSpec appears at #ICML2025! Check our poster at E-2608, Poster Session 5, July 17🎉
🚨Come check out our poster at #ICML2025! QuantSpec: Self-Speculative Decoding with Hierarchical Quantized KV Cache 📍 East Exhibition Hall A-B — #E-2608 🗓️ Poster Session 5 | Thu, Jul 17 | 🕓 11:00 AM –1:30 PM TLDR: Use a quantized version of the same model as its own draft…
Video understanding isn't just recognizing —it demands reasoning across thousands of frames. Meet Long-RL🚀 Highlights: 🧠 Dataset: LongVideo-Reason — 52K QAs with reasoning. ⚡ System: MR-SP - 2.1× faster RL for long videos. 📈 Scalability: Hour-long videos (3,600 frames) RL…
🔎 SkyRL + Search-R1 Training a multi-turn search agent doesn’t have to be complicated. With SkyRL, reproducing the SearchR1 recipe at high training throughput is quick and easy! We wrote up a detailed guide to show you how: novasky-ai.notion.site/skyrl-searchr1 1/N 🧵
🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
🚀Check out #LPD - our latest work to accelerate autoregressive image generation. LPD stands for Locality-aware Parallel Decoding. ⚡️13× faster than traditional AR models and at least 3.4× faster than previous parallelized AR models. Github: github.com/mit-han-lab/lpd 🧵1/
🚀 Meet #RadialAttention — a static sparse attention mechanism with O(nlogn) complexity for long video generation! ✅ Plug-and-play: works with pretrained models like #Wan, #HunyuanVideo, #Mochi ✅ Speeds up both training&inference by 2–4×, without quality loss 🧵1/4
Sparsity can make your LoRA fine-tuning go brrr 💨 Announcing SparseLoRA (ICML 2025): up to 1.6-1.9x faster LLM fine-tuning (2.2x less FLOPs) via contextual sparsity, while maintaining performance on tasks like math, coding, chat, and ARC-AGI 🤯 🧵1/ z-lab.ai/projects/spars…
Attention! A new and improved attention mechanism has just been proposed by MIT, NVIDIA, Princeton, and others. Radial Attention is a sparse, static attention mechanism with O(n log n) complexity. It focuses on nearby tokens and shrinks the attention window over time. It can…
📢 New Preprint: Self-Challenging Agent (SCA) 📢 It’s costly to scale agent tasks with reliable verifiers. In SCA, the key idea is to have another challenger to explore the env and construct tasks along with verifiers. Here is how it achieves 2x improvements on general…
1/N 📢 Introducing UCCL (Ultra & Unified CCL), an efficient collective communication library for ML training and inference, outperforming NCCL by up to 2.5x 🚀 Code: github.com/uccl-project/u… Blog: uccl-project.github.io/posts/about-uc… Results: AllReduce on 6 HGX across 2 racks over RoCE RDMA
We release Search Arena 🌐 — the first large-scale (24k+) dataset of in-the-wild user interactions with search-augmented LLMs. We also share a comprehensive report on user preferences and model performance in the search-enabled setting. Paper, dataset, and code in 🧵
🚀The code for Fast-dLLM is now open-source! 💥 Fast-dLLM achieves a 27.6× end-to-end speedup on 1024-token sequences with less than 2% accuracy drop. Check out the code here: github.com/NVlabs/Fast-dL…
🚀 Fast-dLLM: 27.6× Faster Diffusion LLMs with KV Cache & Parallel Decoding 💥 Key Features🌟 - Block-Wise KV Cache Reuses 90%+ attention activations via bidirectional caching (prefix/suffix), enabling 8.1×–27.6× throughput gains with <2% accuracy loss 🔄 -…
Excited to begin my summer internship at NVIDIA! This marks my second time joining the company—though it’s my first experience working at the Santa Clara headquarters. Previously I worked on low-precision training and co-authored two projects: COAT, accepted at ICLR 2025, and…

1/N Introducing SkyRL-SQL, a simple, data-efficient RL pipeline for Text-to-SQL that trains LLMs to interactively probe, refine, and verify SQL queries with a real database. 🚀 Early Result: trained on just ~600 samples, SkyRL-SQL-7B outperforms GPT-4o, o4-mini, and SFT model…
It's likely the first open RL LLM pipeline that supports real-world, long-horizon, agentic RL training, like software engineering. The optimizations and abstractions are effective and general. (Kudos to the team and happy to have contributed a small part while at Berkeley
Today we’re introducing SkyRL, a RL training pipeline optimized for long-horizon tasks like SWE-Bench, built on top of VeRL and OpenHands. SkyRL introduces an agent layer on top of VeRL: 1. Efficient multi-turn rollouts 2. Tool use 3. Scalable environment execution 1/N