
Muru Zhang
@zhang_muru
First-year PhD @nlp_usc | Student Researcher @GoogleDeepmind | bsms @uwcse | Prevs. @togethercompute @AWS
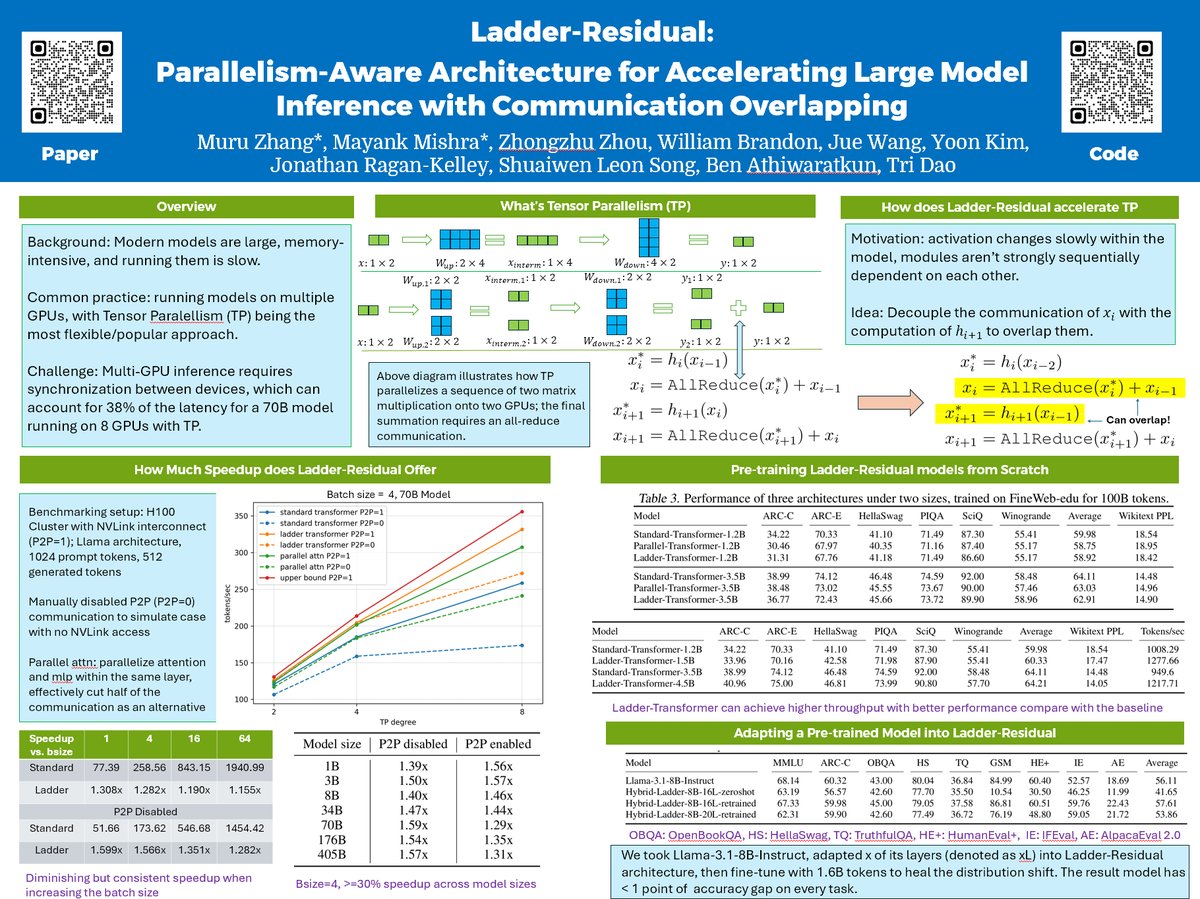
Running your model on multiple GPUs but often found the speed not satisfiable? We introduce Ladder-residual, a parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster! Work done at @togethercompute. Co-1st author with @MayankMish98…

Can we create effective watermarks for LLM training data that survive every stage in real-world LLM development lifecycle? Our #ACL2025Findings paper introduces fictitious knowledge watermarks that inject plausible yet nonexistent facts into training data for copyright…
I’ll be at ACL 2025 next week where my group has papers on evaluating evaluation metrics, watermarking training data, and mechanistic interpretability. I’ll also be co-organizing the first Workshop on LLM Memorization @l2m2_workshop on Friday. Hope to see lots of folks there!
I'm at #ICML2025, presenting Ladder-Residual (arxiv.org/abs/2501.06589) at the first poster session tomorrow morning (7/15 11am-1:30pm), looking forward to seeing you at West Exhibition Hall B2-B3 #W-1000!
Have you noticed… 🔍 Aligned LLM generations feel less diverse? 🎯 Base models are decoding-sensitive? 🤔 Generations get more predictable as they progress? 🌲 Tree search fails mid-generation (esp. for reasoning)? We trace these mysteries to LLM probability concentration, and…
I didn't believe when I first saw, but: We trained a prompt stealing model that gets >3x SoTA accuracy. The secret is representing LLM outputs *correctly* 🚲 Demo/blog: mattf1n.github.io/pils 📄: arxiv.org/abs/2506.17090 🤖: huggingface.co/dill-lab/pils-… 🧑💻: github.com/dill-lab/PILS
Hi all, I'm going to @FAccTConference in Athens this week to present my paper on copyright and LLM memorization. Please reach out if you are interested to chat about law, policy, and LLMs!
Many works addressing copyright for LLMs focus on model outputs and their similarity to copyrighted training data, but few focus on how the model was trained. We analyze LLM memorization w.r.t. their training decisions and theorize on its use in court arxiv.org/abs/2502.16290
LLMs excel at finding surprising “needles” in very long documents, but can they detect when information is conspicuously missing? 🫥AbsenceBench🫥 shows that even SoTA LLMs struggle on this task, suggesting that LLMs have trouble perceiving “negative space” in documents. paper:…
We built sparse-frontier — a clean abstraction that lets you focus on your custom sparse attention implementation while automatically inheriting vLLM’s optimizations and model support. As a PhD student, I've learned that sometimes the bottleneck in research isn't ideas — it's…
read the first letter of every name in the gemini contributors list
Wanna 🔎 inside Internet-scale LLM training data w/o spending 💰💰💰? Introducing infini-gram mini, an exact-match search engine with 14x less storage req than the OG infini-gram 😎 We make 45.6 TB of text searchable. Read on to find our Web Interface, API, and more. (1/n) ⬇️
🤔Conventional LM safety alignment is reactive: find vulnerabilities→patch→repeat 🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵
After a year of internship with amazing folks at @togethercompute, I will be interning at @GoogleDeepMind this summer working on language model architecture! Hit me up and I will get you a boba at the bayview rooftop of my Emeryville apartment 😉


🧐When do LLMs admit their mistakes when they should know better? In our new paper, we define this behavior as retraction: the model indicates that its generated answer was wrong. LLMs can retract—but they rarely do.🤯 arxiv.org/abs/2505.16170 👇🧵
Ever get bored seeing LLMs output one token per step? Check out HAMburger (advised by @ce_zhang), which smashes multiple tokens into a virtual token with up to 2x decoding TPS boost + reduced KV FLOPs and storage while maintaining quality! github.com/Jingyu6/hambur…
Extremely fun read that unifies many scattered anecdotes on RLVR together and conclude with a set of beautiful experiments and explanations :))
🤯 We cracked RLVR with... Random Rewards?! Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by: - Random rewards: +21% - Incorrect rewards: +25% - (FYI) Ground-truth rewards: + 28.8% How could this even work⁉️ Here's why: 🧵 Blogpost: tinyurl.com/spurious-rewar…
Textual steering vectors can improve visual understanding in multimodal LLMs! You can extract steering vectors via any interpretability toolkit you like -- SAEs, MeanShift, Probes -- and apply them to image or text tokens (or both) of Multimodal LLMs. And They Steer!
LLMs naturally memorize some verbatim of pre-training data. We study whether post-training can be an effective way to mitigate unintentional reproduction of pre-training data. 🛠️ No changes to pre-training or decoding 🔥 Training models to latently distinguish between memorized…