Deqing Fu
@DeqingFu
PhD-ing @CSatUSC. Alum @UChicago, B.S. '20, M.S.' 22. Interpretability of LLM; DL Theory; NLP | prev research intern @MetaAI @Google
1+1=3 2+2=5 3+3=? Many language models (e.g., Llama 3 8B, Mistral v0.1 7B) will answer 7. But why? We dig into the model internals, uncover a function induction mechanism, and find that it’s broadly reused when models encounter surprises during in-context learning. 🧵
We show that you can control and steer layout, style, etc in diffusion models using SAEs
I’ll be at #CVPR2025 presenting a spotlight talk at the VisCon Workshop on our latest work: "Emergence and Evolution of Interpretable Concepts in Diffusion Models" 🕒 June 12th, 3:15PM CDT A short thread summarizing the paper 🧵
How to make SAEs useful beyond interpretability and steering? @UpupWang 's work Resa shows: 🧐SAEs can capture the reasoning features (as an interpretability tool) 🤔SAEs can further elicit strong reasoning abilities via SAE-tuning the model (stronger claim than steering, imho)
Sparse autoencoders (SAEs) can be used to elicit strong reasoning abilities with remarkable efficiency. Using only 1 hour of training at $2 cost without any reasoning traces, we find a way to train 1.5B models via SAEs to score 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23.
Sparse autoencoders (SAEs) can be used to elicit strong reasoning abilities with remarkable efficiency. Using only 1 hour of training at $2 cost without any reasoning traces, we find a way to train 1.5B models via SAEs to score 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23.
Excited to be at @CVPR 2025! Looking forward to catching up with old friends and meeting new ones. If you're interested in grabbing coffee, trying out new restaurants, or chatting about generative representation learning, feel free to DM me! A quick summary of my recent works:…
🧐When do LLMs admit their mistakes when they should know better? In our new paper, we define this behavior as retraction: the model indicates that its generated answer was wrong. LLMs can retract—but they rarely do.🤯 arxiv.org/abs/2505.16170 👇🧵
I’ll be giving a talk at Stanford NLP seminar tomorrow about our recent work on multimodal LLMs.
For this week’s NLP Seminar, we are thrilled to host @DeqingFu to talk about Closing the Modality Gap: Benchmarking and Improving Visual Understanding in Multimodal LLMs! When: 5/22 Thurs 11am PT Non-Stanford affiliates registration form (closed at 9am PT on the talk day):…
For this week’s NLP Seminar, we are thrilled to host @DeqingFu to talk about Closing the Modality Gap: Benchmarking and Improving Visual Understanding in Multimodal LLMs! When: 5/22 Thurs 11am PT Non-Stanford affiliates registration form (closed at 9am PT on the talk day):…
Textual steering vectors can improve visual understanding in multimodal LLMs! You can extract steering vectors via any interpretability toolkit you like -- SAEs, MeanShift, Probes -- and apply them to image or text tokens (or both) of Multimodal LLMs. And They Steer!
It’s a great honor to receive a best research assistant award!
Congratulations to all of our @CSatUSC @USCViterbi graduate award recipients! Premankur Banerjee (PhD), Kegan Strawn (PhD), Deqing Fu (PhD) and Zhaotian Weng (MS)! 🎉🏆 @DeqingFu @USCAdvComputing @LarsLindemann2
Congratulations to all of our @CSatUSC @USCViterbi graduate award recipients! Premankur Banerjee (PhD), Kegan Strawn (PhD), Deqing Fu (PhD) and Zhaotian Weng (MS)! 🎉🏆 @DeqingFu @USCAdvComputing @LarsLindemann2
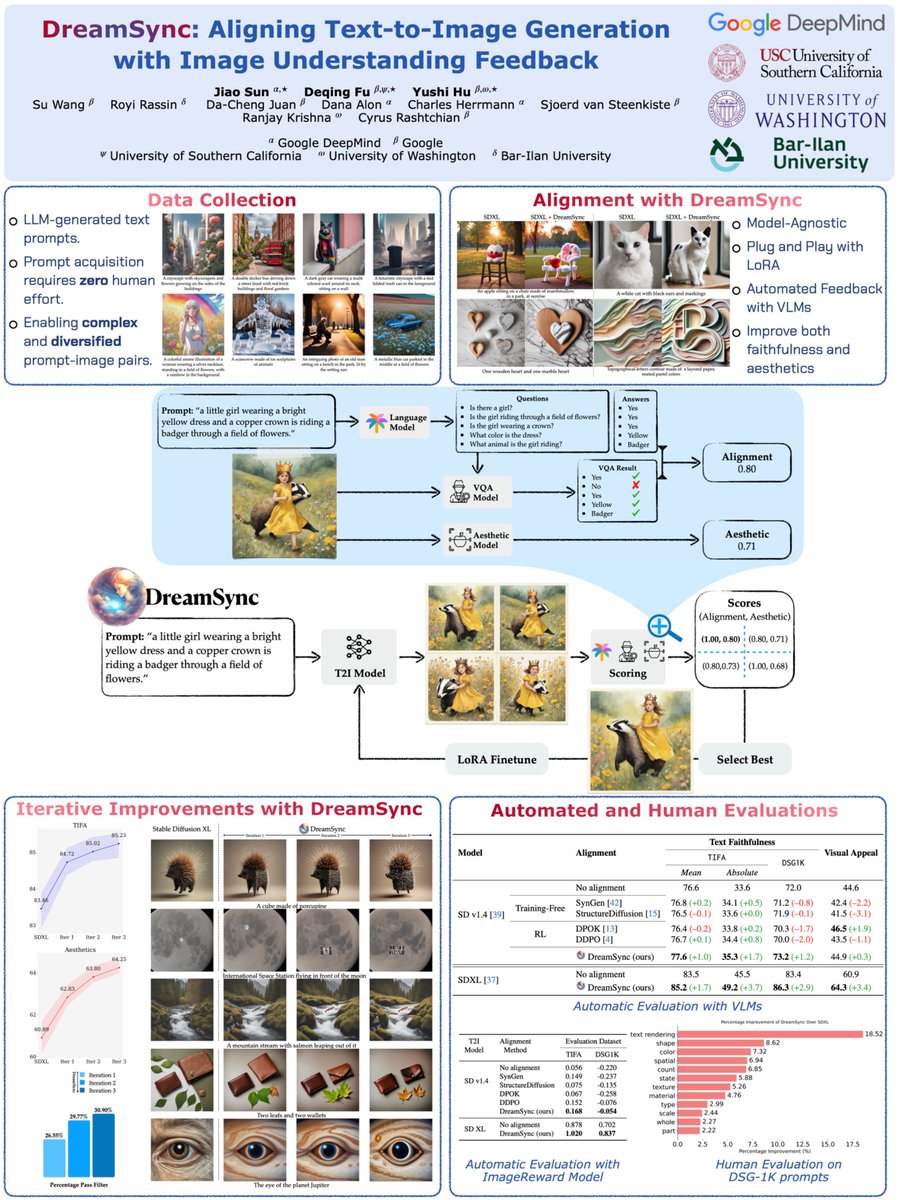
#NAACL2025 Checkout DreamSync's poster tomorrow (May 1) at Hall 3, 4:00-5:30pm. Feel free to stop by to chat about multimodality, evaluation, and interpretability. We are also planning an interpretability lunch tomorrow. Find it on whova and join!