Xueqing Wu
@xueqing_w
NLPer working on vision-language models | PhD student @CS_UCLA | MS @IllinoisCS
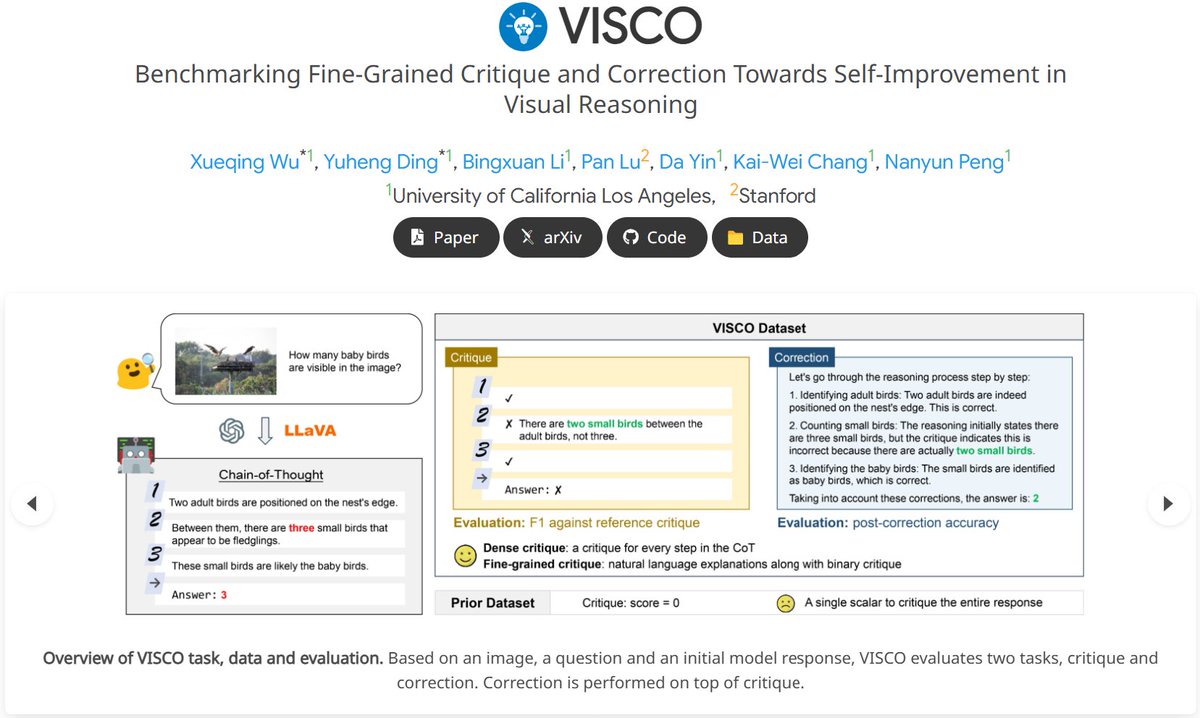
Can VLMs improve 𝘁𝗵𝗲𝗺𝘀𝗲𝗹𝘃𝗲𝘀💪? We propose🔥𝗩𝗜𝗦𝗖𝗢, a benchmark to evaluate VLMs’ 𝗰𝗿𝗶𝘁𝗶𝗾𝘂𝗲 and 𝗰𝗼𝗿𝗿𝗲𝗰𝘁𝗶𝗼𝗻 capabilities, towards the higher goal of VLMs autonomous self-improvement. 🌐Project: visco-benchmark.github.io 📄Paper: arxiv.org/abs/2412.02172

🚀 Hello, Kimi K2! Open-Source Agentic Model! 🔹 1T total / 32B active MoE model 🔹 SOTA on SWE Bench Verified, Tau2 & AceBench among open models 🔹Strong in coding and agentic tasks 🐤 Multimodal & thought-mode not supported for now With Kimi K2, advanced agentic intelligence…
#ICCV2025 Introducing X-Fusion: Introducing New Modality to Frozen Large Language Models It is a novel framework that adapts pretrained LLMs (e.g., LLaMA) to new modalities (e.g., vision) while retaining their language capabilities and world knowledge! (1/n) Project Page:…
Meet Embodied Web Agents that bridge physical-digital realms. Imagine embodied agents that can search for online recipes, shop for ingredients and cook for you. Embodied web agents search internet information for implementing real-world embodied tasks. All data, codes and web…
🤩One last call for poster! Check out for our 💥 𝐕𝐈𝐒𝐂𝐎 💥 benchmark to have a deeper understanding for 𝐕𝐋𝐌 𝐬𝐞𝐥𝐟-𝐜𝐫𝐢𝐭𝐢𝐪𝐮𝐞 𝐚𝐧𝐝 𝐫𝐞𝐟𝐥𝐞𝐜𝐭𝐢𝐨𝐧. ⏱️Come visit us at 𝐄𝐱𝐇𝐚𝐥𝐥 𝐃 #𝟑𝟗𝟔 𝐚𝐭 𝟒-𝟔𝐩𝐦!
Can VLMs improve 𝘁𝗵𝗲𝗺𝘀𝗲𝗹𝘃𝗲𝘀💪? We propose🔥𝗩𝗜𝗦𝗖𝗢, a benchmark to evaluate VLMs’ 𝗰𝗿𝗶𝘁𝗶𝗾𝘂𝗲 and 𝗰𝗼𝗿𝗿𝗲𝗰𝘁𝗶𝗼𝗻 capabilities, towards the higher goal of VLMs autonomous self-improvement. 🌐Project: visco-benchmark.github.io 📄Paper: arxiv.org/abs/2412.02172
🚨 New work: LLMs still struggle at Event Detection due to poor long-context reasoning and inability to follow task constraints, causing precision and recall errors. We introduce DiCoRe — a lightweight 3-stage Divergent-Convergent reasoning framework to fix this.🧵📷 (1/N)
😱Correction: our poster is 𝟰-𝟲𝗽𝗺, Friday ExHall D #396. Welcome to drop by!
Attending my first CV conference 𝐞𝐯𝐞𝐫 as an NLPer! So excited to connect with more people! Check out our💥𝐕𝐈𝐒𝐂𝐎💥benchmark for VLM self-critique and correction at Poster #396, Friday, 2-4pm. We're also presenting at BEAM workshop on Wednesday: beam-workshop2025.github.io
Attending my first CV conference 𝐞𝐯𝐞𝐫 as an NLPer! So excited to connect with more people! Check out our💥𝐕𝐈𝐒𝐂𝐎💥benchmark for VLM self-critique and correction at Poster #396, Friday, 2-4pm. We're also presenting at BEAM workshop on Wednesday: beam-workshop2025.github.io
Can VLMs improve 𝘁𝗵𝗲𝗺𝘀𝗲𝗹𝘃𝗲𝘀💪? We propose🔥𝗩𝗜𝗦𝗖𝗢, a benchmark to evaluate VLMs’ 𝗰𝗿𝗶𝘁𝗶𝗾𝘂𝗲 and 𝗰𝗼𝗿𝗿𝗲𝗰𝘁𝗶𝗼𝗻 capabilities, towards the higher goal of VLMs autonomous self-improvement. 🌐Project: visco-benchmark.github.io 📄Paper: arxiv.org/abs/2412.02172
📢(1/11)Diffusion LMs are fast and controllable at inference time! But why restrict such benefits for processing text data? We are excited to announce LaViDa, one of the first and fastest large diffusion LM for vision-language understanding!!
🌏How culturally safe are large vision-language models? 👉LVLMs often miss the mark. We introduce CROSS, a benchmark of 1,284 image-query pairs across 16 countries & 14 languages, revealing how LVLMs violate cultural norms in context. ⚖️ Evaluation via CROSS-EVAL 🧨 Safety…
🚨 New Blog Drop! 🚀 "Reflection on Knowledge Editing: Charting the Next Steps" is live! 💡 Ever wondered why knowledge editing in LLMs still feels more like a lab experiment than a real-world solution? In this post, we dive deep into where the research is thriving — and where…
Attending NAACL to present BRIEF (Friday 11am, hall 3) and Self-Routing RAG (KnowledgeNLP Workshop). Looking forward to meeting new and old friends!
#GPT4o image generation brings synthetic visual data quality to the next level. 🖼️ 🤔Is synthetic visual data finally ready to be used for improving VLMs? 🚀 We show success with CoDA, using contrastive visual data augmentation to help teach VLMs novel and confusing concepts.
🎮 Computer Use Agent Arena is LIVE! 🚀 🔥 Easiest way to test computer-use agents in the wild without any setup 🌟 Compare top VLMs: OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 vl and more 🕹️ Test agents on 100+ real apps & webs with one-click config 🔒 Safe & free…
🚨 New NLP seminar series alert! 🚨 Check out UCLA NLP Seminar series featuring cutting-edge talks from top researchers in NLP and related areas. Great lineup, timely topics, and open to all (zoom)! 🧠💬 📅 Schedule + details: uclanlp.github.io/nlp-seminar/
Introducing Self-Routing RAG, a framework that equips selective retrieval with the ability to (1) route between multiple knowledge sources and (2) fully leverage the parametric knowledge of the LLM itself. Paper: arxiv.org/abs/2504.01018 (1/N)
📢Scaling test-time compute via generative verification (GenRM) is an emerging paradigm and shown to be more efficient than self-consistency (SC) for reasoning. But, such claims are misleading☠️ Our compute-matched analysis shows that SC outperforms GenRM across most budgets! 🧵
🚀Excited to share our latest work: OpenVLThinker, an exploration into enhancing vision-language models with R1 reasoning capabilities. By iterative integration of SFT and RL, we enabled LVLMs to exhibit robust R1 reasoning behavior. As a result, OpenVLThinker achieves a 70.2%…
Check out our latest work on knowledge editing for multi-hop reasoning! Paper: arxiv.org/pdf/2503.16356 Code: github.com/zjunlp/CaKE
🍰 Introducing CaKE: Circuit-aware Knowledge Editing for LLMs! 🚀 Current knowledge editing methods update single facts but struggle with multi-hop reasoning. We propose CaKE to solve this by aligning edits with the model's reasoning pathways, enabling accurate and consistent…
Video generative models hold the promise of being general-purpose simulators of the physical world 🤖 How far are we from this goal❓ 📢Excited to announce VideoPhy-2, the next edition in the series to test the physical likeness of the generated videos for real-world actions. 🧵
🔍New findings of knowledge overshadowing! Why do LLMs hallucinate over all true training data? 🤔Can we predict hallucinations even before model training or inference? 🚀Check out our new preprint: [arxiv.org/pdf/2502.16143] The Law of Knowledge Overshadowing: Towards…