
Yihe Deng
@Yihe__Deng
CS PhD candidate @UCLA, Student Researcher @GoogleAI | Prev. Research Intern @MSFTResearch @AWS | LLM post-training, synthetic data
🙌 We've released the full version of our paper, OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles Our OpenVLThinker-v1.2 is trained through three lightweight SFT → RL cycles, where SFT first “highlights” reasoning behaviors and RL then explores and…
🤖 I just updated my repository of RL(HF) summary notes to include a growing exploration of new topics, specifically adding notes to projects related to DeepSeek R1 reasoning. Take a look: github.com/yihedeng9/rlhf… 🚀 I’m hoping these summaries are helpful, and I’d love to hear…
😄I did a brief intro of RLHF algorithms for the reading group presentation of our lab. It was a good learning experience for me and I want to share the github repo here holds the slides as well as the list of interesting papers: github.com/yihedeng9/rlhf… Would love to hear about…
🚀 Exciting news! Our Goedel-Prover paper is now live on arXiv: arxiv.org/pdf/2502.07640 🎉 We're currently developing the RL version and have a stronger checkpoint than before (currently not included in the report)!🚀🚀🚀 Plus, we’ll be open-sourcing 1.64M formalized…
(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…
Our paper "Mitigating Object Hallucination in Large Vision-Language Models via Image-Grounded Guidance" will be presented as a spotlight at ICML! I won't make it to Vancouver, but please say hi to my co-author @linxizhao4 there :) arxiv.org/pdf/2402.08680
I’ll be at #ICML2025 in Vancouver this week. Really looking forward to meeting and learning from everyone! I'll be presenting our spotlight paper at 11am on Wed, July 16, in East Exhibition Hall A-B: "Mitigating Object Hallucination in Large Vision-Language Models via…
I’ll be at #ICML2025 in Vancouver this week. Really looking forward to meeting and learning from everyone! I'll be presenting our spotlight paper at 11am on Wed, July 16, in East Exhibition Hall A-B: "Mitigating Object Hallucination in Large Vision-Language Models via…
🚀Excited to share our latest work: LLMs entangle language and knowledge, making it hard to verify or update facts. We introduce LMLM 🐑🧠 — a new class of models that externalize factual knowledge into a database and learn during pretraining when and how to retrieve facts…
Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
🗞️Arxiv: arxiv.org/abs/2503.17352
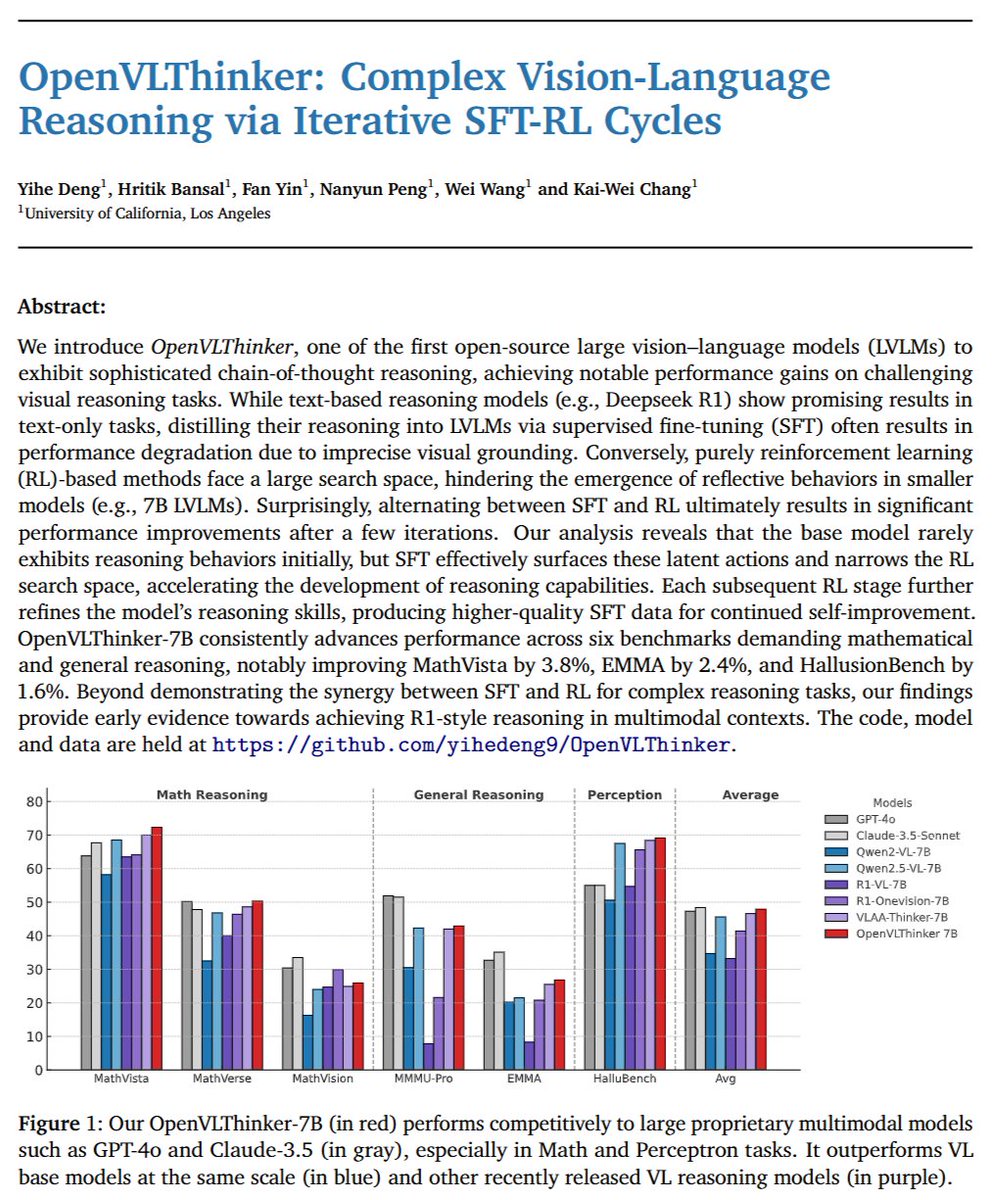
🚀Excited to share our latest work: OpenVLThinker, an exploration into enhancing vision-language models with R1 reasoning capabilities. By iterative integration of SFT and RL, we enabled LVLMs to exhibit robust R1 reasoning behavior. As a result, OpenVLThinker achieves a 70.2%…
We’re rolling out Deep Research to Plus users today! Deep Research was the biggest “Feel The AGI” moment I’ve ever had since ChatGPT. And I’m glad more people will experience their first AGI moment! The team also worked super hard to make more tools including image citations /…
We're also sharing the system card, detailing how we built deep research, assessed its capabilities and risks, and improved safety. openai.com/index/deep-res…
Excited to release PrefEval (ICLR '25 Oral), a benchmark for evaluating LLMs’ ability to infer, memorize, and adhere to user preferences in long-context conversations! ⚠️We find that cutting-edge LLMs struggle to follow user preferences—even in short contexts. This isn't just…
[1/n] SuperExcited to announce SuperGPQA!!! We spend more than half a year to finally make it done! SuperGPQA is a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. It also provides the largest human-LLM…
🌟 Can better cold start strategies improve RL training for LLMs? 🤖 I’ve written a blog that delves into the challenges of fine-tuning LLMs during the cold-start phase and how the strategies applied there can significantly impact RL performance in complex reasoning tasks that…
🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference! Core components of NSA: • Dynamic hierarchical sparse strategy • Coarse-grained token compression • Fine-grained token selection 💡 With…
Introducing #SIRIUS🌟: A self-improving multi-agent LLM framework that learns from successful interactions and refines failed trajectories, enhancing college-level reasoning and competitive negotiations. 📜Preprint: arxiv.org/pdf/2502.04780 💻code: github.com/zou-group/siri… 1/N