
vLLM
@vllm_project
A high-throughput and memory-efficient inference and serving engine for LLMs. Join http://slack.vllm.ai to discuss together with the community!
vLLM is finally addressing a long-standing problem: startup times 35s -> 2s for CUDA graph capture is a great reduction!
✅ Try out @Alibaba_Qwen 3 Coder on vLLM nightly with "qwen3_coder" tool call parser! Additionally, vLLM offers expert parallelism so you can run this model in flexible configurations where it fits.
>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…
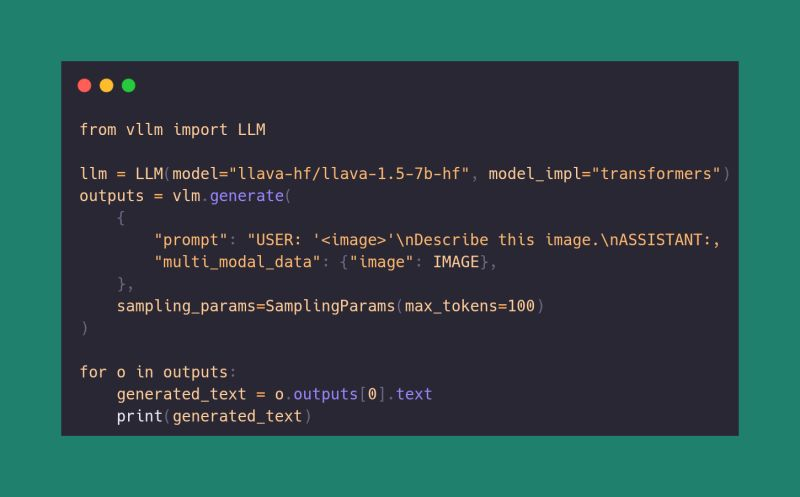
The @huggingface Transformers ↔️ @vllm_project integration just leveled up: Vision-Language Models are now supported out of the box! If the model is integrated into Transformers, you can now run it directly with vLLM. github.com/vllm-project/v… Great work @RTurganbay 👏
If you're building with @vllm_project, speak at the dedicated vLLM track at Ray Summit in November.
Last year, the creators of @vllm_project at UC Berkeley hosted a massive two-day vLLM event featuring presentations from Roblox, Uber, Apple, Intel, Alibaba, Neural Magic, IBM, Handshake, Databricks, Anyscale, and others on how they are using and optimizing vLLM. This covered…
Thanks for the great write-up! 🙌 Prefix caching is critical for agentic workflows like @ManusAI_HQ , and vLLM makes it seamless. ✅ prefix caching is enabled by default with an efficient implementation ✅ Append-only context? Cache hit heaven Context engineering FTW 🚀
After four overhauls and millions of real-world sessions, here are the lessons we learned about context engineering for AI agents: manus.im/blog/Context-E…
🎉Congratulations to @Microsoft for the new Phi-4-mini-flash-reasoning model trained on NVIDIA H100 and A100 GPUs. This latest edition to the Phi family provides developers with a new model optimized for high-throughput and low-latency reasoning in resource-constrained…
We just released native support for @sgl_project and @vllm_project in Inference Endpoints 🔥 Inference Endpoints is becoming the central place where you deploy high performance Inference Engines. And that provides the managed infra for it so you can focus on your users.
Pro-tip for vLLM power-users: free ≈ 90 % of your GPU VRAM in seconds—no restarts required🚀 🚩 Why you’ll want this • Hot-swap new checkpoints on the same card • Rotate multiple LLMs on one GPU (batch jobs, micro-services, A/B tests) • Stage-based pipelines that call…
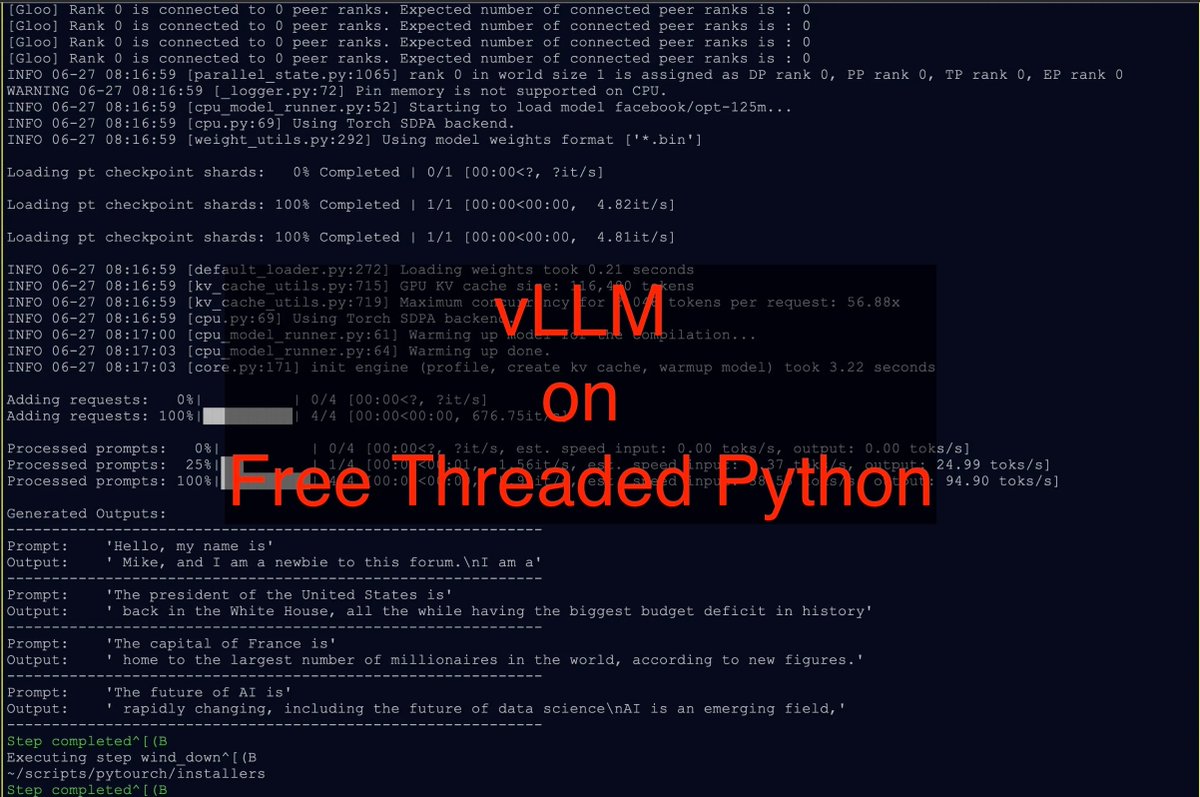
vLLM runs on free-threaded Python! A group of engineers from @Meta’s Python runtime language team has shown that it’s possible to run vLLM on the nogil distribution of Python. We’re incredibly excited to embrace this future technique and be early adopters 😍
We hear your voice! For minimax in particular, github.com/vllm-project/v… forces the lm head to be fp32, which resumes accuracy but takes a lot memory. We are experimenting to see if dynamically casting fp16/bf16 to fp32 in the kernel helps the accuracy of the logits.
horrifying bug of the day is finding out the vllm and huggingface produce significantly different logprobs discuss.vllm.ai/t/numerical-di…
🚨 MiniMax-M1 Technical Seminar Join us for our first official seminar — a deep dive into the world’s first open-weight hybrid-attention reasoning model, with 1M-token input & 80K-token output. 🧠 Experts from MiniMax, Anthropic, Hugging Face, vLLM, MIT, HKUST & more 📅 July 10…
💎What makes @vllm_project the Rolls Royce of inference? 👇🏻 We break it down in 5 performance-packed layers😎 ✅ PagedAttention, Prefix Caching, Chunked Prefill ✅ Continuous Batching, Speculative Decoding ✅ Flash Attention, FlashInfer ✅ Tensor/data & Pipeline Parallelism
🚀#NewBlog @vllm_project 🔥 𝐯𝐋𝐋𝐌 𝐟𝐨𝐫 𝐁𝐞𝐠𝐢𝐧𝐧𝐞𝐫𝐬 𝐏𝐚𝐫𝐭 𝟐:📖𝐊𝐞𝐲 𝐅𝐞𝐚𝐭𝐮𝐫𝐞𝐬 & 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧s💫 💎 What makes #vLLM the Rolls Royce of inference? 👉check it out: cloudthrill.ca/what-is-vllm-f… @vllm_project @lmcache #LLMPerformance
Minimax M1 is one of the SOTA open weight model from @MiniMax__AI. Checkout how is it efficiently implemented in vLLM, directly from the team! blog.vllm.ai/2025/06/30/min…
🔥 Another strong open model with Apache 2.0 license, this one from @MiniMax_AI - places in the top 15. MiniMax-M1 is now live on the Text Arena leaderboard landing at #12. This puts it at equal ranking with Deepseek V3/R1 and Qwen 3! See thread to learn more about its…
"The second most intelligent open weights model after DeepSeek R1, with a much longer 1M token context window!" Checkout the blog post from @MiniMax__AI on how the model is implemented on vLLM, and how you can run this model efficiently! blog.vllm.ai/2025/06/30/min…
MiniMax launches their first reasoning model: MiniMax M1, the second most intelligent open weights model after DeepSeek R1, with a much longer 1M token context window @MiniMax__AI M1 is based on their Text-01 model (released 14 Jan 2025) - an MoE with 456B total and 45.9B active…
PyTorch and vLLM are both critical to the AI ecosystem and are increasingly being used together for cutting edge generative AI applications, including inference, post-training, and agentic systems at scale. 🔗 Learn more about PyTorch → vLLM integrations and what’s to come:…