
NVIDIA AI Developer
@NVIDIAAIDev
All things AI for developers from @NVIDIA. Additional developer channels: @NVIDIADeveloper, @NVIDIAHPCDev, and @NVIDIAGameDev.
💡 Build a serverless distributed NVIDIA GPU-accelerated Apache Spark application on #MicrosoftAzure that’s efficient, scalable and meets the demands of your AI workloads. 🔎 See how in our step-by-step guide: nvda.ws/4lJJjqo
Join us at @CrusoeAI HQ tonight. Details below 👇 to request your spot.
Join Crusoe and @NVIDIA for an exclusive AI happy hour + tech talk in San Francisco! ⚡️ We're diving deep into the future of the AI cloud and how the NVIDIA AI platform is accelerating the path to value for developers + data scientists. ⌚️ When: Wednesday, 7/23 | 4:30 p.m. -…
Nvidia presents ThinkAct Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Top-Ranked RAG: NeMo Retriever Leads Visual Document Retrieval Leaderboards x.com/i/broadcasts/1…
In 2016, Jensen Huang hand-delivered the world’s first AI supercomputer to a startup in San Francisco called @OpenAI. The culmination of a decade of work from thousands of NVIDIA engineers, DGX-1 set the stage for a new industrial revolution.
🚒 Toxic plumes from industrial accidents, wildfires, and chemical spills spread hazardous materials through urban environments, posing immediate risks to public health and safety. Existing prediction models are too slow for real-time emergency response. (tag) Lawrence…

DeepSeek R1 performance optimization to push the throughput performance boundary x.com/i/broadcasts/1…
🔋Ready to safeguard your #agenticAI systems? 🔍Discover how the safety recipe for agentic AI provides a structured reference designed to evaluate and align open models early, enabling increased #AIsafety, #AIsecurity, and compliant agentic workflows. Technical blog ➡️…
Boost your LLM apps 💡 The NVIDIA AI Blueprint for Enterprise RAG pipelines delivers accurate, context-aware responses. Our walk-through launchable makes deployment easy. Get started 👉 nvda.ws/3GNhCxF
Nvidia is killing it these days and sharing in the open for everyone's benefit! Currently second big organization on HF by number of repos created in the past 12 months (average a new repo every day) and crossed 30,000 followers (second in the US just after Meta).…
Wait NVIDIA has just released new SOTA open source models?! Available in 4 sizes 1.5B, 7B, 14B and 32B that you can run 100% locally. - OpenReasoning-Nemotron - SOTA scores across many benchmarks - Tailored for math, science, code How to run it on your laptop and details below
Learn how we pushed the boundary to get the world's fastest GPU inference on DeepSeek R1 based on #NVIDIABlackwell architecture. Join our livestream on YouTube tomorrow ➡️ nvda.ws/3GzMzFy 📆 July 22, 5-6 p.m. (PDT)
What's the difference between #RAG and agentic RAG? 💡 RAG is a technique where an #AI model retrieves information from a knowledge base before generating its response. Agentic RAG is more dynamic and works well for asynchronous tasks including research, summarization, and code…
⚡Running LLM inference in production? Experiencing latency bottlenecks in the decode stage? We’re sharing techniques to reduce communication overhead for small message sizes during decode, especially when compute and comms can’t overlap. ➡️ nvda.ws/46gxset Learn how…

👀Accelerating your pandas code is now a no-code or low-code task. Dive into 3 ways to accelerate pandas across multiple coding environments. 00:30 - Method 1 - magic command 03:55 - Method 2 - cuDF module 07:27 - Method 3 - cuDF code
🎉 @Kimi_Moonshot recently released Kimi K2 — a 1T-parameter #opensource MoE LLM (32B active) achieving SOTA perf in frontier knowledge, math, and coding among non-thinking models. ⚡Powered by the Muon optimizer at unprecedented scale 🏎️ With over a trillion parameters and 2M…
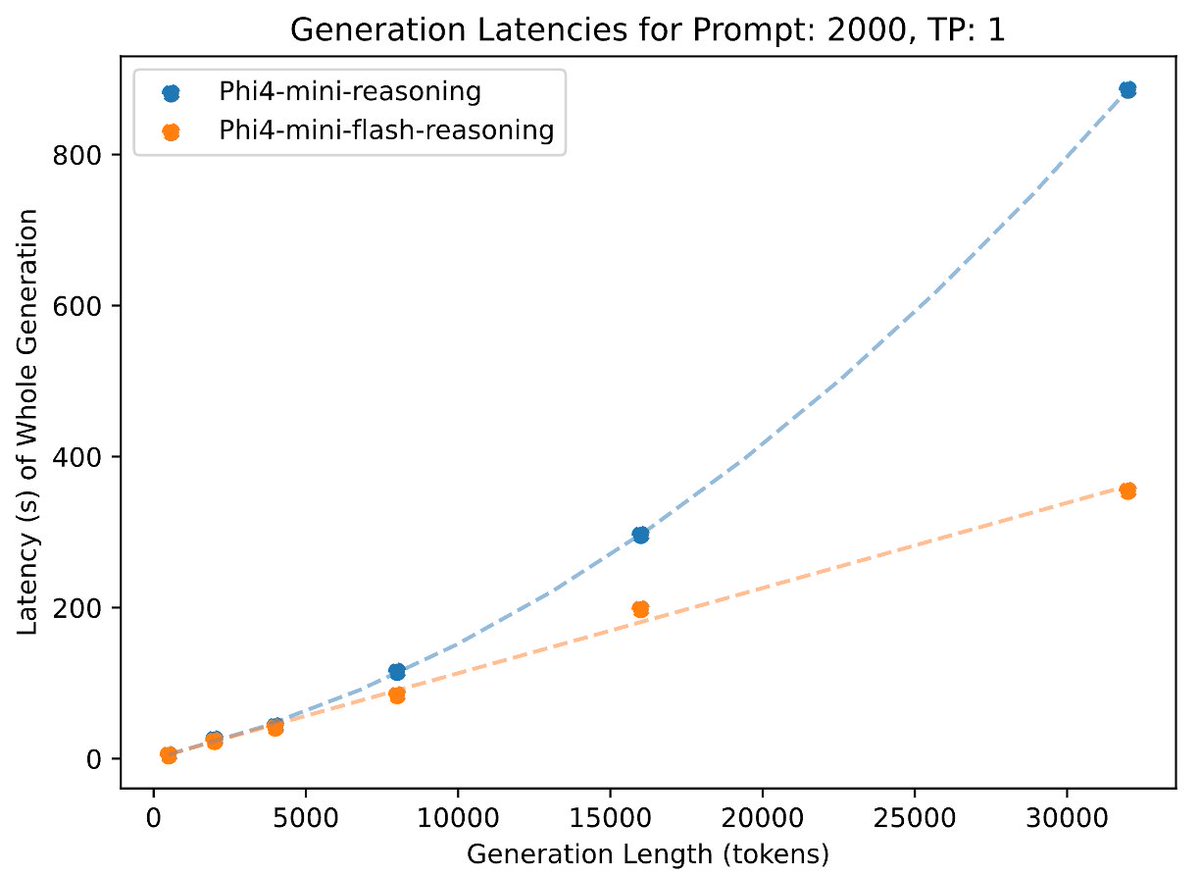
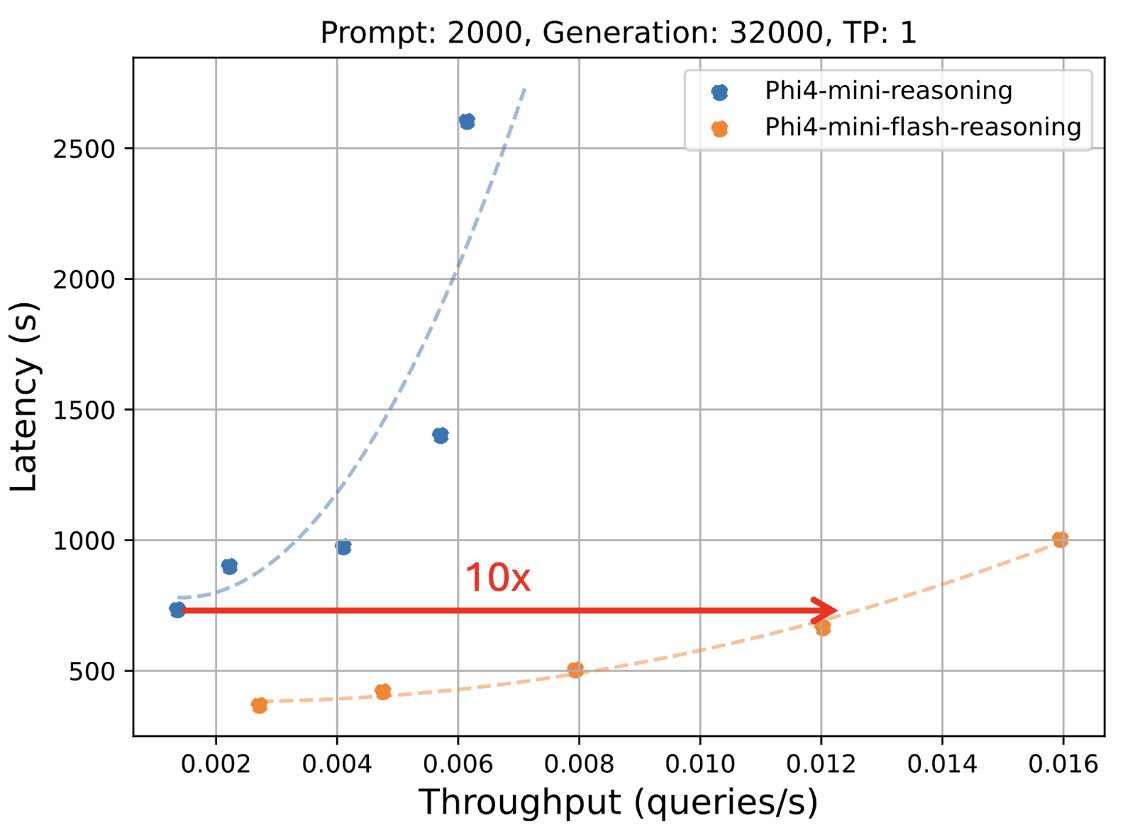
🎉Congratulations to @Microsoft for the new Phi-4-mini-flash-reasoning model trained on NVIDIA H100 and A100 GPUs. This latest edition to the Phi family provides developers with a new model optimized for high-throughput and low-latency reasoning in resource-constrained…
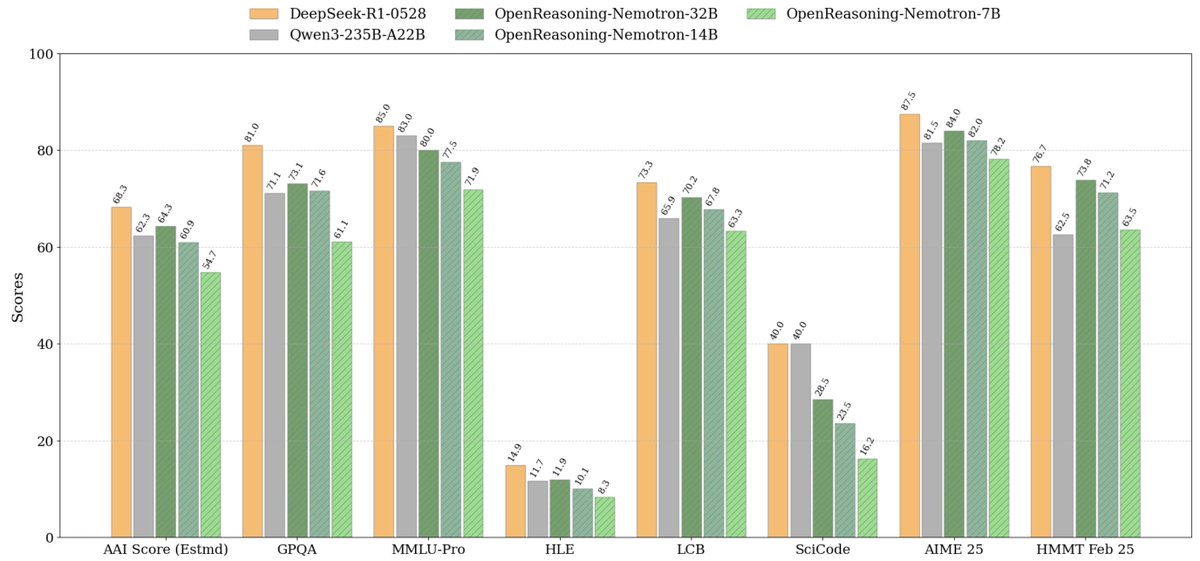
📣 Announcing the release of OpenReasoning-Nemotron: a suite of reasoning-capable LLMs which have been distilled from the DeepSeek R1 0528 671B model. Trained on a massive, high-quality dataset distilled from the new DeepSeek R1 0528, our new 7B, 14B, and 32B models achieve SOTA…
🎶 Meet Audio-Flamingo 3 – a fully open LALM trained on sound, speech, and music datasets. 🎶 Handles 10-min audio, long-form text, and voice conversations. Perfect for audio QA, dialog, and reasoning. On @huggingface ➡️ huggingface.co/nvidia/audio-f… From #NVIDIAResearch.