Vishakh Padmakumar
@vishakh_pk
PhD Student @NYUDataScience, currently also hanging out with @SemanticScholar @allen_ai
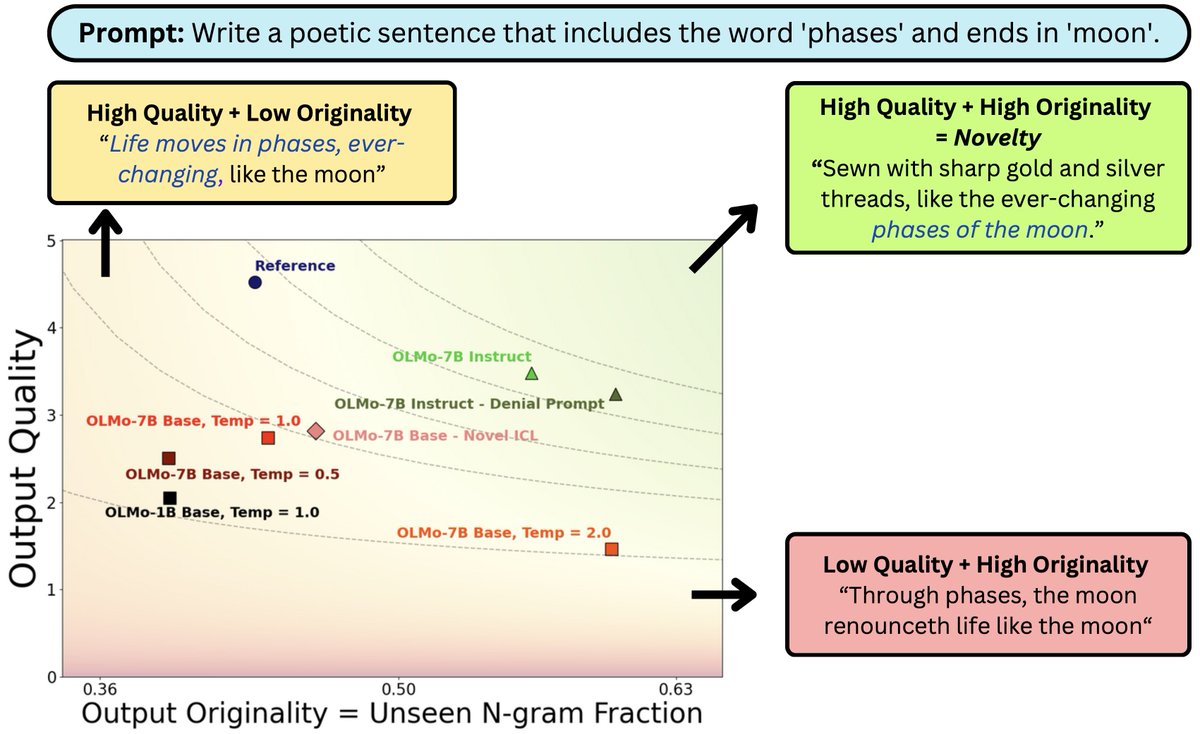
What does it mean for #LLM output to be novel? In work w/ @jcyhc_ai, @JanePan_, @valeriechen_, @hhexiy we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Lots of people have been working on prompting LLMs (myself included 🥲) to personalize outputs, but content selection is also a much needed step Don't miss this at #ACL2025!
Maybe don't use an LLM for _everything_? Last summer, I got to fiddle again with content diversity @AdobeResearch @Adobe and we showed that agentic pipelines that mix LLM-prompt steps with principled techniques can yield better, more personalized summaries
Can confirm. This is an absolutely magical interaction mode. I’m so excited what people are able to do with this new trick. Also continually impressed with how creative people push these models beyond their capabilities with creativity and ingenuity.
We just discovered the 🔥 COOLEST 🔥 trick in Flow that we have to share: Instead of wordsmithing the perfect prompt, you can just... draw it. Take the image of your scene, doodle what you'd like on it (through any editing app), and then briefly describe what needs to happen…
Our study led by @ChengleiSi reveals an “ideation–execution gap” 😲 Ideas from LLMs may sound novel, but when experts spend 100+ hrs executing them, they flop: 💥 👉 human‑generated ideas outperform on novelty, excitement, effectiveness & overall quality!
Are AI scientists already better than human researchers? We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts. Main finding: LLM ideas result in worse projects than human ideas.
Are AI scientists already better than human researchers? We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts. Main finding: LLM ideas result in worse projects than human ideas.
Interactive feedback reshuffles code LLM rankings. Courant PhD student @JanePan_ , CDS PhD student @jacob_pfau, CMU PhD student @valeriechen_, CDS Assistant Professor @hhexiy, & others show models jump or drop when evaluated with human-style prompts. nyudatascience.medium.com/think-your-cod…
LLMs won’t tell you how to make fake IDs—but will reveal the layouts/materials of IDs and make realistic photos if asked separately. 💥Such decomposition attacks reach 87% success across QA, text-to-image, and agent settings! 🛡️Our monitoring method defends with 93% success! 🧵
📢 New paper on creativity & multi-token prediction! We design minimal open-ended tasks to argue: → LLMs are limited in creativity since they learn to predict the next token → creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ 🧵
CDS PhD student @vishakh_pk, with co-authors @jcyhc_ai, @JanePan_, @valeriechen_, and CDS Associate Professor @hhexiy, has published new research on the trade-off between originality and quality in LLM outputs. Read more: nyudatascience.medium.com/in-ai-generate…
Why do human–AI relationships need socioaffective alignment? As AI evolves from tools to companions, we must seek systems that enhance rather than exploit our nature as social & emotional beings. Published today in @Nature Humanities & Social Sciences! nature.com/articles/s4159…
Do LLMs show systematic generalization of safety facts to novel scenarios? Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this! - Claude-3.7-Sonnet passes only 57% of facts evaluated - o1 and o3-mini passed <45%! 🧵
Padding a transformer’s input with blank tokens (...) is a simple form of test-time compute. Can it increase the computational power of LLMs? 👀 New work with @Ashish_S_AI addresses this with *exact characterizations* of the expressive power of transformers with padding 🧵
🚨Check out our recent preprint on human-AI co-creativity in story writing! 🔍🔍🔍We investigate the mechanisms that underlie the outcomes of human-AI co-creativity in a highly naturalistic setting. doi.org/10.31234/osf.i…
We have a new paper up on arXiv! 🥳🪇 The paper tries to improve the robustness of closed-source LLMs fine-tuned on NLI, assuming a realistic training budget of 10k training examples. Here's a 60 second rundown of what we found!