Siyuan Huang
@siyuanhuang95
Research Scientist at BIGAI Working on #3d_scene_understanding and #embodied_ai Ph.D. in Statistics from @UCLA Former intern at @DeepMind and @MetaAI
🤖 Ever dreamed of controlling a humanoid robot to perform complex, long-horizon tasks — using just a single Vision Pro? 🎉 Meet CLONE: a holistic, closed-loop, whole-body teleoperation system for long-horizon humanoid control! 🏃♂️🧍 CLONE enables rich and coordinated…
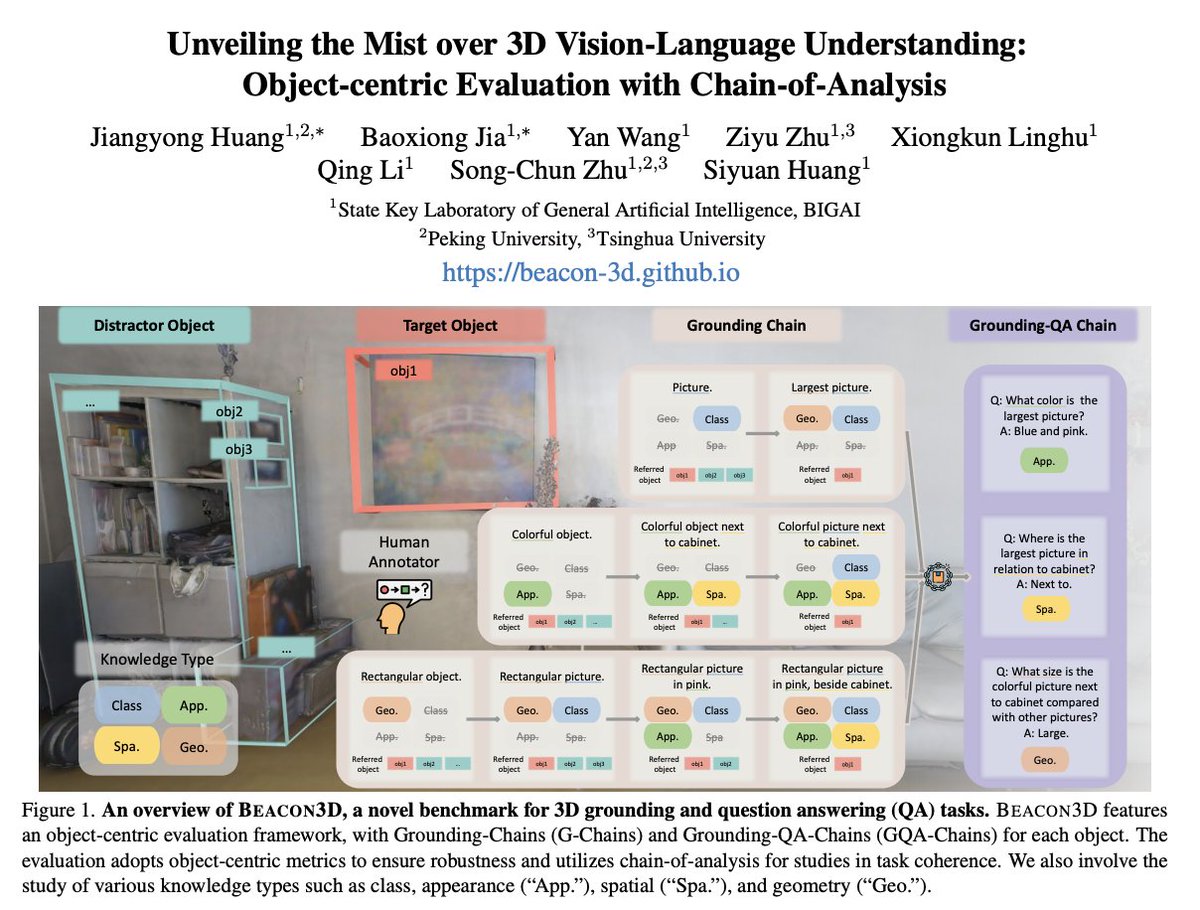
Are we on the right path in developing 3D Large Language Models (3D-LLMs)? 🤖🌍 At the 3D-LLM/VLA Workshop, I presented our recent work Beacon3D, which aims to clear the mist surrounding current 3D Vision-Language tasks and models. 🧭✨ 🔗 Project: beacon-3d.github.io 📑…

RoboVerse officially on arxiv, we are updating and improving it everyday!
🚀 RoboVerse has been accepted to RSS 2025 and is now live on arXiv: arxiv.org/abs/2504.18904 ✨ Also be selected in HuggingFace Daily: huggingface.co/papers/2504.18… 🛠️ Explore our open-source repo: github.com/RoboVerseOrg/R… We're actively developing and adding new features daily — come…
Really fluid demos! Active vision, high-res touch, and high-DoF robot hands, that's what we need for future dexterous manipulation models!
🤖 What if a humanoid robot could make a hamburger from raw ingredients—all the way to your plate? 🔥 Excited to announce ViTacFormer: our new pipeline for next-level dexterous manipulation with active vision + high-resolution touch. 🎯 For the first time ever, we demonstrate…
Training a large-scale VLA demands huge computing resource, efficient post-training is a more convenient way for various applications. This is also a collaboration with @Astribot_Inc, the S1 robot super smooth and provides efficient teleoperation system for demonstration…
combining object-centric skill representations with large-scale VLA pretraining to make a model which can be taught a new task with only 10-20 examples. making robot skills object centric makes the generalization problem much more tractable with less data because most of what a…
🤖 Ever wished robots could learn new manipulation tasks with just a few demos — and still generalize? 🔥 Introducing **ControlVLA**: Few-shot Object-centric Adaptation for Pre-trained Vision-Language-Action Models. 🦾🎯 From opening cabinets to folding clothes, pouring cubes,…
Amazing progress, really impressive!
Today we're excited to share a glimpse of what we're building at Generalist. As a first step towards our mission of making general-purpose robots a reality, we're pushing the frontiers of what end-to-end AI models can achieve in the real world. Here's a preview of our early…
Great work by Tianmin’s team, tried the demo, it works perfectly, congrats!
🚀 Excited to introduce SimWorld: an embodied simulator for infinite photorealistic world generation 🏙️ populated with diverse agents 🤖 If you are at #CVPR2025, come check out the live demo 👇 Jun 14, 12:00-1:00 pm at JHU booth, ExHall B Jun 15, 10:30 am-12:30 pm, #7, ExHall B
This year at CVPR, our group (with @BaoxiongJ and @_yixinchen ) will host the 3D scene understanding workshop and will present nine papers! I will give two keynote talks at (1) 3D LLM/VLA and (2) Agents in Interaction workshop. Excited to meet old and new friends, and DM is…


‘CLONE’ – whole-body teleoperation of a humanoid. Intuitive control signals are captured by tracking the teleoperator’s head and hand poses using Apple Vision Pro. A Mixture-of-Experts policy takes the sparse input and synthesizes the corresponding whole-body humanoid pose.
Another huge week of AI and robotics news. So, I summarized everything from OpenAI, Microsoft, Google, Figure, Unitree, BIGAI, UCR Robotics, Agility Robotics, Agibot, and more. Here's everything you need to know and how to make sense out of it:
#CVPR2025 is just around the corner!🔥🔥 Join us for the exciting roster of distinguished speakers at the 5th Workshop on 3D Scene Understanding for Vision, Graphics, and Robotics. #3DSUN Mark: June 11th, starting from 8:45 AM in Room 106C! @CVPR scene-understanding.com
Really impressive work on CLONE — the demo shows strong progress in bringing long-horizon humanoid control into an intuitive VR interface. The level of responsiveness and task diversity is a huge step forward 👏 Some thoughts we’d love to add to the conversation: 1.…
🤖 Ever dreamed of controlling a humanoid robot to perform complex, long-horizon tasks — using just a single Vision Pro? 🎉 Meet CLONE: a holistic, closed-loop, whole-body teleoperation system for long-horizon humanoid control! 🏃♂️🧍 CLONE enables rich and coordinated…
Control a full-body humanoid robot with nothing… but a Vision Pro. [📍 Bookmark github for later] A complete whole-body teleoperation system for humanoids… no fancy setup needed, just an MR headset and their new closed-loop pipeline. Unlike most teleop systems, CLONE works…
🎤 Excited to share UniFP, a method for unified force and position control for legged locomotion! 🤖 UniFP provides a unified interface for position control, force control, force tracking, and impedance control, addressing the limitations of current legged robots. The video…
Check out the interview about RoboVerse with Haoran!
I'm kicking off a new series of podcasts 🎙️ called "Robot Mind," where I talk to top minds in Physical AI and Robotics about the recent progress and the future of physical AI. In Episode 1, I’m joined by Haoran Geng (BAIR, UC Berkeley) @HaoranGeng2, first author of ROBOVERSE — a…
So real 😂
There are some people who, I swear, if they saw an electric light bulb for the first time they'd be all "its so impractical and expensive, who even has a generator? We should just use cheap, renewable whale oil"
This is so cool! Open-world generalization is what we need.
We got a robot to clean up homes that were never seen in its training data! Our new model, π-0.5, aims to tackle open-world generalization. We took our robot into homes that were not in the training data and asked it to clean kitchens and bedrooms. More below⤵️