
Shoubin Yu
@shoubin621
Ph.D. Student at @unccs @uncnlp, advised by @mohitban47. Interested in multimodal AI.
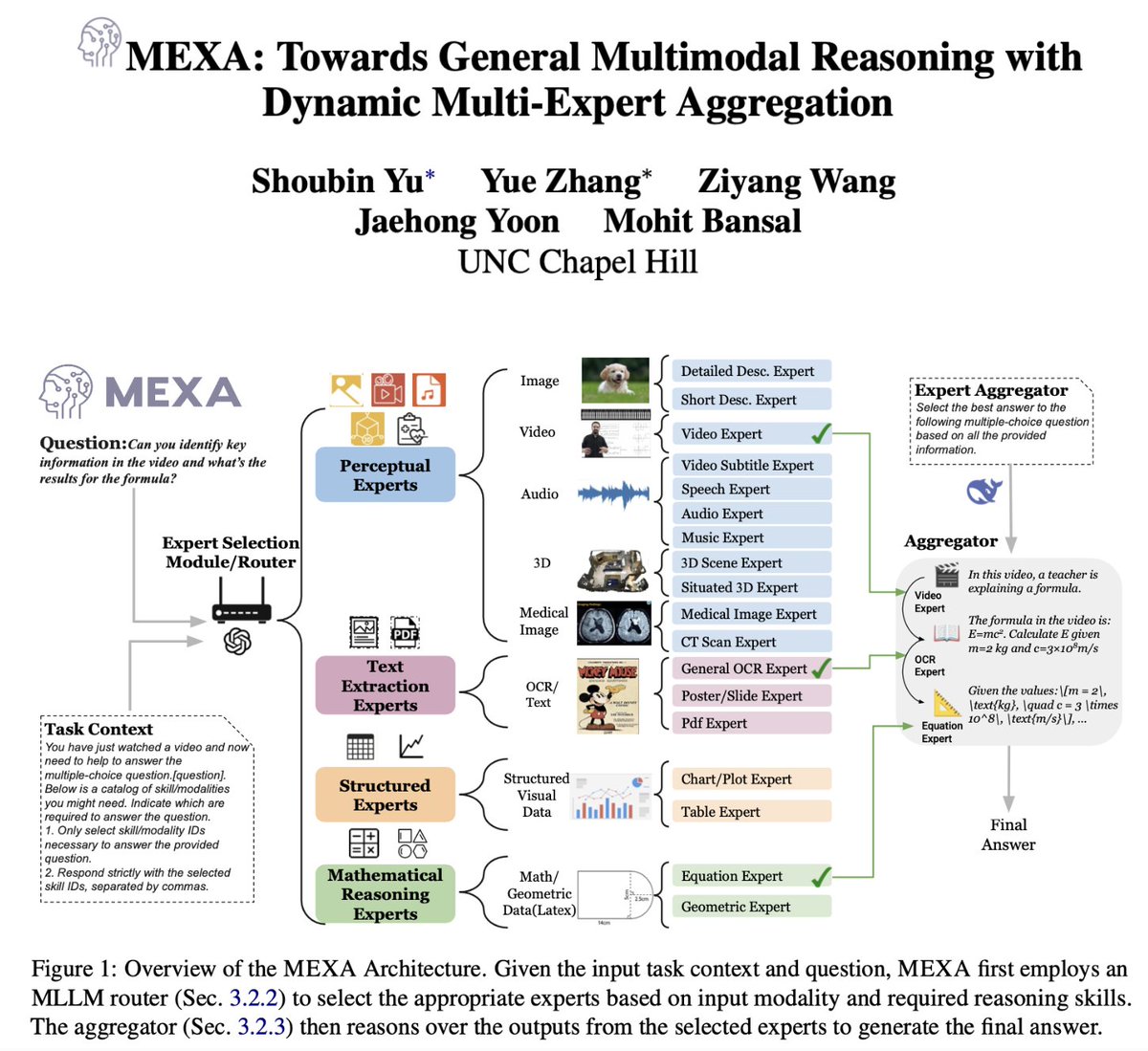
New paper Alert 🚨 Introducing MEXA: A general and training-free multimodal reasoning framework via dynamic multi-expert skill selection, aggregation and deep reasoning! MEXA: 1. Selects task- and modality-relevant experts based on the query and various required multimodal…
Excited to share GenerationPrograms! 🚀 How do we get LLMs to cite their sources? GenerationPrograms is attributable by design, producing a program that executes text w/ a trace of how the text was generated! Gains of up to +39 Attribution F1 and eliminates uncited sentences,…
GLIMPSE 👁️ | What Do LVLMs Really See in Videos? A new benchmark for video understanding: 3,269 videos and 4,342 vision-centric questions across 11 spatiotemporal reasoning tasks. Test your model to see if it truly thinks with video—or is merely performing frame scanning.
Checkout our new paper: Video-RTS 🎥 A data-efficient RL method for complex video reasoning tasks. 🔹 Pure RL w/ output-based rewards. 🔹 Novel sparse-to-dense Test-Time Scaling (TTS) to expand input frames via self-consistency. 💥 96.4% less training data! More in the thread👇
🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! While RL-based video reasoning with LLMs has advanced, the reliance on large-scale SFT with extensive video data and long CoT annotations remains a major bottleneck. Video-RTS tackles…
Overdue job update -- I am now: - A Visiting Scientist at @schmidtsciences, supporting AI safety and interpretability - A Visiting Researcher at the Stanford NLP Group, working with @ChrisGPotts I am so grateful I get to keep working in this fascinating and essential area, and…
🚨 Check our new paper, Video-RTS, a novel and data-efficient RL solution for complex video reasoning tasks, complete with video-adaptive Test-Time Scaling (TTS). 1⃣️Traditionally, such tasks have relied on massive SFT datasets. Video-RTS bypasses this by employing pure RL with…
🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! While RL-based video reasoning with LLMs has advanced, the reliance on large-scale SFT with extensive video data and long CoT annotations remains a major bottleneck. Video-RTS tackles…
🚀 Check out our new paper Video-RTS — a data-efficient RL approach for video reasoning with video-adaptive TTS! While prior work relies on massive SFT (400K+ VQA and/or CoT samples 🤯), Video-RTS: ▶️ Replaces expensive SFT with pure RL using output-based rewards ▶️ Introduces a…
🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! While RL-based video reasoning with LLMs has advanced, the reliance on large-scale SFT with extensive video data and long CoT annotations remains a major bottleneck. Video-RTS tackles…
Video-RTS Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning
Don't miss this amazing workshop if you are also working on spatial intelligence 👇
📣 Excited to announce SpaVLE: #NeurIPS2025 Workshop on Space in Vision, Language, and Embodied AI! 👉 …vision-language-embodied-ai.github.io 🦾Co-organized with an incredible team → @fredahshi · @maojiayuan · @DJiafei · @ManlingLi_ · David Hsu · @Kordjamshidi 🌌 Why Space & SpaVLE? We…
📣 Excited to announce SpaVLE: #NeurIPS2025 Workshop on Space in Vision, Language, and Embodied AI! 👉 …vision-language-embodied-ai.github.io 🦾Co-organized with an incredible team → @fredahshi · @maojiayuan · @DJiafei · @ManlingLi_ · David Hsu · @Kordjamshidi 🌌 Why Space & SpaVLE? We…
🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! While RL-based video reasoning with LLMs has advanced, the reliance on large-scale SFT with extensive video data and long CoT annotations remains a major bottleneck. Video-RTS tackles…
🎉 Excited to share that TaCQ (Task-Circuit Quantization), our work on knowledge-informed mixed-precision quantization, has been accepted to #COLM2025 @COLM_conf! Happy to see that TaCQ was recognized with high scores and a nice shoutout from the AC – big thanks to @EliasEskin…
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)…
🥳Our work UTGen & UTDebug on teaching LLMs to generate effective unit tests & improve code debugging/generation has been accepted to @COLM_conf #COLM2025! Stay tuned for more exciting results -- e.g., using 32B-scale UTGen models to improve debugging with frontier models like…
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨 which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests. UTGen+UTDebug improve LLM-based code debugging by addressing 3 key…
How can we unlock generalized reasoning? ⚡️Introducing Energy-Based Transformers (EBTs), an approach that out-scales (feed-forward) transformers and unlocks generalized reasoning/thinking on any modality/problem without rewards. TLDR: - EBTs are the first model to outscale the…
🥳Excited to share that I’ll be joining @unccs as postdoc this fall. Looking forward to work with @mohitban47 & amazing students at @unc_ai_group. I'll continue working on retrieval, aligning knowledge modules with LLM's parametric knowledge, and expanding to various modalities.
🧠 How can AI evolve from statically 𝘵𝘩𝘪𝘯𝘬𝘪𝘯𝘨 𝘢𝘣𝘰𝘶𝘵 𝘪𝘮𝘢𝘨𝘦𝘴 → dynamically 𝘵𝘩𝘪𝘯𝘬𝘪𝘯𝘨 𝘸𝘪𝘵𝘩 𝘪𝘮𝘢𝘨𝘦𝘴 as cognitive workspaces, similar to the human mental sketchpad? 🔍 What’s the 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗿𝗼𝗮𝗱𝗺𝗮𝗽 from tool-use → programmatic…
Bytedance presents EX-4D EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
🎉 Yay, welcome to the @unc @unccs @unc_ai_group family and beautiful Research Triangle area, Jason! Looking forward to the many exciting collaborations on these topics! 🔥 PS. If you are applying for fall2026 PhD admissions, make sure to apply to new faculty member Jason 👇
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨 which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests. UTGen+UTDebug improve LLM-based code debugging by addressing 3 key…
Excited to share our new work, SAME: Learning Generic Language-Guided Visual Navigation with State-Adaptive Mixture of Experts, has been accepted to #ICCV2025! 🌐 One model, ✨ 7 navigation tasks, 🔀 any granularity language understanding. 📄 arxiv.org/pdf/2412.05552 🧵👇
📢Accepted by #ICCV! Check out our new paper, SAME: a State-Adaptive Mixture of Experts for unified language-guided visual navigation. Key highlights: 1️⃣ Unifies diverse navigation tasks (fine/coarse/zero-grained) in a single versatile agent. 2️⃣ Dynamically routes expert…
Excited to share our new work, SAME: Learning Generic Language-Guided Visual Navigation with State-Adaptive Mixture of Experts, has been accepted to #ICCV2025! 🌐 One model, ✨ 7 navigation tasks, 🔀 any granularity language understanding. 📄 arxiv.org/pdf/2412.05552 🧵👇