Ruoxi Jia
@ruoxijia
Assistant Professor at VT ECE, PhD at Berkeley EECS, researcher in responsible AI, proud mom of two
🚀 Exciting Announcement! 🚀 Get ready for the 18th ACM Workshop on Artificial Intelligence and Security (AISec 2025)! 📍Co-located: @acm_ccs 🗓️ Deadline: June 20th, 2025 🌐 Website: aisec.cc w/ @ruoxijia and Matthew Jagielski
Check out our new #ICML2025 paper on a lightweight method for mitigating over-refusal! This work is led by my amazing student Mahavir, and it's his first ICML publication. Thrilled to see his research career take off!
🎉 Thrilled to be presenting my first paper at @icmlconf! "Just Enough Shifts: Mitigating Over-Refusal in Aligned Language Models with Targeted Representation Fine-Tuning" We introduce ACTOR—a lightweight, activation-based training method that reduces over-refusal without…
LMArena is widely used for model evaluation, but is it measuring true progress? 🔮 In our work, "The Leaderboard Illusion", we reveal: 🔒 Private testing 📊 Data access asymmetries ⚠️ Overfitting risks 🚫 Silent deprecations Despite best intentions, arena policies favor a few!
It was challenging to organize the workshop as the sole in-person organizer, and I’m deeply grateful to everyone for their incredible support in making it a great success. @danqi_chen @PeterHndrsn @kylelostat @mirrokni @bryanklow @hmgxr128 @brandontrabucco Zheng Xu, Edward Yeo,…
Join us at @iclr_conf on Monday (4/28) in Hall 4 #4 for a full-day workshop on data problems for foundation models! We'll explore research frontiers in understanding and optimizing data across all aspects of foundation model development. Schedule: datafm.github.io We…
Congrats @dawnsongtweets you are the inspiration to many of us!
Deeply humbled and honored to be elected to the American Academy of Arts and Sciences @americanacad! Excited to contribute to the Academy’s mission and advancing the common good! amacad.org/new-members-20…
Delighted to share that two papers from our group @EPrinceton got recognized by the @iclr_conf award committee. Our paper, "Safety Alignment Should be Made More Than Just a Few Tokens Deep", received the ICLR 2025 Outstanding Paper Award. This paper showcases that many AI…
Outstanding Papers Safety Alignment Should be Made More Than Just a Few Tokens Deep. Xiangyu Qi, et al. Learning Dynamics of LLM Finetuning. Yi Ren and Danica J. Sutherland. AlphaEdit: Null-Space Constrained Model Editing for Language Models. Junfeng Fang, et al.
Thrilled to receive ICLR'25 Outstanding Paper Honorable Mention! Heartfelt thanks to my incredible mentors @ruoxijia @dawnsongtweets @prateekmittal_ @james_y_zou. I'll be giving two oral presentations on our recent work in training data attribution & co-organizing a workshop on…
If you are attending ICLR, check out Yi’s work that presents a systematic way of understanding AI safety risks as well as a policy-grounded benchmark!
AIR-Bench is a Spotlight @iclr_conf 2025! Catch our poster on Fri, Apr 26, 10 a.m.–12:30 p.m. SGT (Poster Session 5). Sadly, I won’t be there in person (visa woes, again), but the insights—and our incredible team—will be with you in Singapore. Go say hi 👋
Ph.D. student @EasonZeng623 looks at new way of jailbreaking LLMs -- treating them as human-like communicators to examine the interplay between everyday language interaction and AI safety. #VTInnovationCampus opening he discussed his work @SanghaniCtrVT. tinyurl.com/4ma7725v
Excited to announce the ICLR 2025 Workshop on Data Problems for Foundation Models (DATA-FM)! We welcome submissions exploring all aspects of data in foundation model research, including but not limited to data curation, attribution, copyright, synthetic data, benchmark, societal…
Submission deadline AoE today for our Workshop on Data Problems for Foundation Models! Look forward to your contributions!
Announcing the ICLR 2025 Workshop on Data Problems for Foundation Models (DATA-FM)! We welcome submissions exploring ALL ASPECTS OF DATA in foundation model research. Submission deadline: Feb 7th (this Friday!) 11:59pm AoE datafm.github.io
I will be presenting our NeurIPS spotlight work on gradient-based online data selection for LLMs today (12/12) at 4:30-7:30pm PST (East Hall #4400). Big thanks to my amazing collaborators @ruoxijia @TongWu_Pton @dawnsongtweets @prateekmittal_ Please feel free to come by and…
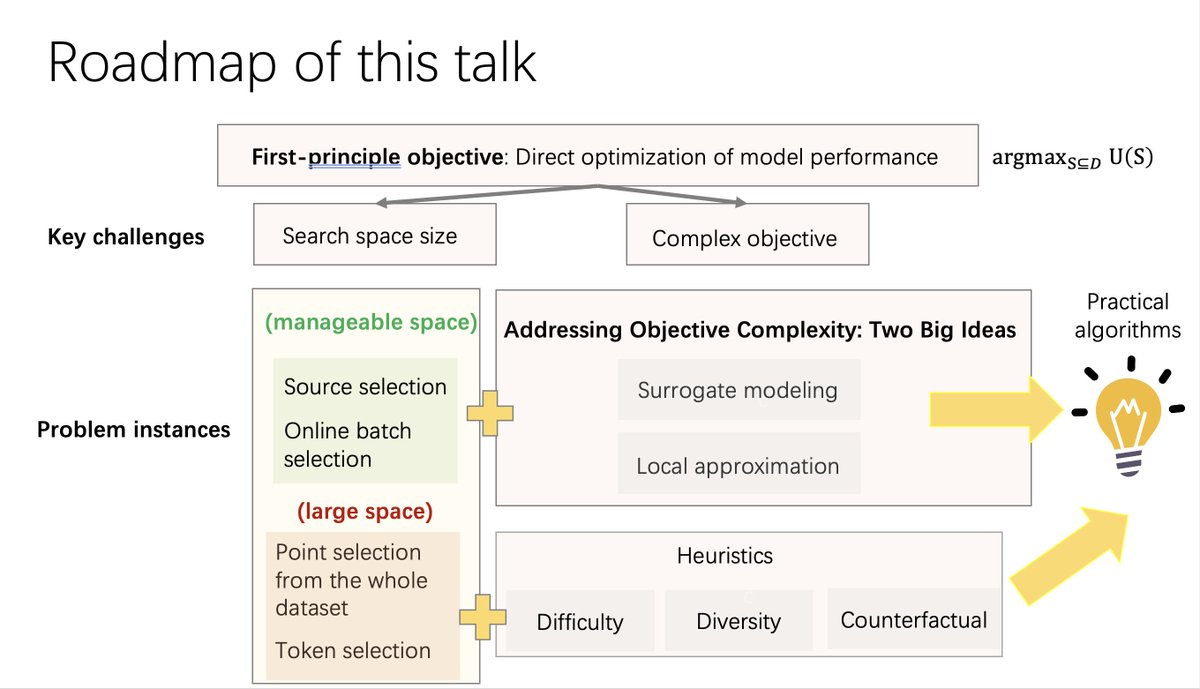
Here are all three parts of the slides for "Advancing Data Selection for Foundation Models: From Heuristics to Principled Methods" tutorial at NeurIPS yesterday! Part 1 (Intro + Empirical Methods): tinyurl.com/yc5bhfbn Part 2 (Principled Methods): tinyurl.com/3mzbue3j…
Here’s my slide deck from the tutorial. Thanks to everyone who attended yesterday - it was a super rewarding process to prepare for this! tinyurl.com/5b524eaz
Here’s my slide deck from the tutorial. Thanks to everyone who attended yesterday - it was a super rewarding process to prepare for this! tinyurl.com/5b524eaz
Join us Tuesday at 1:30 PM PT at #NeurIPS2024 for our tutorial on data selection for foundation models! With @lschmidt3 & @JiachenWang97, we'll cover principled experimentation, selection algorithms, a unified theoretical framework, and open challenges. Hope to see you there!
Excited to attend #NeurIPS2024 in Vancouver 🇨🇦! I will be presenting our work: "Boosting Alignment for Post-Unlearning Text-to-Image Generative Models." If you are interested in unlearning, stop by our poster: 🕐 Wed, Dec 11 | 11 am - 2 pm PST 📍 West Ballroom #7006
Join us Tuesday at 1:30 PM PT at #NeurIPS2024 for our tutorial on data selection for foundation models! With @lschmidt3 & @JiachenWang97, we'll cover principled experimentation, selection algorithms, a unified theoretical framework, and open challenges. Hope to see you there!
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1…
🚀 Excited to announce our latest paper: MLAN: Language-Based Instruction Tuning Improves Zero-Shot Generalization of Multimodal Large Language Models! arxiv.org/abs/2411.10557