
mrfakename
@realmrfakename
LLMs, TTS, & Open Source https://huggingface.co/mrfakename
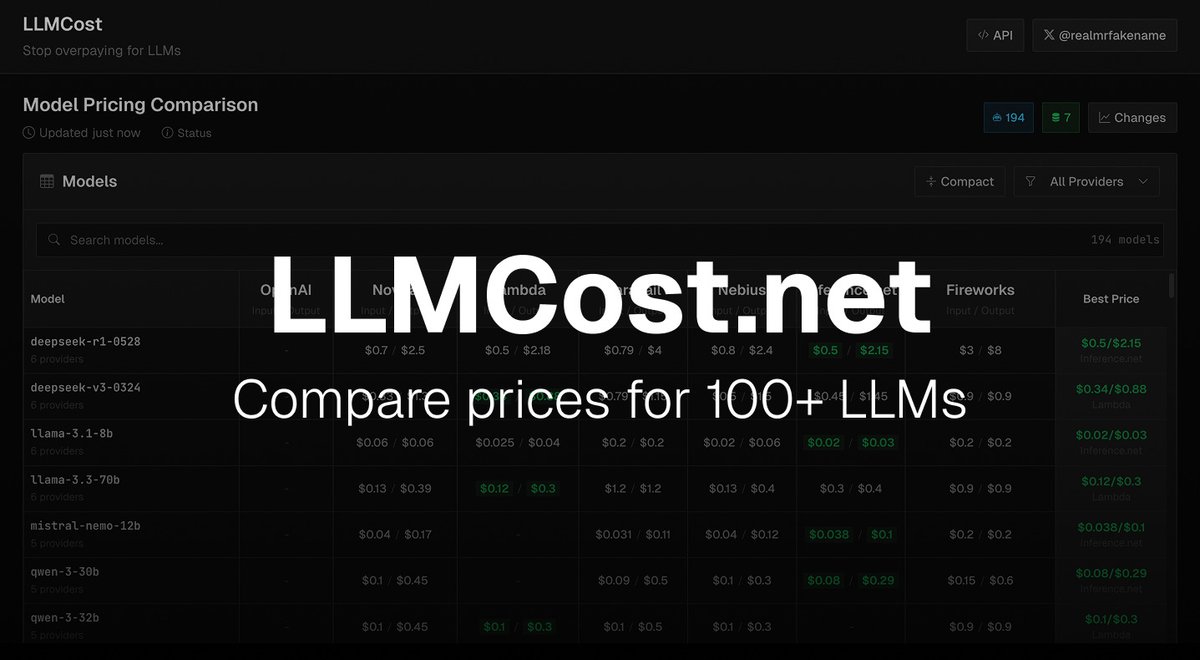
Introducing LLMCost: stop overpaying for LLMs LLMCost is a centralized dashboard that shows prices for 100+ LLMs across different providers, including @LambdaAPI, @FireworksAI_HQ, @inference_net, and more. Find the cheapest provider for any LLM. 100+ LLMs, updated nightly.
Can we get any assurance about copyright, etc?
Love to see this from @WhiteHouse!
In our continued commitment to open-science, we are releasing the Voxtral Technical Report: arxiv.org/abs/2507.13264 The report covers details on pre-training, post-training, alignment and evaluations. We also present analysis on selecting the optimal model architecture, which…
Qwen about to release a 480B MoE for coding with 1 million context! "Qwen3-Coder-480B-A35B-Instruct is a powerful coding-specialized language model excelling in code generation, tool use, and agentic tasks."
Qwen3-Coder
if you loved kimi k2, you will love what a certain chinese team is about to release which is highly competitive with 1M context length
Looks like Hugging Face is running out of GPUs 😂 Half the time when I try to start a Space I get a scheduling error
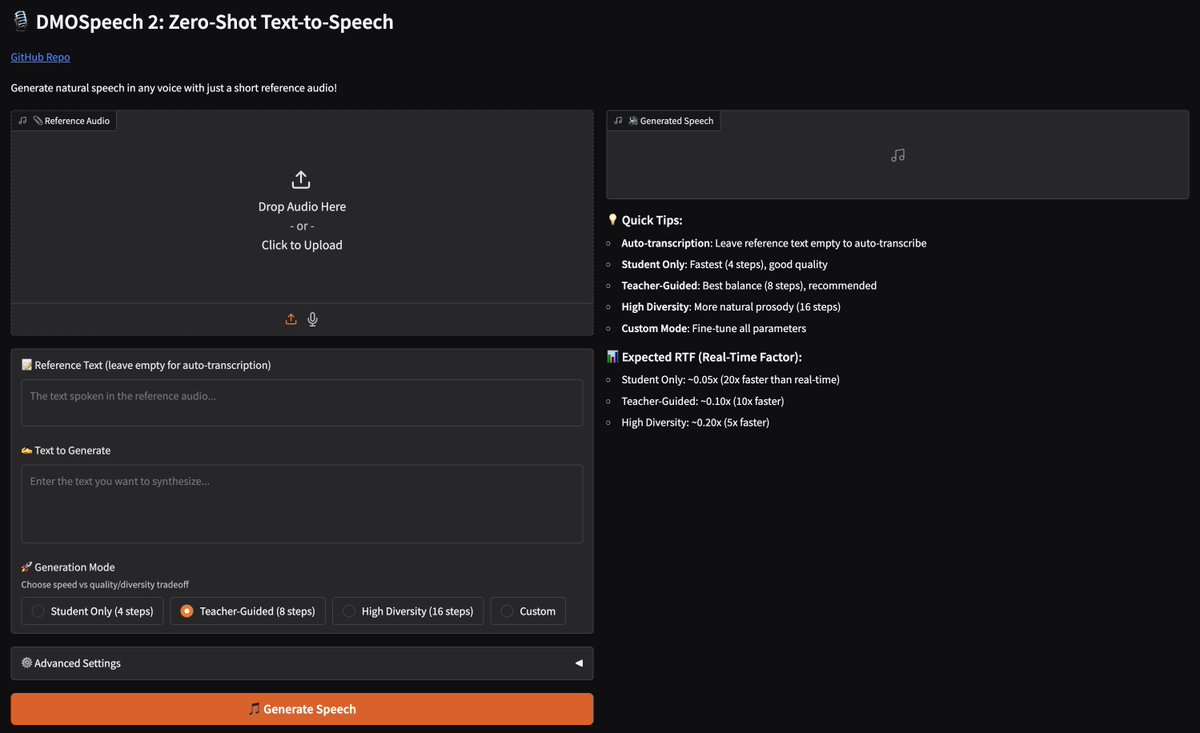
Gradio demo for DMOSpeech 2 now live! 2x faster F5-TTS with improved WER and stability through RL training, from the authors of F5-TTS: huggingface.co/spaces/mrfaken…
I highly suspect that Baseten is serving K2 in FP4 See this HF repo (might be removed soon lol)