
Yushi Bai
@realYushiBai
Ph.D. from Tsinghua University, currently focusing on long context LLM and reasoning models
🚀 New milestone in ultra-long text generation! LongWriter-Zero uses pure RL (no SFT, no synthetic data) to produce ultra-long, coherent texts (10k+ words). Beats open-source models like DeepSeek-R1 and Qwen3-235B in many domains. 👉 huggingface.co/THU-KEG/LongWr…
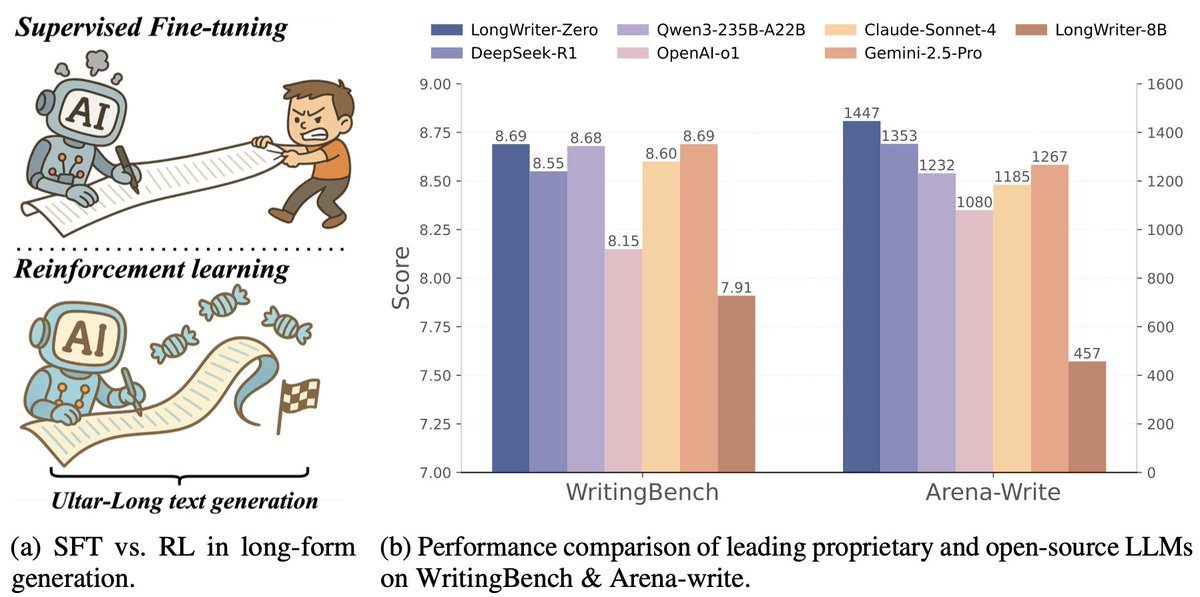
This paper proposes LongWriter-Zero, an incentivization-based reinforcement learning method. It trains models from scratch, enabling high-quality, ultra-long text generation without relying on pre-existing synthetic data. Methods 🔧: - LongWriter-Zero uses Group Relative…
LongWriter-Zero 🔥 A Purely RL trained LLM handles 10K+ token coherent passages by @Tsinghua_Uni Model: huggingface.co/THU-KEG/LongWr… Dataset: huggingface.co/datasets/THU-K… Paper: huggingface.co/papers/2506.18… ✨ 32B ✨ Multi-reward GRPO: length, fluency, structure, non-redundancy ✨ Enforces…
# 🚨 4B open-recipe model beats Claude-4-Opus 🔓 100% open data, recipe, model weights and code. Introducing Polaris✨--a post-training recipe for scaling RL on advanced reasoning models. 🥳 Check out how we boost open-recipe reasoning models to incredible performance levels…
Large language models struggle to generate consistently coherent and high-quality long text over increasing length. This paper mimics the human iterative process of planning and refining writing using an AI agent framework to train a new model. Methods 🔧: → The agent…
Promoting Our Preliminary Work on Efficient Video Understanding of LMMs Grateful for the support from Yuan Yao and all mentors! Since videos inherently exhibit varying temporal density (static/dynamic segments), a natural idea is to dynamically segment and compress a video to…
Off to #ICLR2025 🇸🇬 to present LongWriter: Unleashing 10,000+ Word Generation from Long-Context LLMs. Catch our poster during the first poster session on the morning of 4/24. Excited to reconnect and chat about long context, reasoning models, and more!

Try out the ⚡lightning fast models at z.ai! We're continuously optimizing our reasoning model, z1, to deliver the best possible experience.
🚀 New name, same mission — ChatGLM is now Z.ai. To mark this new chapter, we’re launching the fully open-source GLM-4-0414 model family under the MIT License — use it, build on it, profit from it. We’re open-sourcing six models across 9B and 32B sizes. Here…
o3's visual reasoning with tool use closely resembles our work CogCoM (visual Chain-of-Manipulation) published in 2024.02. Learn more in the CogCoM paper linked in the quoted thread!
Today, on April 17th, OpenAI released a new visual reasoning model, o3, capable of solving complex tasks by analyzing and manipulating images. We have observed that the reasoning approach employed by the o3 model bears a striking resemblance to our earlier work, Cogcom…
Congrats on the impressive long-context capabilities of Gemini 2.5 Pro! It’s exciting to see these rapid advancements of long-context LLMs through LongBench v2! 🌐Website: longbench2.github.io
Just saw these LongBench v2 results - enjoy 1M context in our model, soon to be 2M! longbench2.github.io/#leaderboard
StdGEN Semantic-Decomposed 3D Character Generation from Single Images
📢 LongWriter got accepted for #ICLR2025. See you in Singapore!
LongWriter Unleashing 10,000+ Word Generation from Long Context LLMs discuss: huggingface.co/papers/2408.07… Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words.…