
Nimit Kalra @ ICML 2025
@qw3rtman
currently feynman technique-ing my way through life. research @haizelabs, prev @citadel
Flying out to #ICML2025 tonight! Always down to chat about unverifiable domains, evals, red-teaming, safeguards, or just meet cool people. I’ll be a panelist at the Methods and Opportunities at Small Scale workshop, sharing our work on tiny generalist reward models…
Discussing "Mind the Gap" tonight at @haizelabs's NYC AI Reading Group with @leonardtang_ and @willccbb. Authors study self-improvement through the "Generation-Verification Gap" (model's verification ability over its own generations) and find that this capability log scales with…
Still noodling on this, but the generation-verification gap proposed by @yus167 @_hanlin_zhang_ @ShamKakade6 @udayaghai et al. in arxiv.org/abs/2412.02674 is a very nice framework that unifies a lot of thoughts around self-improvement/verification/bootstrapping reasoning
The current state of the ecosystem for post-training using GRPO w/ vllm + flash attention is frustratingly brittle. - The most recent vllm only supports PyTorch==2.7.0 - vllm requires xformers, but specifically only v0.0.30 is supported for torch 2.7.0. Any prior version of…

Vogent has a fantastic battle-tested inference stack, glad to see they opened it up + already have a finetuning product. From what I've seen, open-source voice models solve the 0 → 1 quite well but require a lot of post-hoc tuning to get right
Today we're launching Vogent Voicelab: an optimized API to run top open-source voice models, like Sesame's CSM-1B, Dia, Orpheus, and more.
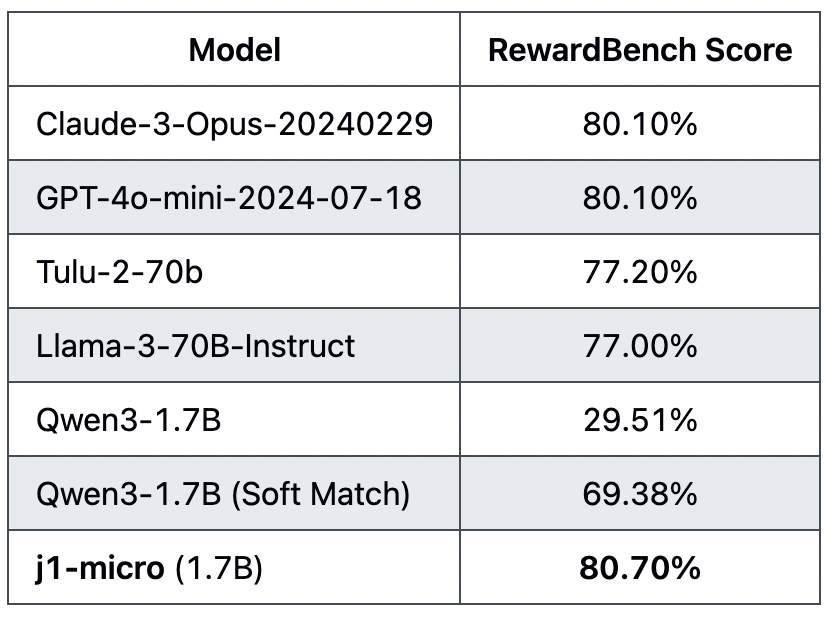
chart crime so bad you gotta transcribe the values by hand and plot it yourself
evals evals evals
Mercor (@mercor_ai) is now working with 6 out of the Magnificent 7, all of the top 5 AI labs, and most of the top application layer companies. One trend is common across every customer: we are entering The Era of Evals. RL is becoming so effective that models will be able to…
New open-source alert! spoken: a unified abstraction over realtime speech-to-speech foundation models. Run any S2S model from OpenAI, Google, Amazon — one interface with one line of code.
qwen RL has felt icky recently, but these authors get llama RL to match
What Makes a Base Language Model Suitable for RL? Rumors in the community say RL (i.e., RLVR) on LLMs is full of “mysteries”: (1) Is the magic only happening on Qwen + Math? (2) Does the "aha moment" only spark during math reasoning? (3) Is evaluation hiding some tricky traps?…