
mike64_t
@mike64_t
descending the gradient
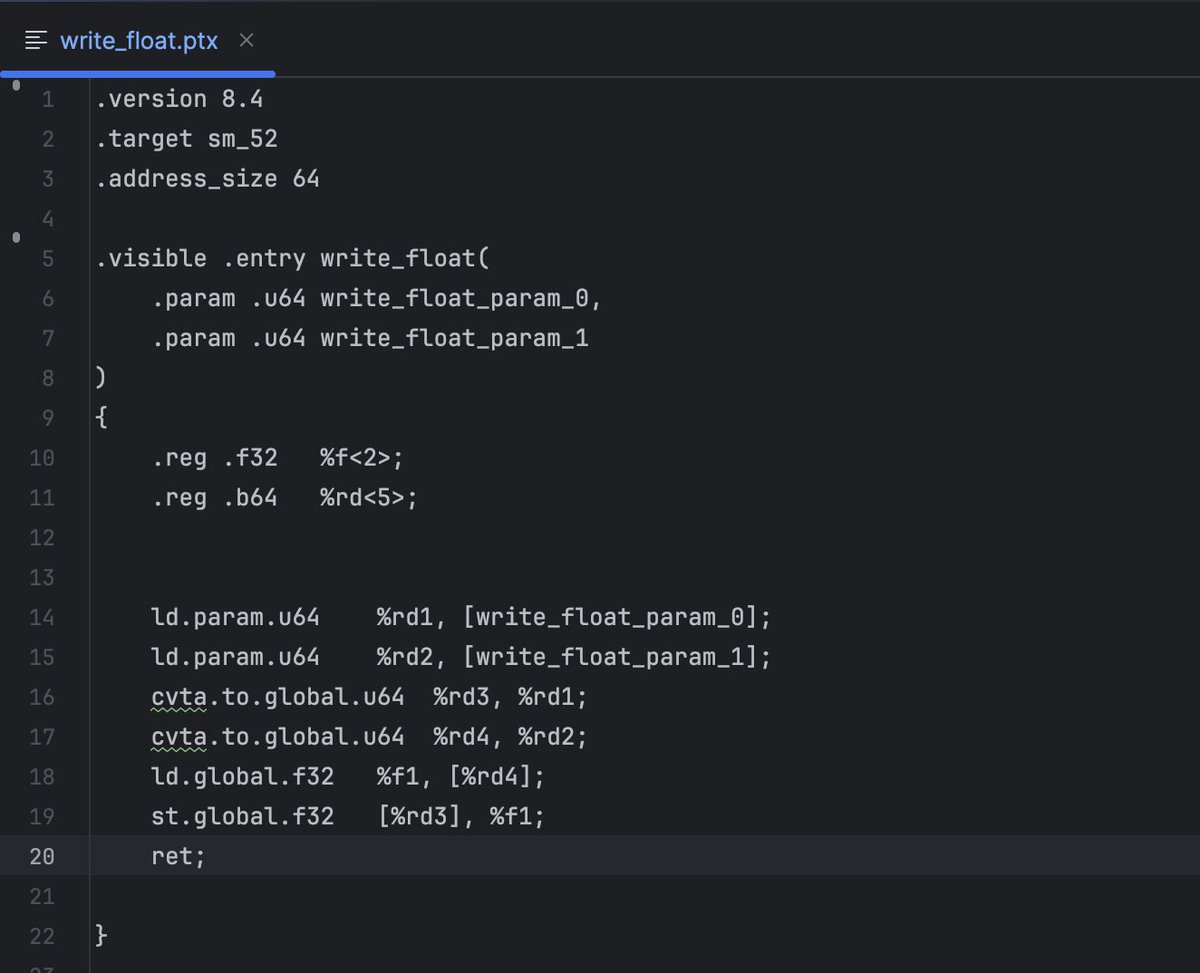
It is done. LibreCUDA can now launch CUDA kernels without relying on the proprietary CUDA runtime / driver api. It does so by communicating directly with the hardware via the ioctl "rm api" and Nvidia's QMD MMIO command queue structure.


And that is why it is not yet the end of unsupervised learning. You can believe that.
pretraining is an elegant science, done by mathematicians who sit in cold rooms writing optimization theory on blackboards, engineers with total absorb of distributed systems of titanic scale posttraining is hair raising cowboy research where people drinking a lot of diet coke…

The Saga of wandb color debates continues. Apparently everyone at prime intellect is color blind...

It's honestly incomprehensible to me that we haven't started writing training solutions like game engines. Stable, well designed abstractions, in a clean zero-dependency C++ project. You know game engines also just build GPU command buffers, right?
AI researchers when they discovered that torch.compile doesn't scale well to real multi-node production training workloads and is a giant footgun



I have to say in many respects I've had more quality conversations in Berlin than in SF. Never has it happened in SF that people actually pull out pen and paper to talk precisely about hard concepts where surface level talk is just not enough. The overton window is wider and…
I realized at our Berlin event that there are a lot of talented and ambitious young ppl in Europe. Just (almost) no inspiring company to build the future nor VC that have the balls to give them a chance. No wonder why everybody wants to come to sf|