Mengshiun
@mengshyu
FlashInfer won #MLSys2025 best paper🏆, with backing from @NVIDIAAIDev to bring top LLM inference kernels to the community
🎉 Congratulations to the FlashInfer team – their technical paper, "FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving," just won best paper at #MLSys2025. 🏆 🙌 We are excited to share that we are now backing FlashInfer – a supporter and…
🚀Making cross-engine LLM serving programmable. Introducing LLM Microserving: a new RISC-style approach to design LLM serving API at sub-request level. Scale LLM serving with programmable cross-engine serving patterns, all in a few lines of Python. blog.mlc.ai/2025/01/07/mic…
🚀✨Introducing XGrammar: a fast, flexible, and portable engine for structured generation! 🤖Accurate JSON/grammar generation ⚡️3-10x speedup in latency 🤝Easy LLM engine integration ✅ Now in MLC-LLM, SGLang, WebLLM; vLLM & HuggingFace coming soon! blog.mlc.ai/2024/11/22/ach…
The latency of LLM serving has become increasingly important. How to strike a latency-throughput balance? How do TP and spec decoding help? We are thrilled to share the latest benchmark results and lessons for low-latency LLM serving through MLCEngine. blog.mlc.ai/2024/10/10/opt…
Llama-3.2 3B from @AIatMeta is now available on Android! Built with MLC LLM, this lightweight model is faster and more efficient, bringing advanced AI capabilities right to your device. 🦙📱 #AI #MobileAI" Check out llm.mlc.ai/docs/deploy/an… for quick start instructions.
Chatting with @GoogleDeepMind's Gemma 2 2B on Android using MLC LLM. It's pretty fast and accurate, beating GPT-3.5. Check out llm.mlc.ai/docs/deploy/an… for quick start instructions.
Excited to share WebLLM engine: a high-performance in-browser LLM inference engine! WebLLM offers local GPU acceleration via @WebGPU, fully OpenAI-compatible API, and built-in web workers support to separate backend executions. Check out the blog post: blog.mlc.ai/2024/06/13/web…
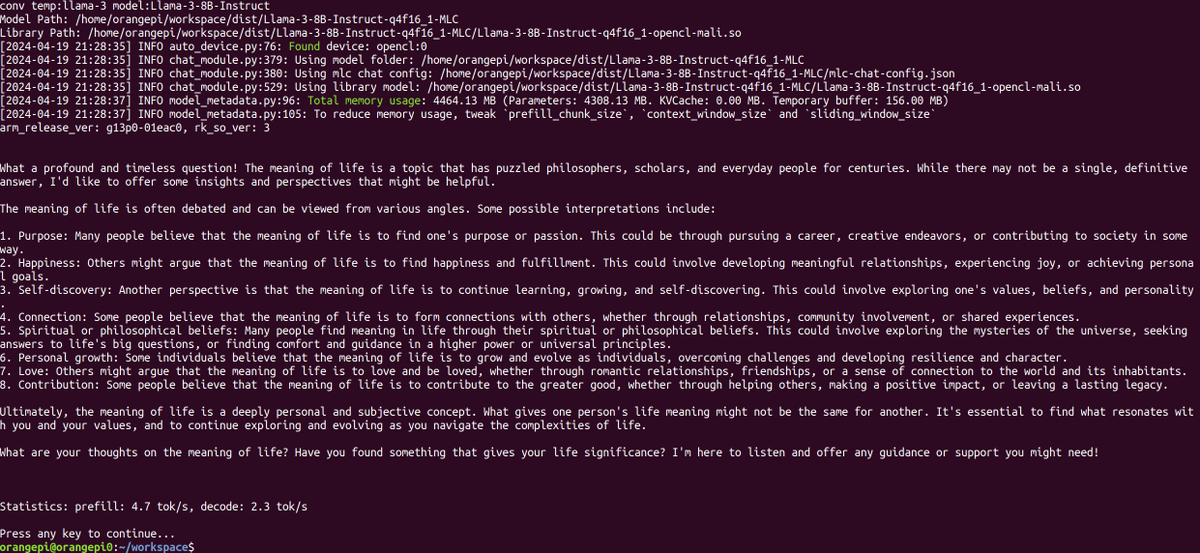
The latest version of MLC LLM now supports the newly released model Qwen2! Run it effortlessly on a $100 OrangePi. With Qwen2 0.5B 17.5 tok/s, 1.5B 8.9 tok/s, AI capabilities are more accessible than ever. Explore more at MLC LLM llm.mlc.ai #MLC #LLM #Qwen2 #OrangePi
Announcing MLCEngine, a universal LLM deployment engine with ML Compilation. We rebuilt the engine with state-of-the-art serving optimizations and maximum local env portability. Fully OpenAI compatible for both cloud and local use cases. Check out the blog blog.mlc.ai/2024/06/07/uni…
Deploy #Llama3 on $100 Orange Pi with GPU acceleration through MLC LLM. Try it out on your Orange Pi 👉 blog.mlc.ai/2023/08/09/GPU…