
LLaMA Factory
@llamafactory_ai
Towards easy and efficient fine-tuning of large language models
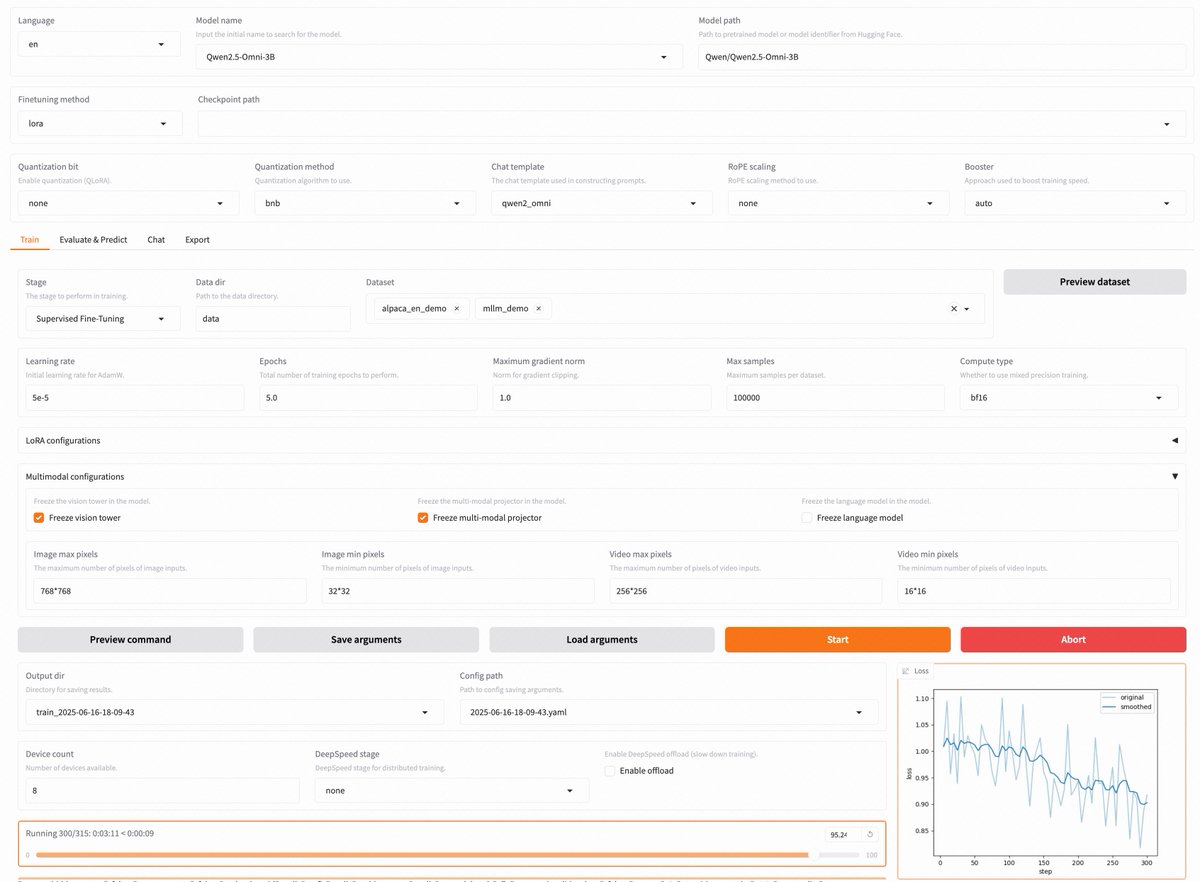
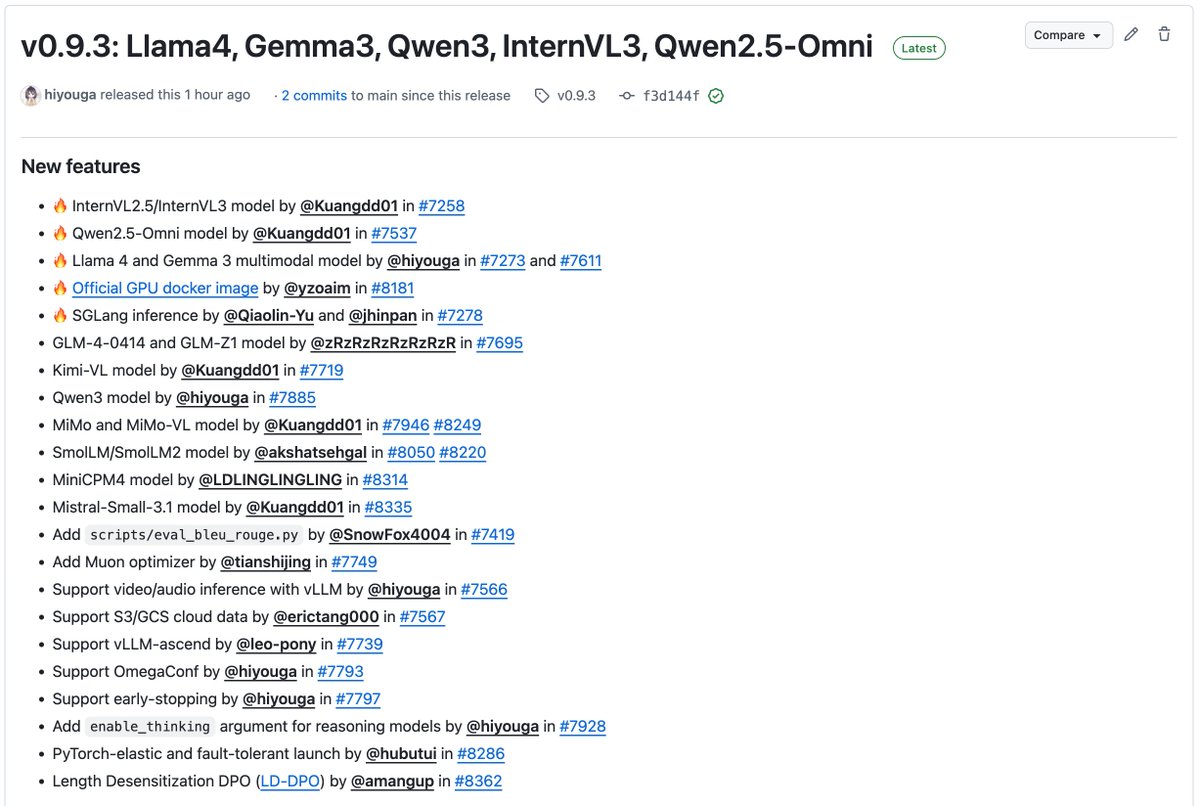
LLaMA-Factory v0.9.3 released! Thank you for 50k GitHub stars 🌟 Fully open-source, no-code fine-tuning on Gradio UI for nearly 300+ models -- including Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, etc. • Install locally via our Docker image: hub.docker.com/r/hiyouga/llam… •…
New tech report out! 🚀 Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training An expanded version of our ProRL paper — now with more training insights and experimental details. Read it here 👉 arxiv.org/abs/2507.12507
Does RL truly expand a model’s reasoning🧠capabilities? Contrary to recent claims, the answer is yes—if you push RL training long enough! Introducing ProRL 😎, a novel training recipe that scales RL to >2k steps, empowering the world’s leading 1.5B reasoning model💥and offering…
That would be so 🔥🔥🔥 @Alibaba_Qwen @Kimi_Moonshot
If i could have a wish today i would wish kimi and qwen release their post training datasets like nous does 🫣🤗 We could all be building off eachothers work a lot easier that way!
📢📢📢 Releasing OpenThinker3-1.5B, the top-performing SFT-only model at the 1B scale! 🚀 OpenThinker3-1.5B is a smaller version of our previous 7B model, trained on the same OpenThoughts3-1.2M dataset.
Introduce Easy Dataset No-code framework for synthesizing fine-tuning data from unstructured documents using LLMs/Ollamas Supports OCR, chunking, QA augmentation, and export to LlamaFactory/Unsloth fine-tuning frameworks huggingface.co/papers/2507.04…
LLaMA-Factory supported the multi-modal fine-tuning of the open-source GLM-4.1V-Thinking model at Day0 🔥
𝒁𝑯𝑰𝑷𝑼 𝑺𝑯𝑰𝑷𝑺 GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning GLM-4.1V-9B-Thinking introduces explicit intermediate reasoning through reinforcement learning with curriculum sampling, improving performance on tasks requiring…
PPO and GRPO — a workflow breakdown of the most popular reinforcement learning algorithms ➡️ Proximal Policy Optimization (PPO): The Stable Learner It’s used everywhere from dialogue agents to instruction tuning as it balances between learning fast and staying safe. ▪️ How PPO…
LLaMA Factory on ROCm 🔥
Fine-tune Llama-3.1 8B with Llama-Factory on AMD GPUs with this step-by-step guide: bit.ly/4k14ORL Discover more fine-tuning tutorials on the ROCm AI Developer Hub: bit.ly/4kLQiOQ
Fine-tune Llama-3.1 8B with Llama-Factory on AMD GPUs with this step-by-step guide: bit.ly/4k14ORL Discover more fine-tuning tutorials on the ROCm AI Developer Hub: bit.ly/4kLQiOQ
LLaMA-Factory now supports fine-tuning the Falcon H1 family of models using Full-FineTune or LoRA, kudos @DhiaRhayem
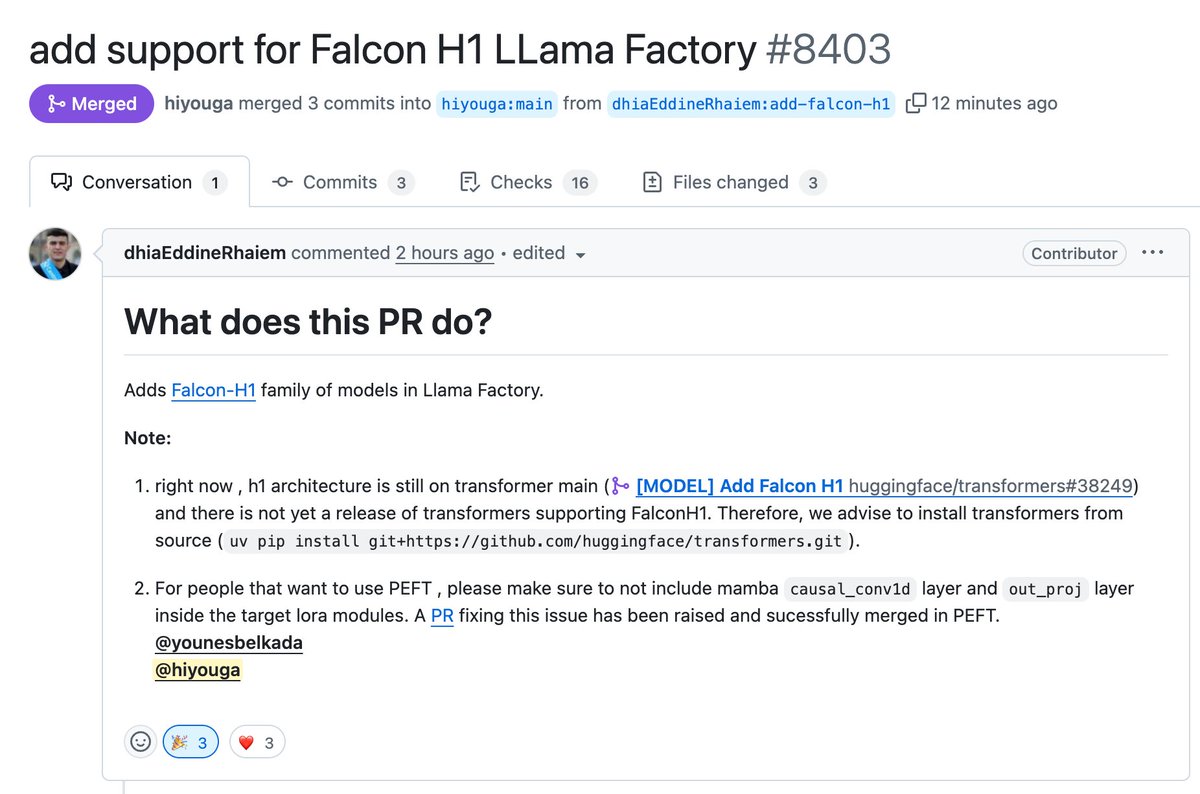
Insane milestone for Llama Factory!
LLaMA-Factory v0.9.3 released! Thank you for 50k GitHub stars 🌟 Fully open-source, no-code fine-tuning on Gradio UI for nearly 300+ models -- including Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, etc. • Install locally via our Docker image: hub.docker.com/r/hiyouga/llam… •…
DeepSeek 671b and Qwen3 236b support with Megatron backend is now available as preview in verl v0.4.0 🔥🔥🔥 We will continue optimizing MoE model performance down the road. DeepSeek 671b: verl.readthedocs.io/en/latest/perf… verl v0.4: github.com/volcengine/ver…
Open weights, Open data, Open code -- SOTA reasoning model with only 7B parameters. Excited to see LlamaFactory powering its training 🥳
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals. We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data…
Paper: arxiv.org/abs/2506.04178 Model: huggingface.co/open-thoughts/… Dataset: huggingface.co/datasets/open-… Code: github.com/open-thoughts/… Blog: openthoughts.ai/blog/ot3 (10/N)
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals. We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data…
tbf @llamafactory_ai is the next LMArena: Open-source, built with Gradio, huge impact in the world of LLMs and MLLMs! 🙌
Fine-tune 100+ LLMs directly from a UI! LLaMA-Factory lets you train and fine-tune open-source LLMs and VLMs without writing any code. Supports 100+ models, multimodal fine-tuning, PPO, DPO, experiment tracking, and much more! 100% open-source with 50k stars!