
Lexin Zhou
@lexin_zhou
Incoming CS PhD candidate @Princeton | Research on the Science of AI Evaluation and Social Computing at @MSFTResearch Newsletter: The AI Evaluation Substack
1/ New paper @Nature! Discrepancy between human expectations of task difficulty and LLM errors harms reliability. In 2022, Ilya Sutskever @ilyasut predicted: "perhaps over time that discrepancy will diminish" (youtu.be/W-F7chPE9nU, min 61-64). We show this is *not* the case!
This is very nice work
ADeLe, a new evaluation method, explains what AI systems are good at—and where they’re likely to fail. By breaking tasks into ability-based requirements, it has the potential to provide a clearer way to evaluate and predict AI model performance: msft.it/6014SkVGC
I have written a post summarising the main contributions of arxiv.org/abs/2503.06378. I explain why I think this provides a solid foundation for a "science of AI evals", and its main applications to AI safety evaluations, including control and alignment. lesswrong.com/posts/m2qMj7ov…
LLMs • agentic AI • #DataScience 🧵 1/ 🚨 New paper: “Measuring Data-Science Automation: A Survey of Evaluation Tools for AI Assistants & Agents.” If you care about the impact of LLMs and LLM agents on Data Science and how to measure it, this is for you!
This is one of the one the best (if not the best) approach to AI evaluation I've seen. You can't blabla your way to the predictive power they report in section 3.4!
ADeLe, a new evaluation method, explains what AI systems are good at—and where they’re likely to fail. By breaking tasks into ability-based requirements, it has the potential to provide a clearer way to evaluate and predict AI model performance: msft.it/6014SkVGC
Today marks a big milestone for me. I'm launching @LawZero_, a nonprofit focusing on a new safe-by-design approach to AI that could both accelerate scientific discovery and provide a safeguard against the dangers of agentic AI.
Every frontier AI system should be grounded in a core commitment: to protect human joy and endeavour. Today, we launch @LawZero_, a nonprofit dedicated to advancing safe-by-design AI. lawzero.org
The next ~1-4 years will be taking the 2017-2020 years of Deep RL and scaling up: exploration, generalization, long-horizon tasks, credit assignment, continual learning, multi-agent interaction! Lots of cool work to be done! 🎮🤖 But we shouldn't forget big lessons from back…
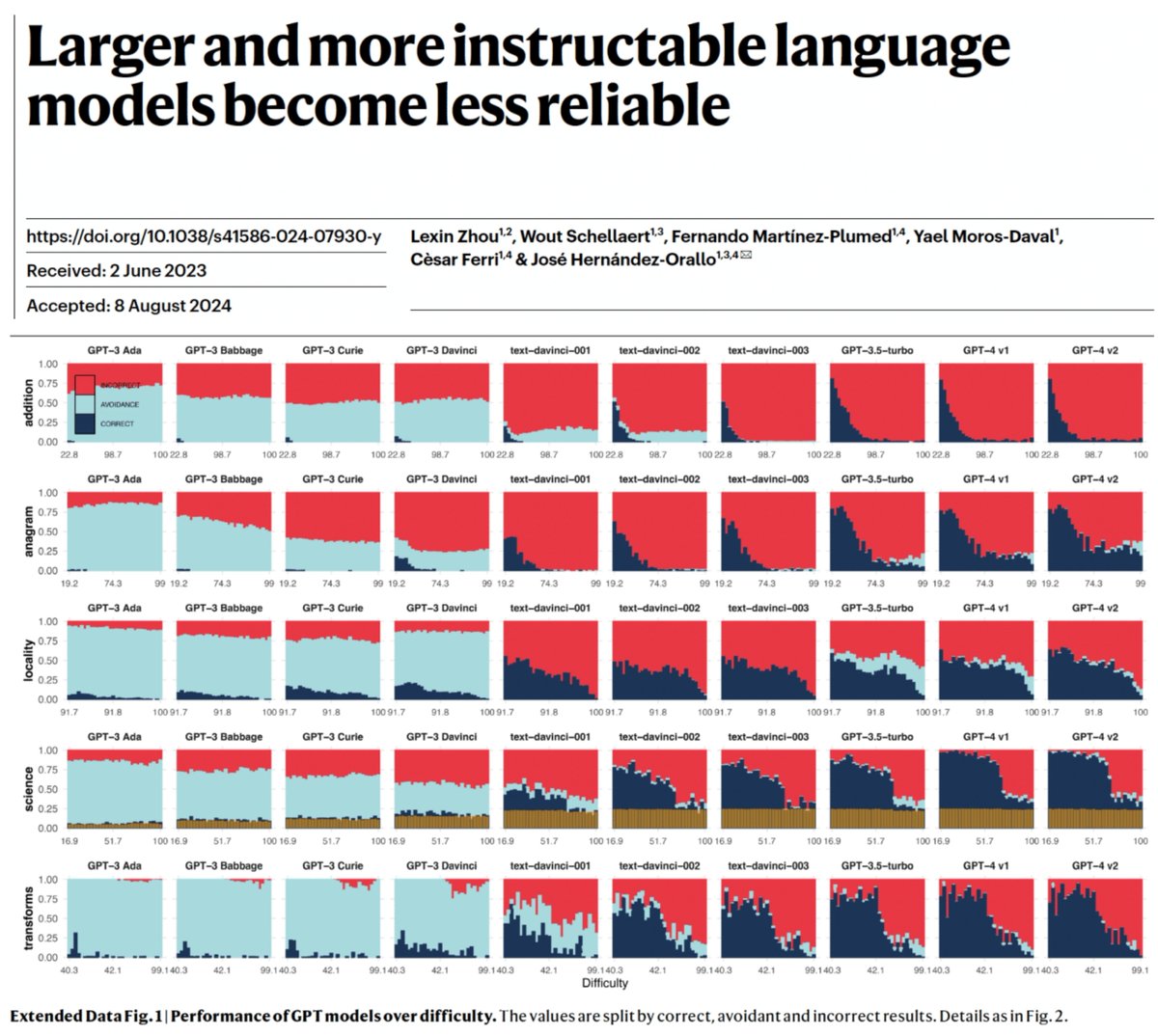
Great work! This reinforces one of the findings about avoidance/refusal in our previous paper (nature.com/articles/s4158…): The current paradigm of making LLMs more instructable has resulted in overconfident models spouting nonsense beyond their competence. To be fair, our work did…
🚨 We discovered a surprising side effect of Reinforcement Finetuning (RFT): it makes LLMs more confidently wrong on unanswerable questions. We call this the hallucination tax: a drop in refusal behavior that leads to overconfident hallucinations. 🧵 1/n
There are so many hallucinated citations in court nowadays, that I'm starting to put together a tracker. Check it out and feel free to send ones that I've missed along. New tabs coming for more categories of AI+Law cases!
I first came across this idea thanks to José H. Orallo and his team, who explained it in a recent Substack post. In short: You can think of the METR graph as showing how the chance of failure drops for tasks of a fixed length. And when you have a long task, you can think of it…
Is there a half-life for the success rates of AI agents? I show that the success rates of AI agents on longer-duration tasks can be explained by an extremely simple mathematical model — a constant rate of failing during each minute a human would take to do the task. 🧵 1/
Excited to share the Societal AI research agenda—a cross-disciplinary effort to align AI with human values and societal needs. Check out our white paper and podcast hosted by Gretchen Huizinga! Thanks to all contributors! #SocietalAI #ResponsibleAI #MicrosoftResearch
Learn about a new white paper on Societal AI, an interdisciplinary framework for guiding AI development that reflects shared human values. It presents key research challenges and emphasizes collaboration across disciplines: msft.it/6016Sp3Na
Thrilled to know that our paper, `Safety Alignment Should be Made More Than Just a Few Tokens Deep`, received the ICLR 2025 Outstanding Paper Award. We sincerely thank the ICLR committee for awarding one of this year's Outstanding Paper Awards to AI Safety / Adversarial ML.…
Outstanding Papers Safety Alignment Should be Made More Than Just a Few Tokens Deep. Xiangyu Qi, et al. Learning Dynamics of LLM Finetuning. Yi Ren and Danica J. Sutherland. AlphaEdit: Null-Space Constrained Model Editing for Language Models. Junfeng Fang, et al.
Sad that I can't be at #ICLR2025 this year, but excited for a bunch of our work to be presented there! Check out the screenshot for where to find our papers. And be sure to keep an eye out for other work from the Princeton Language+Law, AI, & Society (POLARIS) Lab! 🧵👇
What happens when a static benchmark comes to life? ✨Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/
New comment in Nature by me and @sayashk on the risks of the extremely rapid ongoing adoption of AI in science nature.com/articles/d4158… One risk is that machine-learning-based modeling is tricky to do correctly and this has led to a reproducibility crisis, which our research has…
You can already post on arxiv and ignore the peer reviewed system. The expensive thing is people’s attention and the peer-reviewed system is actually a (noisy) equalizer. To elaborate: The reason the peer-reviewed system has worked as the only known stable system for the…
🚨To continuously foster conceptual & technical innovations for a science of AI Evaluation building on our methodology: An open collaborative community is initiated by @LeverhulmeCFI, to adopt and extend the methodology. Join us: kinds-of-intelligence-cfi.github.io/ADELE! Active updates of…
New Paper: We unlock AI Evaluation with explanatory and predictive power through general ability scales! -Explains what common benchmarks really measure -Extracts explainable ability profiles of AI systems -Predicts performance for new task instances, in & out-of-distribution 🧵