Peter Henderson
@PeterHndrsn
Assistant Professor @ Princeton (AI+RL+strategic decision making+Law). Prev: Stanford (JD/PhD); McGill/Mila; Meta FAIR; Amazon; Cal Supreme Court.
Many brilliant industry AI researchers have told me that bureaucracy is slowing them down. An underrated research question is: How do we design teams & incentives that improve research speed and impact—along with team happiness? Any thoughts out there on optimal strategies?
A different kind of AI intellectual property lawsuit...
🚨BREAKING Google X spin out IYO, which makes smart ear buds from 2018, alleges Sam Altman / OpenAI heard their pitch, passed, got Jony Ive to try it before copying it, buying his co for $6.5B and calling it IO. Most dramatic must-read tech lawsuit this year. Link below:
🧠New on the CITP Blog from PhD student Boyi Wei (@wei_boyi) of the POLARIS Lab: "The 'Bubble' of Risk: Improving Assessments for Offensive Cybersecurity Agents" Read about how adversaries can adapt and modify open-source models to bypass safeguards. 👇 blog.citp.princeton.edu/2025/07/21/the…
👉 We are hiring!! How will AI agents interact with you, learn from you and empower you in the future? Reward signals will not always be clearly defined… Breakthroughs are needed in multi turn RL, self-evaluation and self-improvement - if you are excited by this, join us! 👇
Do you have a PhD (or equivalent) or will have one in the coming months (i.e. 2-3 months away from graduating)? Do you want to help build open-ended agents that help humans do humans things better, rather than replace them? We're hiring 1-2 Research Scientists! Check the 🧵👇
Excited to present our AI Flaw Disclosure paper at #ICML2025 in Vancouver!🌲🌊🏔️ Swing by our poster session in East Exhibition Halls A-B E-606!
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️ Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-action to empower independent evaluators: 1️⃣ Standardized AI flaw reports 2️⃣ AI flaw disclosure programs + safe harbors. 3️⃣ A coordination…
Are static evaluations enough to reflect the risk of offensive cyber security attacks? In our latest blog post, authors @wei_boyi @benediktstroebl @JiacenXu @JoieZhang @lzcarl and @PeterHndrsn show the answer is no! Read more: pli.princeton.edu/blog/2025/%E2%…
My new pet peeve is statements like “RL does this but SFT does that.” RL encompasses many things and all the components matter for the statement being made. A general statement like this is almost never true because it is under specified.
Hypothetical, should Google have been allowed to patent the transformer architecture (and variants its researchers created) and exclude the rest of the AI industry for 20 years?
in industries where patents and such aren’t viable market participants will drastically underinvest in R&D efforts due to IP “seepage”. just like the “I drink your milkshake” effect of oil seepage and land rights. there is a compelling pro-consumer case for noncompetes
Super useful to see how contaminated benchmarks are! ⚠️MMLU seems very much deprecated between 9-28% contamination, error rate, and high avg model perf. 📈Slight uptick in contamination of GPQA on more recent CC crawls. Future probably requires live dynamic, slightly…
(4/n) We host a bulletin to track benchmark contamination as text corpora evolve, and provide regular updates. You can view results and add new benchmarks to be monitored for contamination. infini-gram-mini.io/bulletin
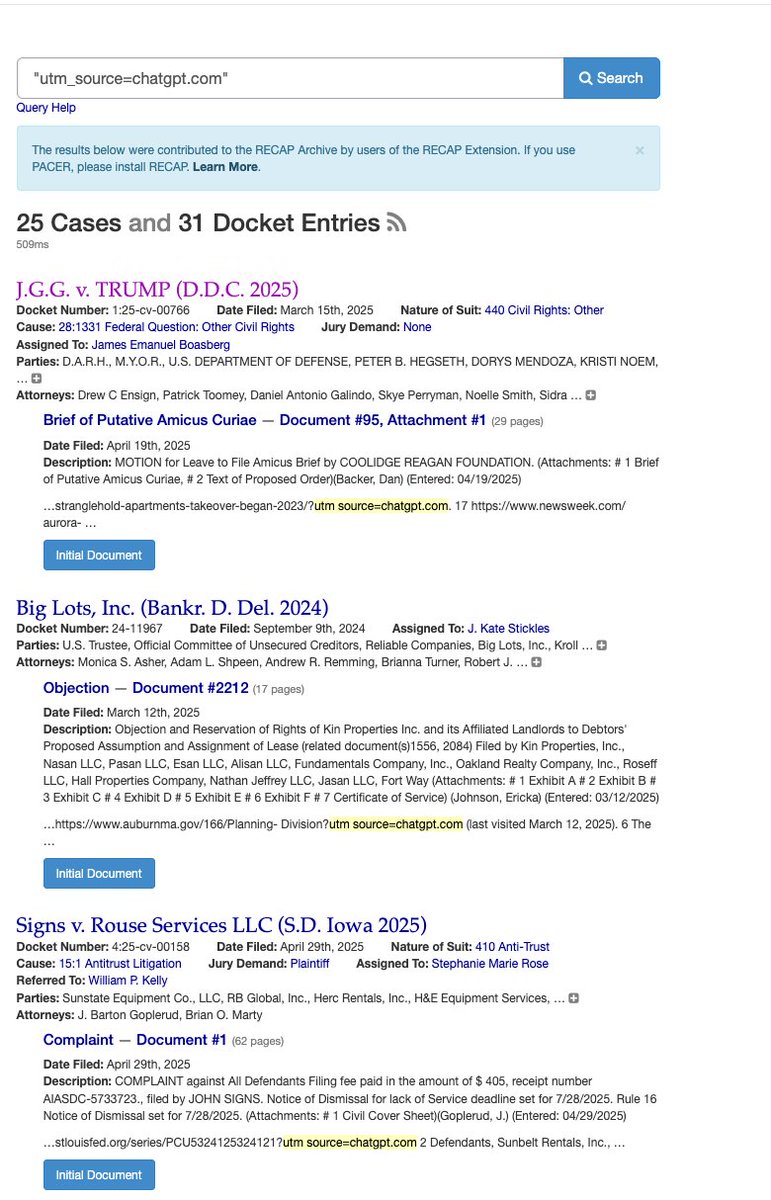
Thanks to the new utm_source field that ChatGPT attaches to links, we see a lot of filings in court that clearly show evidence of ChatGPT usage despite not yet being called out or do not contain hallucinated citations.