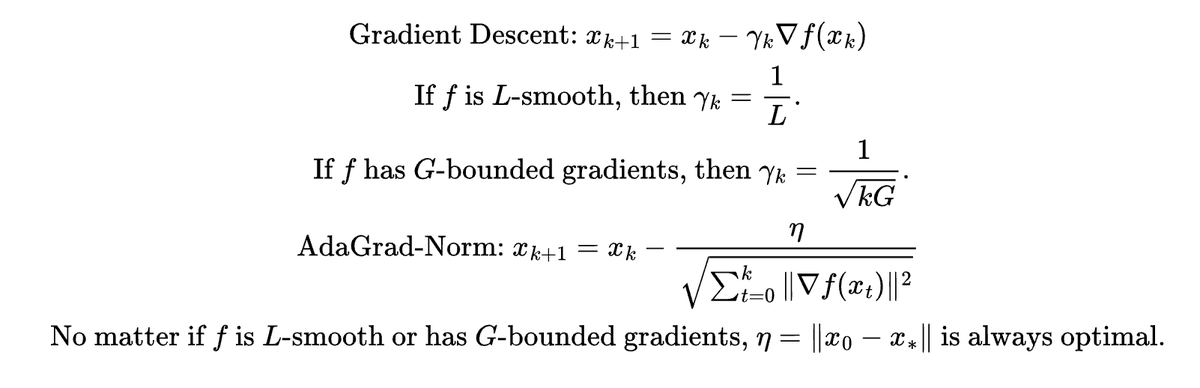
Konstantin Mishchenko
@konstmish
Research Scientist @AIatMeta Previously Researcher @ Samsung AI Outstanding Paper Award @icmlconf 2023 Action Editor @TmlrOrg I tweet about ML papers and math
A student reached out asking for advice on research directions in optimization, so I wrote a long response with pointers to interesting papers. I thought it'd be worth sharing it here too: 1. Adaptive optimization. There has been a lot going on in the last year, below are some…
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n
We just released the best 3B model, 100% open-source, open dataset, architecture details, exact data mixtures and full training recipe including pre-training, mid-training, post-training, and synthetic data generation for everyone to train their own. Let's go open-source AI!
Introducing SmolLM3: a strong, smol reasoner! > SoTA 3B model > dual mode reasoning (think/no_think) > long context, up to 128k > multilingual: en, fr, es, de, it, pt > fully open source (data, code, recipes) huggingface.co/blog/smollm3
The thing I like about AdaGrad is not that it estimates the learning rates for each coordinate, but rather that it uses the same stepsize no matter the function class that you minimize. If you use gradient descent you have to know either L from L-smoothness or an upper bound G on…