Karolina Stanczak
@karstanczak
Postdoc NLP @Mila_Quebec & @mcgillu | Previous PhD candidate @uni_copenhagen @CopeNLU
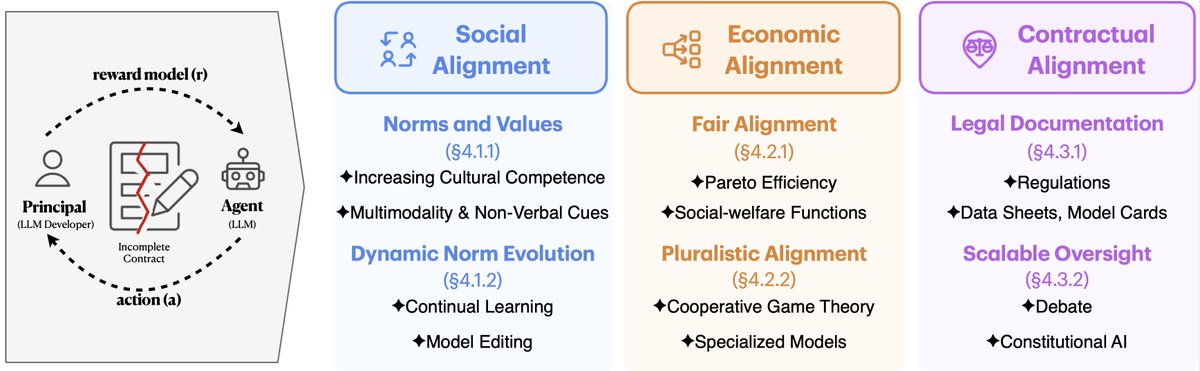
📢New Paper Alert!🚀 Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔 Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵
AgentRewardBench will be presented at @COLM_conf 2025 in Montreal! See you soon and ping me if you want to meet up!
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories. We find that rule-based evals underreport success rates, and…
We are thrilled to announce our keynote speakers for the 6th Workshop on Gender Bias in NLP at #ACL2025! Please join us in welcoming: 🔹Anne Lauscher (@anne_lauscher) 🔹Maarten Sap (@MaartenSap) Full details: gebnlp-workshop.github.io/keynotes.html See you on August 1! ☀️ #NLProc #GeBNLP
Super excited that our work on SafeArena is in great hands with @ncmeade at #ICML2025! Go say hi and talk to Nick about all things web agent safety! 🤖
I'll be at #ICML2025 this week presenting SafeArena (Wednesday 11AM - 1:30PM in East Exhibition Hall E-701). Come by to chat with me about web agent safety (or anything else safety-related)!
"Build the web for agents, not agents for the web" This position paper argues that rather than forcing web agents to adapt to UIs designed for humans, we should develop a new interface optimized for web agents, which we call Agentic Web Interface (AWI).
Our VLMs4All workshop is taking place today! 📅 on Thursday, June 12 ⏲️ from 9AM CDT 🏛️in Room 104E Join us today at @CVPR for amazing speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware! #CVPR2025
🗓️ Save the date! It's official: The VLMs4All Workshop at #CVPR2025 will be held on June 12th! Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐 Check out the schedule below!
My lab’s contributions at #CVPR2025: -- Organizing @vlms4all workshop (with 2 challenges) sites.google.com/corp/view/vlms… -- 2 main conference papers (1 highlight, 1 poster) cvpr.thecvf.com/virtual/2025/p… (highlight) cvpr.thecvf.com/virtual/2025/p… (poster) -- 4 workshop papers (2 spotlight talks, 2…
Do LLMs hallucinate randomly? Not quite. Our #ACL2025 (Main) paper shows that hallucinations under irrelevant contexts follow a systematic failure mode — revealing how LLMs generalize using abstract classes + context cues, albeit unreliably. 📎 Paper: arxiv.org/abs/2505.22630 1/n
🗓️ Save the date! It's official: The VLMs4All Workshop at #CVPR2025 will be held on June 12th! Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐 Check out the schedule below!
🚀 Important Update! We're reaching out to collect email IDs of the CulturalVQA and GlobalRG challenge participants for time-sensitive communications, including informing the winning teams. ALL participating teams please fill out the forms below ASAP (ideally within 24 hours). 👇
Congratulations to Mila members Ada Tur, Gaurav Kamath and @sivareddyg for their SAC award at #NAACL2025! Check out Ada's talk in Session I: Oral/Poster 6. Paper: arxiv.org/abs/2502.05670
📢 Deadline Extended! The paper submission deadline for #VLMs4All Workshop at CVPR 2025 has been extended to Monday Apr 28! 💡 We encourage submissions that explore multicultural perspectives in VLMs 🔗 openreview.net/group?id=thecv… 📍 Let's shape the future of globally inclusive AI!
13/🧵AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories AGENTREWARDBENCH is a benchmark designed to evaluate the effectiveness of Large Language Model judges in assessing web agent performance, revealing that while LLMs show potential, no single model…
Benchmarking the performance of Models as judges of Agentic Trajectories 📖 Read of the day, season 3, day 30: « AgentRewardBench: Evaluating Automatic Evaluations of Web Trajectories », by @xhluca, @a_kazemnejad et al from @mcgillu and @Mila_Quebec The core idea of the…
🚨 Deadline Extension Alert for #VLMs4All! 🚨 We have extended the challenge submission deadline 🛠️ New challenge deadline: Apr 22 Show your stuff in the CulturalVQA and GlobalRG challenges! 👉 sites.google.com/view/vlms4all/… Spread the word and keep those submissions coming! 🌍✨
AgentRewardBench Evaluating Automatic Evaluations of Web Agent Trajectories
A key reason RL for web agents hasn’t fully taken off is the lack of robust reward models. No matter the algorithm (PPO, GRPO), we can’t reliably do RL without a reward signal. With AgentRewardBench, we introduce the first benchmark aiming to kickstart progress in this space.
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories. We find that rule-based evals underreport success rates, and…
Curious about the trajectories? Check our @Gradio demo on @huggingface spaces: huggingface.co/spaces/McGill-…
Check out @xhluca new benchmark for evaluating reward models for web tasks! AgentRewardBench has rich human annotations of trajectories from top LLM web agents across realistic web tasks and will greatly help steer the design of future reward models.
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories. We find that rule-based evals underreport success rates, and…
Exciting release! AgentRewardBench offers that much-needed closer look at evaluating agent capabilities: automatic vs. human eval. Important findings here, especially on the popular LLM judges. Amazing work by @xhluca & team!
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories. We find that rule-based evals underreport success rates, and…
🔔 Reminder & Call for #VLMs4All @ #CVPR2025! Help shape the future of culturally aware & geo-diverse VLMs: ⚔️ Challenges: Deadline: Apr 15 🔗sites.google.com/view/vlms4all/… 📄 Papers (4pg): Submit work on benchmarks, methods, metrics! Deadline: Apr 22 🔗sites.google.com/view/vlms4all/… Join us!
📢Excited to announce our upcoming workshop - Vision Language Models For All: Building Geo-Diverse and Culturally Aware Vision-Language Models (VLMs-4-All) @CVPR 2025! 🌐 sites.google.com/view/vlms4all