
Jiahui Yu
@jhyuxm
Perception @OpenAI; previously co-led Gemini Multimodal @GoogleDeepMind. opinions are my own.
“Thinking with Images” has been one of our core bets in Perception since the earliest o-series launch. We quietly shipped o1 vision as a glimpse—and now o3 and o4-mini bring it to life with real polish. Huge shoutout to our amazing team members, especially: - @mckbrando, for…
Introducing OpenAI o3 and o4-mini—our smartest and most capable models to date. For the first time, our reasoning models can agentically use and combine every tool within ChatGPT, including web search, Python, image analysis, file interpretation, and image generation.
this has been one of my helicopter moments too: astralcodexten.com/p/testing-ais-…
> a master's thesis worth of work lol clock reading isn't always accurate yet, but you may find these clocks from the internet interesting in one of my tests, the model reads the clock back and forth ~40 times before reaching a conclusion - scaling with test-compute for real...…
It took o3 practically a master's thesis worth of work, but *did* correctly read my wrist watch this afternoon!
> see how it solves a maze lol I tried a 200x200 maze and it worked, but it looked too crowded for the blog post—so we used a 25×25 maze instead.
We launched o3 and o4-mini today! Reasoning models are so much more powerful once they learn how to use tools end-to-end. Some of the biggest lifts are coming in multimodal domains like visual perception (see how it solves a maze in our blogpost: openai.com/index/thinking… 🤯)
Yesterday was crazy so i missed my post but damn one more "mini" coming soon!
Yesterday was crazy so I missed my post but damn the 4.1s awesome. @michpokrass @jhyuxm @johnohallman @SuvanshSanjeev @StrongDuality and so many others did a phenomenal job. We’re truly horrible at naming but the secret trick is that the models with mini in their name are 🔥
o1 and o3-mini now support file & image uploads. more is brewing - stay tuned!
Two updates you'll like— 📁 OpenAI o1 and o3-mini now support both file & image uploads in ChatGPT ⬆️ We raised o3-mini-high limits by 7x for Plus users to up to 50 per day
Congrats on the launch @shgusdngogo ! Your progress and resilience are truly inspiring. Always glad to empower Operator with better Perception!
We're excited to announce Operator: our research preview powered by Computer-Using Agent. It can use its own browser by perceiving screens from pixels and taking actions using keyboard and mouse.
Incompetence in the limit is indistinguishable from sabotage
one of my favorite Parti prompts too! these images brought me back to the days before Parti’s release — wrestling with blurry pixels and chasing fidelity.
The wombat was the spirit animal of Parti, and we did a lot of wombats with that model. One of my favorites was this batch on the left, with very satisfied-with-life wombats enjoying getting some work done at the beach while enjoying their martinis. Now brought to life by Veo!
I wasn’t at NeurIPS this year, but this slide is undeniably offensive and inappropriate. The green NOTE, in particular, is an awkward attempt to excuse the misconduct.
Mitigating racial bias from LLMs is a lot easier than removing it from humans! Can’t believe this happened at the best AI conference @NeurIPSConf We have ethical reviews for authors, but missed it for invited speakers? 😡
Congrats - great work! @JeffDean and the Gemini team
What a way to celebrate one year of incredible Gemini progress -- #1🥇across the board on overall ranking, as well as on hard prompts, coding, math, instruction following, and more, including with style control on. Thanks to the hard work of everyone in the Gemini team and…
Thrilled to release o1 with Vision! I want to give a special shoutout to @mckbrando @_ghorbani @alexkarpenko @robin_a_brown for driving this from Zero to One.
OpenAI o1 is now out of preview in ChatGPT. What’s changed since the preview? A faster, more powerful reasoning model that’s better at coding, math & writing. o1 now also supports image uploads, allowing it to apply reasoning to visuals for more detailed & useful responses.
You can now fine-tune GPT-4o to improve targeted Vision capabilities. More at openai.com/index/introduc…
Today at DevDay SF, we’re launching a bunch of new capabilities to the OpenAI platform:
Hey @zacharynado, sorry i'm late. 😃 We realized that vision capability was not enabled for the lmsys comparisons since May. It'll be on by default going forward!
"“Sorry I’m late” in over 50 languages" vs an 8B model matching 4o-mini and Flash 1.5 matching 4o and beating 3.5 Sonnet on vision (Pro 1.5 being SOTA is old news 😉) 🚀🚀🕺
multimodal moderation built on 4o, free for developers
We're upgrading the Moderation API with a new multimodal moderation model. - Supports both text and images. - More accurate, especially for non-English content. - Detects harm in two new categories. - Remains free for developers. openai.com/index/upgradin…
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. openai.com/index/introduc…
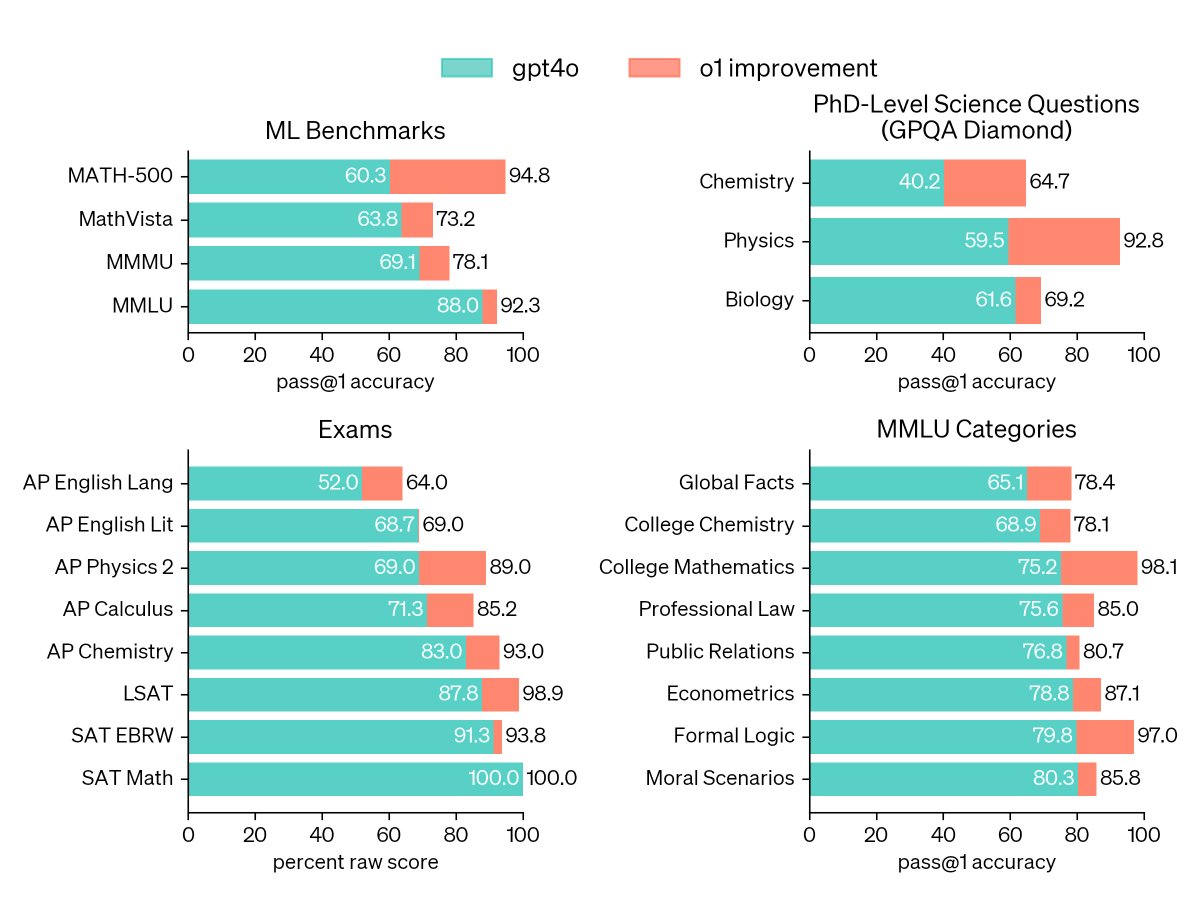
lowkey vision Perception update from OpenAI 🍓: o1 scored 78.2% on MMMU, making it the first model to be competitive with human experts. It also achieved 73.2% on MathVista. openai.com/index/learning…
I’ve been using multiple search engines for a single query for quite a while, and this search engine is amazing and improving drastically
we think there is room to make search much better than it is today. we are launching a new prototype called SearchGPT: openai.com/index/searchgp… we will learn from the prototype, make it better, and then integrate the tech into ChatGPT to make it real-time and maximally helpful.
The Perception team at OpenAI is hiring Research Engineers and Scientists! If you’re excited about advancing the frontier of perception and our mission to develop safe and beneficial AGI, join us! openai.com/careers/resear…