fluffy
@fluffykittnmeow
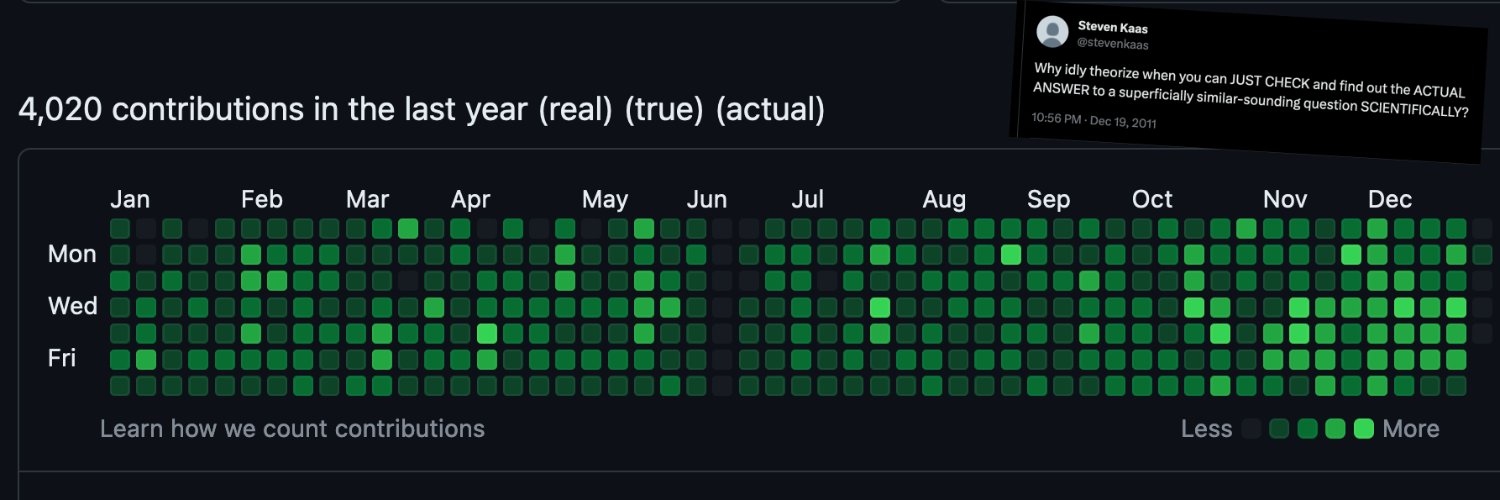
toil toil toil
Llama 4 analysis v1: 1. Maverick mixes MoE layers & dense - every odd MoE 2. Scout uses L2 Norm on QK (not QK Norm) 3. Both n_experts = 1 4. Official repo uses torch.bmm (not efficient) 5. Maverick layers 1, 3, 45 MoE are "special" layers 6. 8192 chunked attention Details: 1.…
You can now run Llama 4 on your local device!🦙 We shrank Maverick (402B) from 400GB to 122GB (-70%). Scout: 115GB to 33.8GB (-75%) Our Dynamic 1.78bit GGUFs ensures optimal accuracy by selectively quantizing layers GGUFs: huggingface.co/collections/un… Guide: docs.unsloth.ai/basics/tutoria…
A few weeks ago, @Grad62304977 pointed me towards PaLM's beta2 schedule. While improving convergence across domains, it also requires changes in Adam's algorithm. Today, I'm open-sourcing PaLM-Adam. Give it a try! gist.github.com/ClashLuke/9a00… x.com/Grad62304977/s…
Thanks! Have u tried the palm beta2 schedule? 1 - k^0.8 where k is the step
FlashAttention is widely used to accelerate Transformers, already making attention 4-8x faster, but has yet to take advantage of modern GPUs. We’re releasing FlashAttention-3: 1.5-2x faster on FP16, up to 740 TFLOPS on H100 (75% util), and FP8 gets close to 1.2 PFLOPS! 1/
The kind folks from @modal_labs have just shared with me this 10-100x faster drop in replacement for pip github.com/astral-sh/uv If you want a much faster CI startup switch to uv now! To use you just add `uv` before `pip` and everything else is the same, so: pip install uv uv…
Excited to share what I've been working on as part of the former Superalignment team! We introduce a SOTA training stack for SAEs. To demonstrate that our methods scale, we train a 16M latent SAE on GPT-4. Because MSE/L0 is not the final goal, we also introduce new SAE metrics.
We're sharing progress toward understanding the neural activity of language models. We improved methods for training sparse autoencoders at scale, disentangling GPT-4’s internal representations into 16 million features—which often appear to correspond to understandable concepts.…
Just got the results!!! MMDiT 🤝muP. infinite width never disappoints 🫡 @TheGregYang Gradient norm: never blows up, Loss : never spikes, any scale! Feature updates: Maximal🌊🌊 The code to reproduce this -> github.com/cloneofsimo/mi…

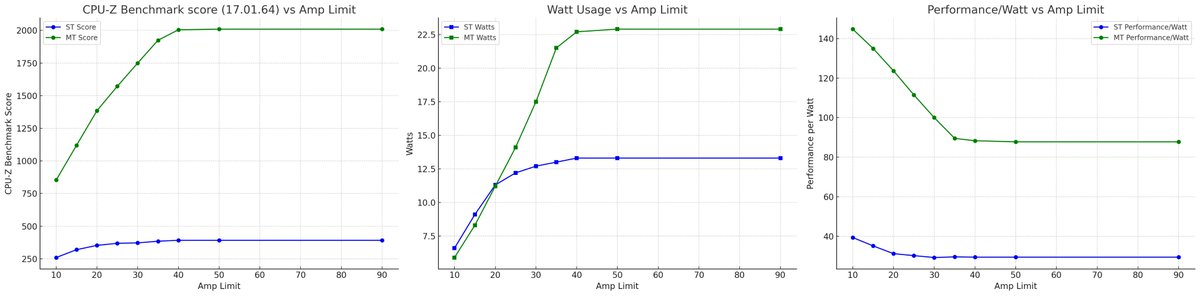
ancient 2017 laptop (XPS 15 9560) at various amperage limits (-125mV offset), cause why not
magnet:?xt=urn:btih:9238b09245d0d8cd915be09927769d5f7584c1c9&dn=mixtral-8x22b&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce&tr=http%3A%2F%https://t.co/OdtBUsbeV5%3A1337%2Fannounce
Announcing Stable Diffusion 3, our most capable text-to-image model, utilizing a diffusion transformer architecture for greatly improved performance in multi-subject prompts, image quality, and spelling abilities. Today, we are opening the waitlist for early preview. This phase…
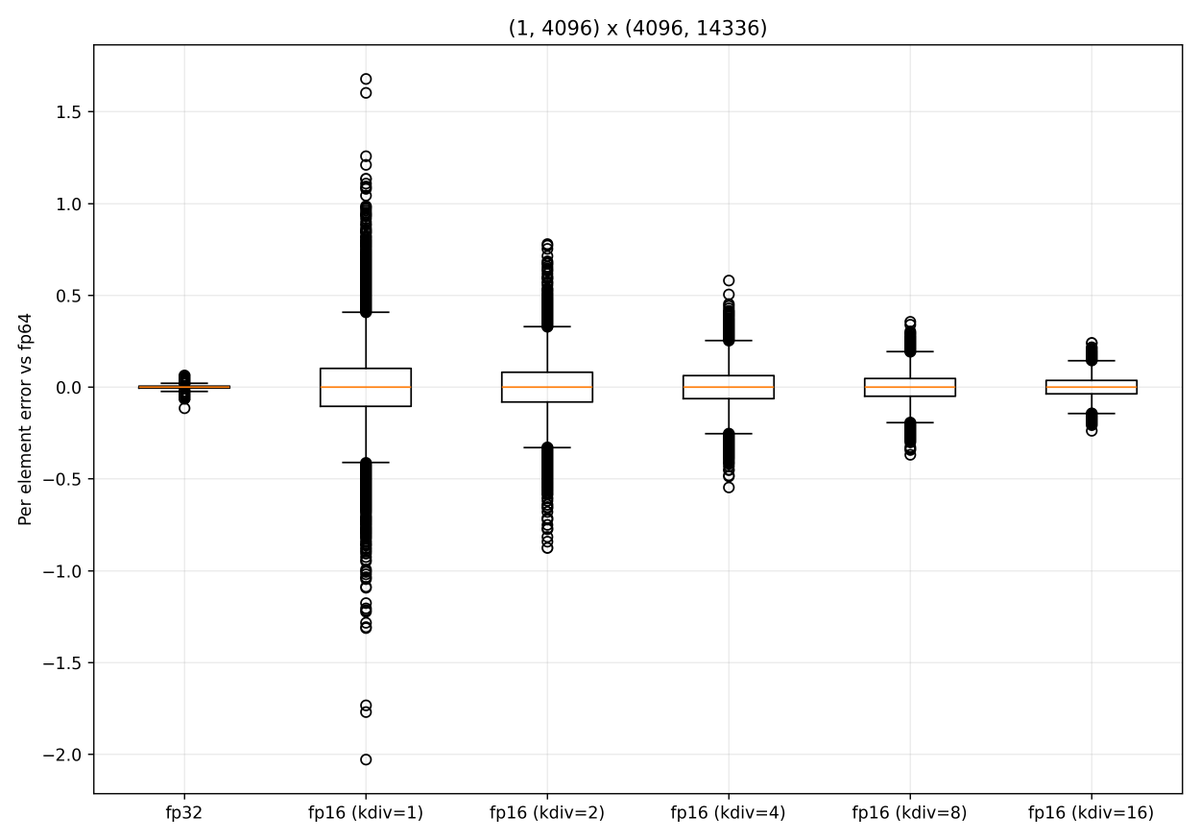
FlashAttention v2.5.5 now supports head dim 256 backward on consumer GPUs. Hope that makes it easier to finetune Gemma models
magnet:?xt=urn:btih:7b212968cbf47b8ebcd7017a1e41ac20bf335311&xt=urn:btmh:122043d0d1a79eb31508aacdfe2e237b702f280e6b2a1c121b39763bfecd7268a62d&dn=ai2-model release 49c8647f439c324f564651c83bd945c0140c2750 err not sure you should get models like this but enjoy
1. Take pretrained LLMs 2. Prompt with "3.14159265358979323846" 3. ??? (circle size == pretraining tokens)

Graded: x.com/keirp1/status/…
Following up on my previous post, I hand-graded held-out* math exams from the recently released Qwen 72B and DeepSeek 67B Base/Chat. It seems like they perform similarly to Claude 2! DeepSeek 67B: 37% GPT-3.5: 41% Qwen 72B: 52% Claude 2: 55% DeepSeek 67B Chat: 56% Grok-1: 59%…