
Felix
@felix_red_panda
speech synthesis and LLM nerd, DMs open, working on LLM stuff at @PrimeIntellect | prev @Aleph__Alpha
Adding multi-level performance models to diagrams. This will allow performance models of FlashAttention / matmul / distributed MoEs to be dynamically calculated. Colors indicate execution at different levels, and the hexagons indicate a partitioned axis.
I solved every single problem in the CUDA mode book. A quick thread summarizing this experience and what I learned 1/x

This matmul visualization is so cool it got me banned last time I posted it
open source speech synthesis model trained on two 4090 GPUs!
Open source notebooklm Today we're open sourcing our 100M voice models that can render conversations. This includes a 40kh base finetune that is capable of voice cloning. Our models can do a variety of non speech sounds! Try them out yourself! ...
Qwen3 0.6b is a shockingly good draft model a lot of the time (96.6% acceptance rate on the 4b model for this particular task!)
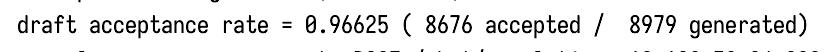
if no one else is showing that RL isn't just eliciting latent behavior already learned in pretraining, but is actually a new scaling paradigm, nvidia has to do it themselves
RL scaling is here arxiv.org/pdf/2505.24864
though the memory bandwidth look looks pretty meh... feels like Intel is trying to make cards with @tenstorrent performance characteristics, though much cheaper(?) xD
Intel a 24GB GPU for ~500 USD, and there will be a single card version with GPU dies and 48GB combined memory
Intel a 24GB GPU for ~500 USD, and there will be a single card version with GPU dies and 48GB combined memory
