Edward Milsom
@edward_milsom
Machine learning PhD student working on deep learning and deep kernel methods. Compass CDT, University of Bristol.
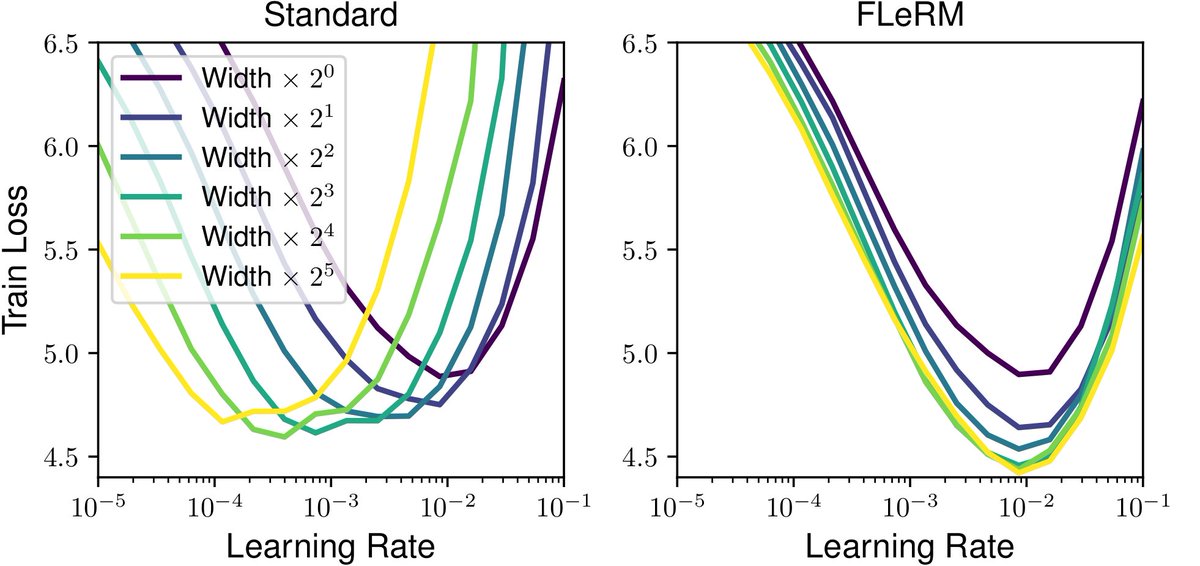
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇

The NeurIPS paper checklist corroborates the bureaucratic theory of statistics. argmin.net/p/standard-err…
What's some "must read" literature on generalisation in neural networks? I keep thinking about this paper and it really makes me want to understand better the link between optimisation and generalisation. arxiv.org/abs/2302.12091
Me: Asks literally any question LLM: Excellent! You're really getting to the heart of computer architecture / electrical infrastructure / The history of Barcelona. Don't flatter me LLM, I am aware of my own limitations, even if you are not.
Is it possible to _derive_ an attention scheme with effective zero-shot generalisation? The answer turns out to be yes! To achieve this, we began by thinking about desirable properties for attention over long contexts, and we distilled 2 key conditions:
This is really a beautiful idea: Autodiff alleviates graduate students' pain from manually deriving the gradient, but MuP-ish work brings the pain back! But this work provides a way that allows you to simply SHUT OFF your brain and get hparam transfer.
To address the "parameterisation lottery" (ideas win because they work well with popular choices of e.g. learning rates) I think empirical hyperparameter transfer methods are crucial. Rules like mu-P require you to derive them first, which is painful... x.com/edward_milsom/…
Happy to announce that my lab has four papers accepted at ICML, including one spotlight:
It seems none of the big open-source models are using mu-P still (correct me if I'm wrong!). According to this it should be quite easy: cerebras.ai/blog/the-pract… Are there any major drawbacks to using mu-P? (I'd be very surprised if Grok wasn't using it because Greg Yang.)

Our position paper on LLM eval error bars has just been accepted to ICML 2025 as a spotlight poster!
Our paper on the best way to add error bars to LLM evals is on arXiv! TL;DR: Avoid the Central Limit Theorem -- there are better, simple Bayesian (and frequentist!) methods you should be using instead. Super lightweight library: github.com/sambowyer/baye… 🧵👇
I talked to a lot of people about "a weight decay paper from Wang and Aitchison" at ICLR, which is officially been accepted at #ICML2025 . Laurence summarized the stuff in our paper in the post, here I will talk about the connection with a *broad* collection of existing works 1/
1/ Super proud of our recent work on how to change the AdamW weight decay as you scale model + dataset size. Or how μP is broken and how to fix it. arxiv.org/abs/2405.13698…
Function-Space Learning Rates has been accepted to ICML 2025! Go read about our paper here: x.com/edward_milsom/…
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇
wow, didnt know cs336 cover scaling things. scaling law, critical bsz, muP and so on. (this lecture slide screenshot is from 2024)
Want to learn the engineering details of building state-of-the-art Large Language Models (LLMs)? Not finding much info in @OpenAI’s non-technical reports? @percyliang and @tatsu_hashimoto are here to help with CS336: Language Modeling from Scratch, now rolling out to YouTube.
Easy (but informative) exercise: Show by induction that an exponential moving average is distributive i.e. EMA(\sum_i X_i)_t = \sum_i EMA(X_i)_t. What EMA initialisation strategies make the base case hold?
There's a lot to process here, but I was pleased to see that Anthropic's 'Circuit Tracing' paper cites three of our recent contributions to the interpretability literature! 1/
For more, read our papers: On the Biology of a Large Language Model contains an interactive explanation of each case study: transformer-circuits.pub/2025/attributi… Circuit Tracing explains our technical approach in more depth: transformer-circuits.pub/2025/attributi…
If you make me president, the login node will have GPUs.
I just wrote my first blog post in four years! It is called "Deriving Muon". It covers the theory that led to Muon and how, for me, Muon is a meaningful example of theory leading practice in deep learning (1/11)