Ibrahim Ahmed
@atbeme
building @inference_net | forever @fdotinc
If you're spending over $25,000 on OpenAI/Gemini/Claude, you need to talk to our team at @inference_net We just finished training a custom model for a leading consumer app that cuts their latency by 70% and their costs by over 50%
we invited 100 students to build instead of study here's what 17 y/os can build: @sashasurk built self correcting liquid glasses @jmoon0714 made a 6ft robot that checks farms for viruses @peps_rp 6 axis 3D printer for aerospace components @alexscraping browserbase that…
Not every LLM request needs an immediate response! We created the Inference Batch API for trillion-scale processing of text, image, and video data using LLMs. Learn more about how to process massive workloads at minimum cost inference.net/blog/batch-vs-…
Pokémon Go style a global effort to place these all over the planet
really cool: bitchat relay powered by the sun.
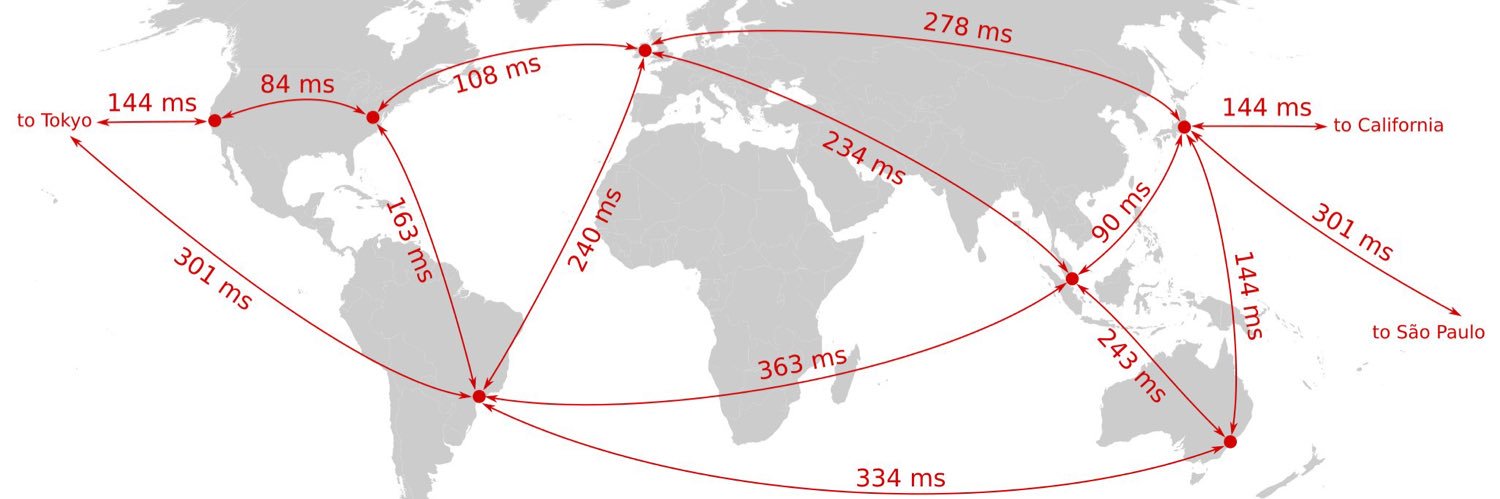
The talented @francescodvirga has moved us from @JaegerTracing over to @SignozHQ and its looking sweeeeeeeeet Telemetry is the name of the game with distributed systems, I can't wait to use this to make our entire pipeline faster @inference_net
Blindly following your curiosity is deeply underrated, creating demos is how we excavate model capabilities, and you have a moral obligation to apply the unique context of your life to further the field of computing. here’s a brief talk I gave on those ideas:
Buy more $NET trust me yall, Matthew is him $1T company within the next 10 years They’ll be as big / bigger than AWS/Azure/GCP (not combined, but they’ll be in that tier)
I'm always amazed by how much smart people still assume that what is today is what will be tomorrow. The question every PM candidate has been asked at Cloudflare since 2012 was: should Cloudflare build a search engine?
Damn MLX > CUDA 🔜 ?!?!
The latest MLX has a CUDA back-end! To get started: pip install "mlx[cuda]" With the same codebase you can develop locally, run your model on Apple silicon, or in the cloud on Nvidia GPUs. MLX is designed around Apple silicon - which has a unified memory architecture. It uses…
Yesterday we completed training of our first custom model that will soon be hosted on inference net! We have another model training in progress, set to finish at the end of this week. These models set the stage for a new chapter of @inference_net, where we scale from billions…
That’s over $30b in GPUs…
MUSK ANNOUNCED THAT NVIDIA'S FIRST BATCH OF 550K GB200S & GB300S FOR XAI'S COLOSSUS 2 SUPERCLUSTER WILL GO ONLINE IN WEEKS
This is exactly how I use Claude code, plus @terragonlabs for background agents
I use CC from Cursor and I assumed most do as well (?). I end up with a mixed thing where Cursor is the UI layer for reading the code, manual edits, tab completion and chunk edits, and CC for larger changes, architecting, Q&A. Still rapidly evolving though...
More founders should be building in public But editing videos distracts from the actual "building" So we built Cursor for video editing • upload 10min of raw footage explaining what you built • ai auto edits into a perfect 1 min product update Weekly update videos coming :)
Introducing: DAWN’s first Black Box partner @inference_net. Proud to partner with a fellow @solana project to make user-owned AI a reality. With a tap in our mobile app, your Black Box will have Intelligence enabled by Inference.net, making you the power behind our AI…