
Aaron Mueller
@amuuueller
Asst. Prof. in CS at @BU_Tweets ≡ {Mechanistic, causal} {interpretability, computational linguistics} ≡ Formerly: PhD @jhuclsp
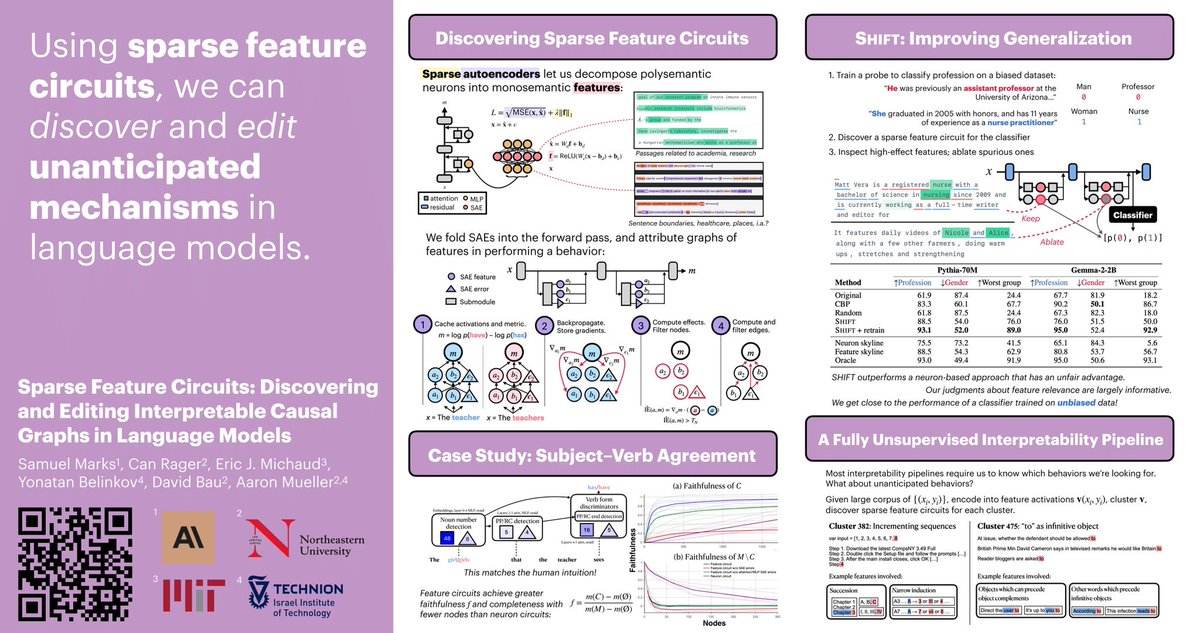
Excited this project is out! Using sparse feature circuits, we can explain and modify how LMs arrive at a behavior. In this thread, I want to highlight open directions where computational linguists can use sparse feature circuits. 🧵
Can we understand & edit unanticipated mechanisms in LMs? We introduce sparse feature circuits, & use them to explain LM behaviors, discover & fix LM bugs, & build an automated interpretability pipeline! Preprint w/ @can_rager, @ericjmichaud_, @boknilev, @davidbau, @amuuueller
We're presenting the Mechanistic Interpretability Benchmark (MIB) now! Come and chat - East 1205. Project led by @amuuueller @AtticusGeiger @sarahwiegreffe
If you're at #ICML2025, chat with me, @sarahwiegreffe, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark. We're planning to keep this a living benchmark; come by and share your ideas/hot takes!

How do language models track mental states of each character in a story, often referred to as Theory of Mind? Our recent work takes a step in demystifing it by reverse engineering how Llama-3-70B-Instruct solves a simple belief tracking task, and surprisingly found that it…
How well can LLMs understand tasks with complex sets of instructions? We investigate through the lens of RELIC: REcognizing (formal) Languages In-Context, finding a significant overhang between what LLMs are able to do theoretically and how well they put this into practice.
BabyLMs first constructions: new study on usage-based language acquisition in LMs w/ @LAWeissweiler, @coryshain. Simple interventions show that LMs trained on cognitively plausible data acquire diverse constructions (cxns) @babyLMchallenge 🧵
Dear MAGA friends, I have been worrying about STEM in the US a lot, because right now the Senate is writing new laws that cut 75% of the STEM budget in the US. Sorry for the long post, but the issue is really important, and I want to share what I know about it. The entire…
We have a new paper up on arXiv! 🥳🪇 The paper tries to improve the robustness of closed-source LLMs fine-tuned on NLI, assuming a realistic training budget of 10k training examples. Here's a 60 second rundown of what we found!
🚨New paper at #ACL2025 Findings! REVS: Unlearning Sensitive Information in LMs via Rank Editing in the Vocabulary Space. LMs memorize and leak sensitive data—emails, SSNs, URLs from their training. We propose a surgical method to unlearn it. 🧵👇w/@boknilev @mtutek 1/8
Our paper "Position-Aware Circuit Discovery" got accepted to ACL! 🎉 Huge thanks to my collaborators🙏 @OrgadHadas @davidbau @amuuueller @boknilev See you in Vienna! 🇦🇹 #ACL2025 @aclmeeting
BlackboxNLP will be co-located with #EMNLP2025 in Suzhou this November! 📷This edition will feature a new shared task on circuits/causal variable localization in LMs, details: blackboxnlp.github.io/2025/task If you're into mech interp and care about evaluation, please submit!
📣Paper Update 📣It’s bigger! It’s better! Even if the language models aren’t. 🤖New version of “Bigger is not always Better: The importance of human-scale language modeling for psycholinguistics” osf.io/preprints/psya…
Close your books, test time! The evaluation pipelines are out, baselines are released and the challenge is on. There is still time to join and we are excited to learn from you on pretraining and the gaps between humans and models. *Don't forget to fast-eval on checkpoints
Presenting sparse feature circuits today at 3pm-5:30pm! Come say hi at poster #495
💡 New ICLR paper! 💡 "On Linear Representations and Pretraining Data Frequency in Language Models": We provide an explanation for when & why linear representations form in large (or small) language models. Led by @jack_merullo_ , w/ @nlpnoah & @sarahwiegreffe