Alex Li
@alexlioralexli
researcher @AnthropicAI. prev @mldcmu, @AIatMeta, @berkeley_ai
Diffusion models have amazing image creation abilities. But how well does their generative knowledge transfer to discriminative tasks? We present Diffusion Classifier: strong classification results with pretrained conditional diffusion models, *with no additional training*! 1/9
Robotic intelligence requires dexterous tool use, but generalizing across tools is hard. Our CoRL23 paper combines semantics (affordances) with low-level control (sim2real) to show functional grasping that generalizes to hammers, drills and more! dexfunc.github.io 1/n
Artifacts in your attention maps? Forgot to train with registers? Use 𝙩𝙚𝙨𝙩-𝙩𝙞𝙢𝙚 𝙧𝙚𝙜𝙞𝙨𝙩𝙚𝙧𝙨! We find a sparse set of activations set artifact positions. We can shift them anywhere ("Shifted") — even outside the image into an untrained token. Clean maps, no retrain.
Excited to be presenting at #ICLR2025 at 10am today on how generative classifiers are much more robust to distribution shift. Come by to chat and say hello!

Are current reasoning models optimal for test-time scaling? 🌠 No! Models make the same incorrect guess over and over again. We show that you can fix this problem w/o any crazy tricks 💫 – just do weight ensembling (WiSE-FT) for big gains on math! 1/N
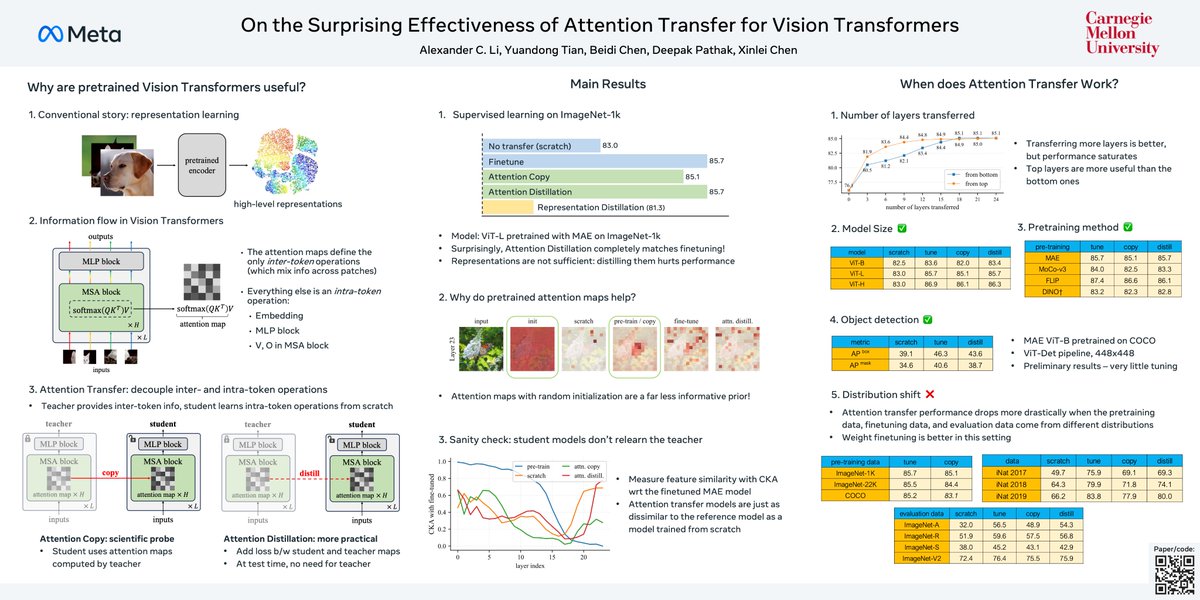
*On the Surprising Effectiveness of Attention Transfer for Vision Transformers* by @tydsh @BeidiChen @pathak2206 @endernewton @alexlioralexli Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning. arxiv.org/abs/2411.09702
Do generative video models learn physical principles from watching videos? Very excited to introduce the Physics-IQ benchmark, a challenging dataset of real-world videos designed to test physical understanding of video models. Webpage: physics-iq.github.io
Have you ever wondered why we don’t use multiple visual encoders for VideoLLMs? We thought the same! Excited to announce our latest work MERV, on using Multiple Encoders for Representing Videos in VideoLLMs, outperforming prior works with the same data. 🧵
I'm presenting our #NeurIPS2024 work on Attention Transfer today! Key finding: Pretrained representations aren't essential - just using attention patterns from pretrained models to guide token interactions is enough for models to learn high-quality features from scratch and…
What happens when you train a video generation model to be conditioned on motion? Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities. Here’s a few examples – check out this thread 🧵 for more results!
Chatbots are often augmented w/ new facts by context from the user or retriever. Models must adapt instead of hallucinating outdated facts. In this work w/@goyalsachin007, @zicokolter, @AdtRaghunathan, we show that instruction tuning fails to reliably improve this behavior! [1/n]
1/ Happy to share VADER: Video Diffusion Alignment via Reward Gradients. We adapt foundational video diffusion models using pre-trained reward models to generate high-quality, aligned videos for various end-applications. Below we generated a short movie using VADER 😀, we used…
Want to scale RL with your shiny new GPU? 🚀 In our ICML24 Oral we find that RL algorithms hit a barrier when data is scaled up. Our new algorithm, SAPG, proposes a simple fix. It scales to 25k envs and solves hard tasks where PPO makes no progress. sapg-rl.github.io 1/n
I’ll be giving an oral presentation today on how generative classifiers are much more robust to distribution shift! (openreview.net/forum?id=02dpw…) Come by to the SPIGM #ICML2024 workshop at 10:40am for my talk or 3:10pm for the poster session!

📝 New from FAIR: An Introduction to Vision-Language Modeling. Vision-language models (VLMs) are an area of research that holds a lot of potential to change our interactions with technology, however there are many challenges in building these types of models. Together with a set…
Did you know that the optimizer Sharpness Aware Minimization (SAM) is very robust to heavy label noise, with gains tens of percent above SGD? In our new work, we deep dive into how SAM achieves these gains. As it turns out, it’s not at all about sharpness at convergence!
What do you see in these images? These are called hybrid images, originally proposed by Aude Oliva et al. They change appearance depending on size or viewing distance, and are just one kind of perceptual illusion that our method, Factorized Diffusion, can make.
Are you interested in jailbreaking LLMs? Have you ever wished that jailbreaking research was more standardized, reproducible, or transparent? Check out JailbreakBench, an open benchmark and leaderboard for Jailbreak attacks and defenses on LLMs! jailbreakbench.github.io 🧵1/n
Have you ever done a dense grid search over neural network hyperparameters? Like a *really dense* grid search? It looks like this (!!). Blueish colors correspond to hyperparameters for which training converges, redish colors to hyperparameters for which training diverges.
🤖 VIRL 🌎 Grounding Virtual Intelligence In Real Life 🧐How can we embody agents in environments as rich/diverse as those we inhabit, without real hardware & control constraints? 🧐How can we ensure internet-trained vision/language models will translate to real life globally?
🌎 𝕤𝕒𝕪 𝕙𝕖𝕝𝕝𝕠 𝕥𝕠 𝕧𝕚𝕣𝕝 🌏 virl-platform.github.io
Can we use motion to prompt diffusion models? Our #ICLR2024 paper does just that. We propose Motion Guidance, a technique that allows users to edit an image by specifying “where things should move.”