
Alexander Long
@_AlexanderLong
Founder @PluralisHQ | ML PhD Protocol Learning: Multi-participant, low-bandwidth model parallel
When I started Pluralis I thought it was going to take 2-3 years and several papers to get to this point. I was considered borderline delusional to hold that view. Well: computational graph itself is split over nodes. Nodes are physically in different continents. 8B model. No…
Almost exactly 1 year ago today Pluralis set out to solve a very difficult problem. We are pleased to announce an update on that problem. We can now combine small consumer devices, connected via the internet, to train giant models. Full paper release in 72 hours.
Welcome to DeAI Summer. My op ed in @coindesk on the progress we're making in decentralized AI. coindesk.com/opinion/2025/0…
pretraining is an elegant science, done by mathematicians who sit in cold rooms writing optimization theory on blackboards, engineers with total absorb of distributed systems of titanic scale posttraining is hair raising cowboy research where people drinking a lot of diet coke…
Missing the point that it'll be a system who's behaviour is controlled by a few people, in companies that don't have the best track record when it comes to this kind of thing. It's fundamentally a level of power that's never existed before it's that simple.
Sam Altman says people are growing emotionally overreliant on AI especially young people who can't make any decisions without ChatGPT Imagine a U.S president or CEO handing control to a system they don't fully understand: "ChatGPT-7, you're in charge. Good luck."
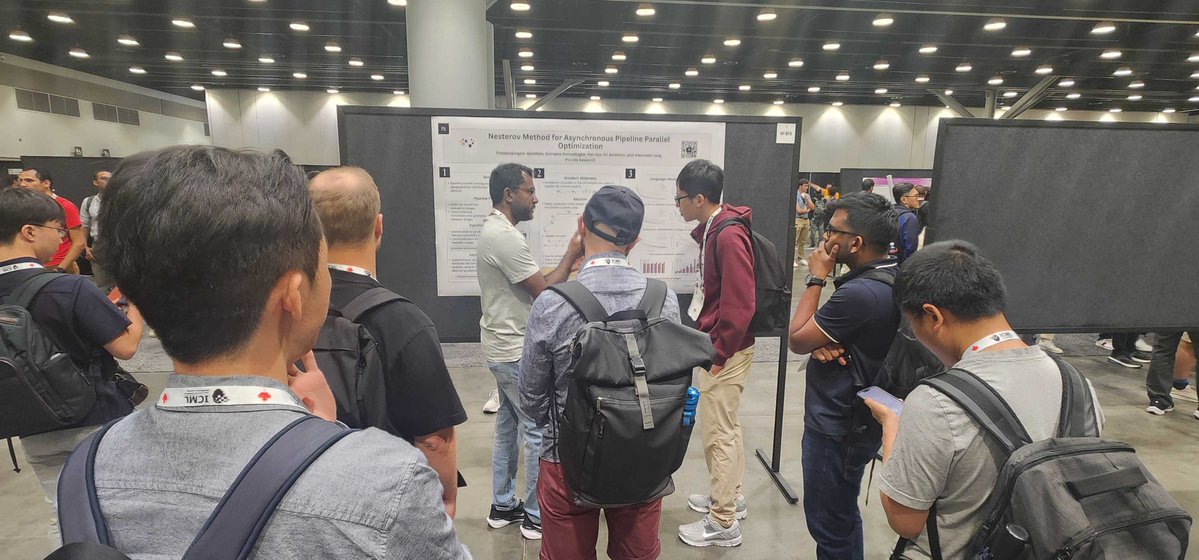
Thats a wrap for ICML2025. Incredible to watch the space go from "What are you talking about" to "That's impossible" to "Hmmm thats very interesting" in just over a year. @tha_ajanthan @hmdolatabadi



Jack Dorsey says AI must be permissionless because constraint kills innovation. Five CEOs shouldn't dictate what brings humanity forward. Open source is the answer. To protect ourselves, we have to race ahead. Eliminating single points of failure before they become…
If you claim to have seen this coming, you better have the manifold P&L to back it up
Noam tends to not exaggerate.
Where does this go? As fast as recent AI progress has been, I fully expect the trend to continue. Importantly, I think we’re close to AI substantially contributing to scientific discovery. There’s a big difference between AI slightly below top human performance vs slightly above.
Totally agree - Flower labs another group actively publishing great stuff and now squarely focused on decentralised training. Should be a major datapoint for everyone still skeptical of the area - flower team is as legitimate as it gets and Nic Lane is pretty much top of the…
Congrats on the paper @_AlexanderLong. But your left out @flwrlabs that published a full system (photon) with validated in-the-wild fully decentralized training up to 13B @MLSysConf. Along with a key technique of the decentralized stack (decoupled embeddings) published as an oral…
From my experience, getting a paper on decentralized DL accepted to top-level conferences can be quite tough. The motivation is not familiar to many reviewers, and standard experiment settings don't account for the problems you aim to solve. Hence, I'm very excited to see…
For people not familiar with AI publishing; there are 3 main conferences every year. ICML, ICLR and NeurIPS. These are technical conferences and the equivalent of journals in other disciplines - they are the main publishing venue for AI. The competition to have papers at these…
Feel like meta closing models was very predictable. I explicitly said this would happen last year and explained why (from blog.pluralis.ai/p/article-2-pr…).
RIP to the unicorn AI startups that have zero products, zero foundation models, and were just going to depend on big labs releasing open-source models for free to model merge. I know one or two.
Hidden in the article "Furthermore, there have been some billion dollar offers that were not accepted by researcher/engineering leadership at OpenAI." I believe if @dylan522p wrote it that its true... but how can that be possible?
Zucc confirms that they are building multiple GW clusters. 1000MW Prometheus will come online in 2026 and Hyperion will be built in phases and be able to scale to 5000MW+. For context, the largest H100/H200 clusters operational today is only 150-200MW. Link to full article below…
Spoke 50 minutes straight to a packed room of cracked AI researchers at ICML, presenting work by @akashnet_, @PrimeIntellect, @gensynai, @NousResearch, @PluralisHQ, and @GoogleDeepMind. There is now an enormous interest in DeAI. Mission (Partially) Accomplished.
@gregosuri LIVE at #ICML2025 on “Distributed Computing Architectures as a Solution to AI's Energy Crisis: Empirical Analysis of Decentralized Training”
People forget Policy Gradient based RL is the most data-inefficient form of training. Going to be major algorithmic advances in RL'ing the base models, probably using something like artificial curiosity (arxiv.org/pdf/1705.05363). But the current methods are not there.
Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly…
For people not familiar with AI publishing; there are 3 main conferences every year. ICML, ICLR and NeurIPS. These are technical conferences and the equivalent of journals in other disciplines - they are the main publishing venue for AI. The competition to have papers at these…
Pluralis has a main tack paper at ICML this week and the team is in Vancouver running several events. The best will be the Open Source Mixer we're running with @gensynai and @akashnet_ Thursday night. For anyone interested in decentralised training it should be a great evening.…
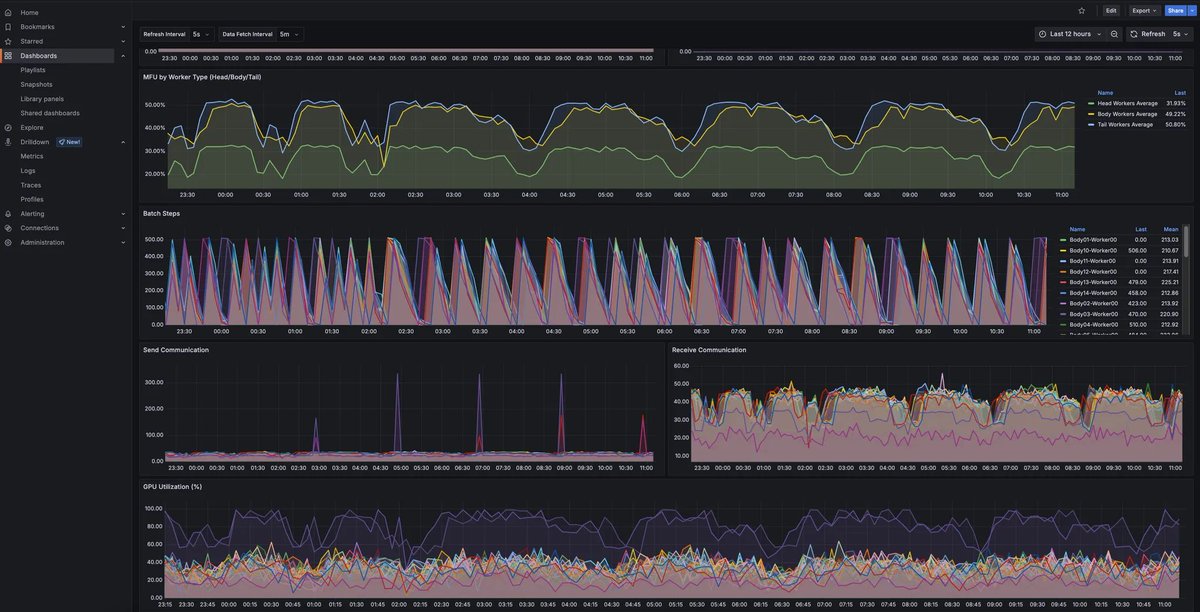
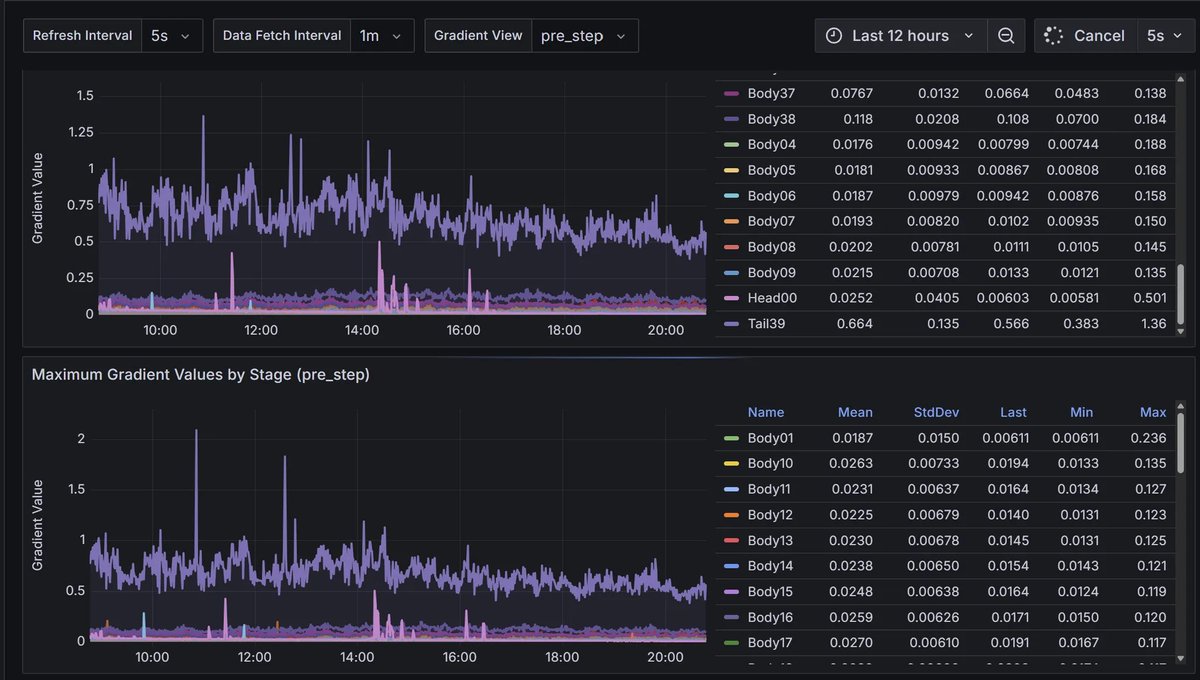
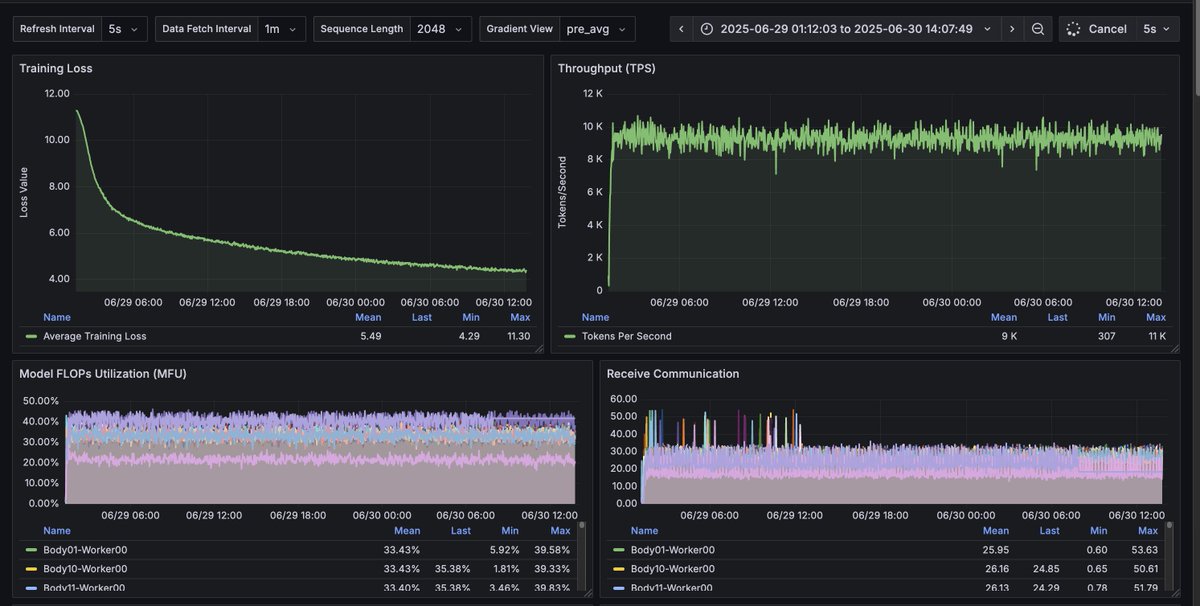
Using beautiful Grafana dashboards for everything internally, so much nicer than Tensorboard. Wandb still good but doesn't really work with decentralised training. Makes me wonder what the internal vis tooling is like in openai - must be incredible.

In Dec 2023 I spent like 3 days non stop compulsively reading all of Max's papers. SWARM had 1 citation at that point. No one I talked to had ever heard of it. Decided to start Pluralis after reading. Only other time I ever felt like that was 2015 when I learned about RL.
The research paper video review on "Swarm Parallelism" along with the author @m_ryabinin, Distinguished Research Scientist @togethercompute is now out ! Link below 👇 For context, most decentralized training today follows DDP-style approaches requiring full model replication on…
Here’s an accessible breakdown of @PluralisHQ’s incredible paper. When we train large models on decentralized networks, the idea is to break them down into pieces and have different nodes process the different pieces. There are a few ways to do this. One way is low hanging…
We've reached a major milestone in fully decentralized training: for the first time, we've demonstrated that a large language model can be split and trained across consumer devices connected over the internet - with no loss in speed or performance.