
Zain
@ZainHasan6
AI builder & teacher | ai/ml http://Together.AI | @UofT eng ℕΨ | ex-vector DBs, health tech & lecturer | decoding AI’s future - follow for insights! 🇨🇦🇵🇰

It's wild how hard a BM25 + reranker baseline is to beat for long context retrieval.🔥 BM25, is pretty similar to vanilla keyword frequency based retrieval but gives you surgical control through just 2 additional params: ◆ k₁ (1.2-2.0): term frequency saturation - prevents…

to do list: - read the Kimi K2 tech report - play with Qwen3 2507 - play with Qwen3 480b coder - ... Can we like evenly distribute these launches guys?

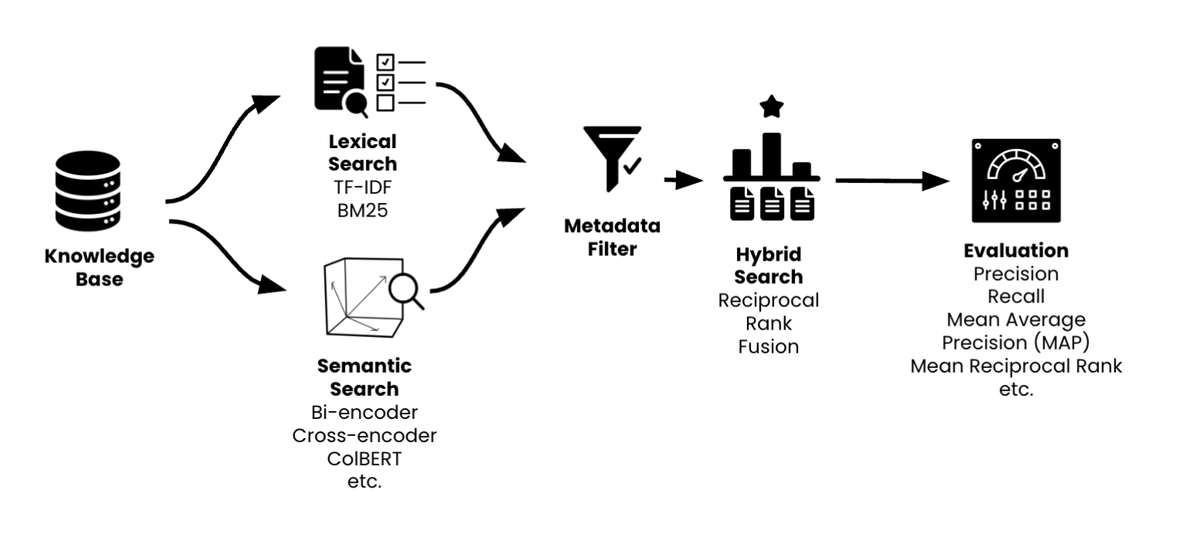
Deep dive into RAG architecture from our course with @AndrewYNg and @ZainHasan6 🧠 This 2-minute snippet covers the foundational patterns for building retrieval-augmented systems.
Kimi K2 tech report just dropped! Quick hits: - MuonClip optimizer: stable + token-efficient pretraining at trillion-parameter scale - 20K+ tools, real & simulated: unlocking scalable agentic data - Joint RL with verifiable + self-critique rubric rewards: alignment that adapts -…
First Kimi-K2 and now an upgraded Qwen3!? Things are heating up! 🔥 Excited by the focus on improving these models for function calling and agentic use cases.
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507! After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing…
Test-time scaling is cool, but ya know what's cooler than getting the right answer in 10k tokens? Getting it in 10...
Most people obsess over embeddings, but good RAG retrievers actually combine 3 components: 1️⃣ Semantic search (embedding magic✨) 2️⃣ Keyword search (boring but reliable) 3️⃣ Metadata filtering (rule-based gates) You'd be surprised how much you can gain from simple filtering.
BFCL v4! 🔥
📢 Big update: Introducing BFCL V4 Agentic — and BFCL published at ICML 2025! 🏟️ Some BFCL lore... back in 2022, as researchers we couldn't find good open-source models that could handle zero-shot function calling — so we decided to train our own. Sounds simple, right? It was!…
🔮Exciting new benchmark testing how well AI predicts the future! Each week, we curate news + prediction markets for questions about next week. Then we have agents make forecasts. Requires advanced research + reasoning @togethercompute @huggingface 📜together.ai/blog/futureben… 🌐…
Most AI benchmarks test the past. But real intelligence is about predicting the future. Introducing FutureBench — a new benchmark for evaluating agents on real forecasting tasks that we developed with @huggingface 🔍 Reasoning > memorization 📊 Real-world events 🧠 Dynamic,…
Can LLMs predict the future? In FutureBench, friends from @togethercompute create new questions from evolving news & markets: As time passes, we'll see which agents are the best at predicting events that have yet to happen! 🔮 Also cool: by design, dynamic & uncontaminated eval