
Yung-Sung Chuang
@YungSungChuang
PhD student @MIT_CSAIL | Intern @MetaAI @Microsoft @MITIBMLab | BS @NTU_SPML in #Taiwan
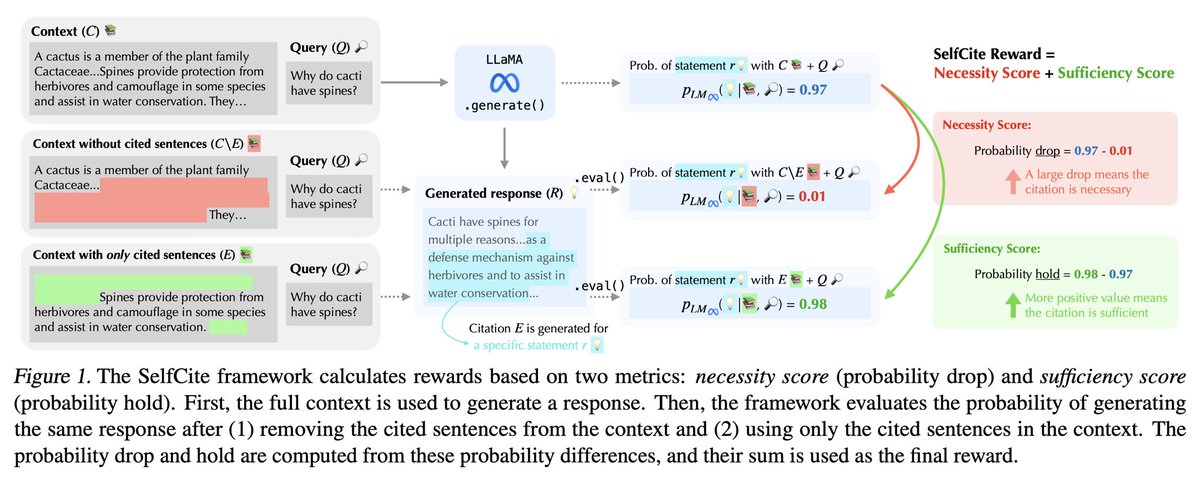
(1/5)🚨LLMs can now self-improve to generate better citations✅ 📝We design automatic rewards to assess citation quality 🤖Enable BoN/SimPO w/o external supervision 📈Perform close to “Claude Citations” API w/ only 8B model 📄arxiv.org/abs/2502.09604 🧑💻github.com/voidism/SelfCi…

🚨How to get in-context attribution for LLMs’ generation at no extra cost?🤔 💪Check out our latest work—AT2! We made LLM attentions faithful again by learning head coefficients📊 ➡️Awesome RAG demo page to get LLM answers with citations, at no latency! bencw99.github.io/at2-citations/
It can be helpful to pinpoint the in-context information that a language model uses when generating content (is it using provided documents? or its own intermediate thoughts?). We present Attribution with Attention (AT2), a method for doing so efficiently and reliably! (1/8)
💡Bridging speech, sound, & music representations with one universal model? We introduce USAD ✅ 📚 Distills knowledge from domain-specific SSL models 🎯 Matches expert models across speech/audio/music tasks 📄 arxiv.org/abs/2506.18843 🧑💻 huggingface.co/MIT-SLS/USAD-B…
Search-augmented LLMs 🌐 are changing how people ask, judge, and trust. We dropped 24k+ real human battles ⚔️ across top models. Wanna know what people actually ask and what they want in return? Check out the paper + dataset 👇
We release Search Arena 🌐 — the first large-scale (24k+) dataset of in-the-wild user interactions with search-augmented LLMs. We also share a comprehensive report on user preferences and model performance in the search-enabled setting. Paper, dataset, and code in 🧵
We know Attention and its linear-time variants, such as linear attention and State Space Models. But what lies in between? Introducing Log-Linear Attention with: - Log-linear time training - Log-time inference (in both time and memory) - Hardware-efficient Triton kernels
Do you really need audio to fine-tune your Audio LLM? 🤔 Answer below: Introducing Omni-R1, a simple GRPO fine‑tuning method for Qwen2.5‑Omni on audio question answering. It sets new state‑of‑the‑art accuracies on the MMAU benchmark for Audio LLMs. arxiv.org/abs/2505.09439
SelfCite is now accepted by ICML 2025! 🎉 See you in Vancouver! 🇨🇦
(1/5)🚨LLMs can now self-improve to generate better citations✅ 📝We design automatic rewards to assess citation quality 🤖Enable BoN/SimPO w/o external supervision 📈Perform close to “Claude Citations” API w/ only 8B model 📄arxiv.org/abs/2502.09604 🧑💻github.com/voidism/SelfCi…
Thrilled to share the first-ever search leaderboard with @lmarena_ai! It's so fun to see how models behave differently — @OpenAI loves news (but not YT), @perplexity_ai favors YouTube, and Gemini (@GoogleDeepMind) leans on blogs/forums. More insights: blog.lmarena.ai/blog/2025/sear…
Exciting News! Search Arena Leaderboard🌐 🥇 Gemini-2.5-Pro-Grounding and Perplexity-Sonar-Reasoning-Pro top the leaderboard! Congrats @GoogleDeepMind and @perplexity_ai! 📊 We've open-sourced 7k battles with user votes! 📝 Check out our blog post for detailed analysis. Blog…
1/ 🎉 Excited to share our latest work — accepted to #ICLR2025 and featured in MIT News today! 🗞️ MIT News: news.mit.edu/2025/new-metho… 📄 Paper: arxiv.org/pdf/2410.04315 🧵 Thread 👇
Please follow our MIT NLP new account! 🧠
Hello everyone! We are quite a bit late to the twitter party, but welcome to the MIT NLP Group account! follow along for the latest research from our labs as we dive deep into language, learning, and logic 🤖📚🧠
LLMs are increasingly used as agents that interact with users. To do so successfully, LLMs need to form beliefs and update them when new information becomes available. Do LLMs do so as expected from an optimal strategy? If not, can we get them to follow this strategy? 🧵
Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵
#ICLR2025 Complex reasoning is often cited as a key capability of language models. However, the term "complex" remains loosely defined, as existing studies have not provided a quantitative framework for measuring the difficulty of reasoning tasks. We attempted to fill this gap.