Xihui Liu
@XihuiLiu
Assistant Professor @ HKU. Previous Postdoc @ UC Berkeley and PhD @ CUHK MMLab
Excited to share that Moto is accepted by #ICCV2025 as Oral presentation! Big congrats to @ChenYi041699 and many thanks to collaborators @tttoaster_ @ge_yixiao @dingmyu @yshan2u
Introducing Moto: Latent Motion Token as the Bridging Language for Robot Manipulation. Motion prior learned from videos can be seamlessly transferred to robot manipulation. Code and model released! @ChenYi041699 @tttoaster_ @ge_yixiao @dingmyu @yshan2u chenyi99.github.io/moto/
🚀 Big thanks to AK for featuring our work! We're thrilled to share this with the community. 🎉 📢 Great news - the code and data is now open source! We welcome everyone to explore, contribute, and collaborate. github.com/OpenRobotLab/S…
StreamVLN Streaming Vision-and-Language Navigation via SlowFast Context Modeling
🎉Our paper DreamCube is accepted to #ICCV2025 ! Thank @_akhaliq for sharing our work! Project page: yukun-huang.github.io/DreamCube/ Code: github.com/yukun-huang/Dr… Model: huggingface.co/KevinHuang/Dre… Video: youtube.com/watch?v=7x4Elc… Special thanks to my co-authors: @XihuiLiu @KaiyiHUANG84276
DreamCube 3D Panorama Generation via Multi-plane Synchronization
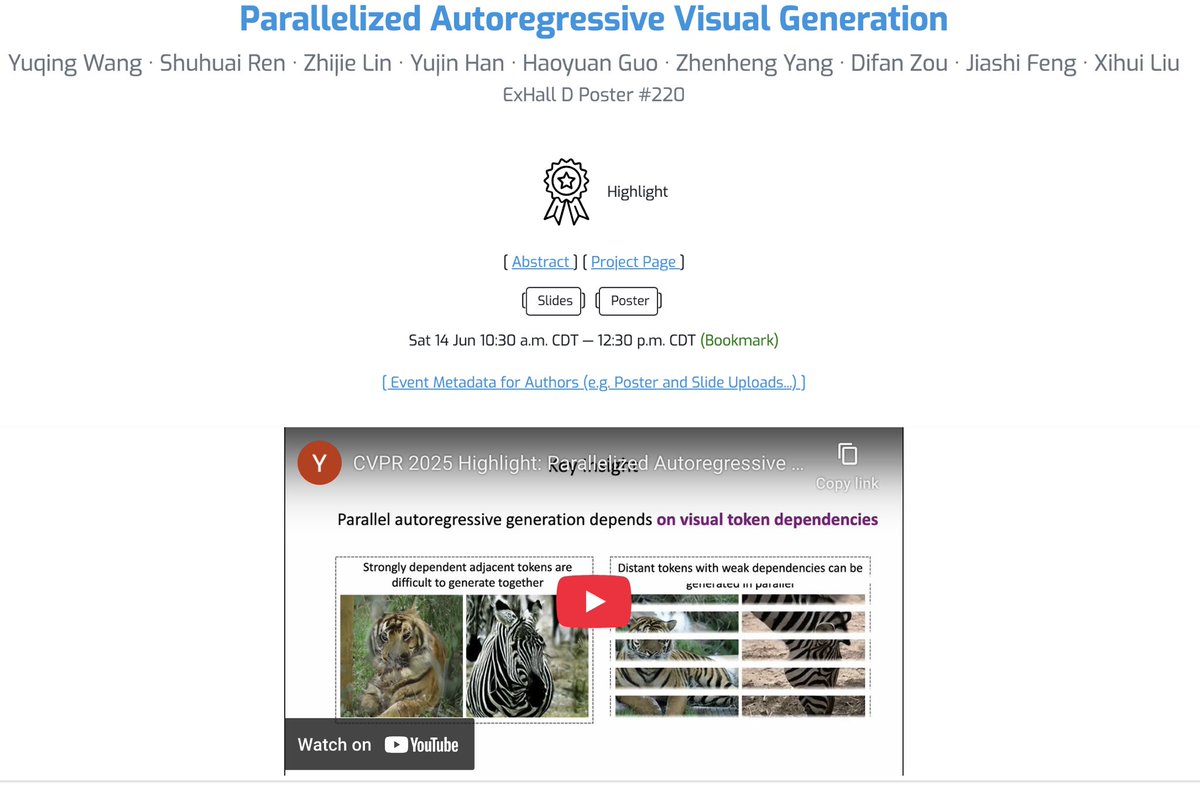
#CVPR2025 We will present our CVPR Highlight Parallelized Autoregressive Visual Generation (arxiv.org/abs/2412.15119) at ExHall D #220 this morning. Also welcome to chat about our recent work TokenBridge: Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation

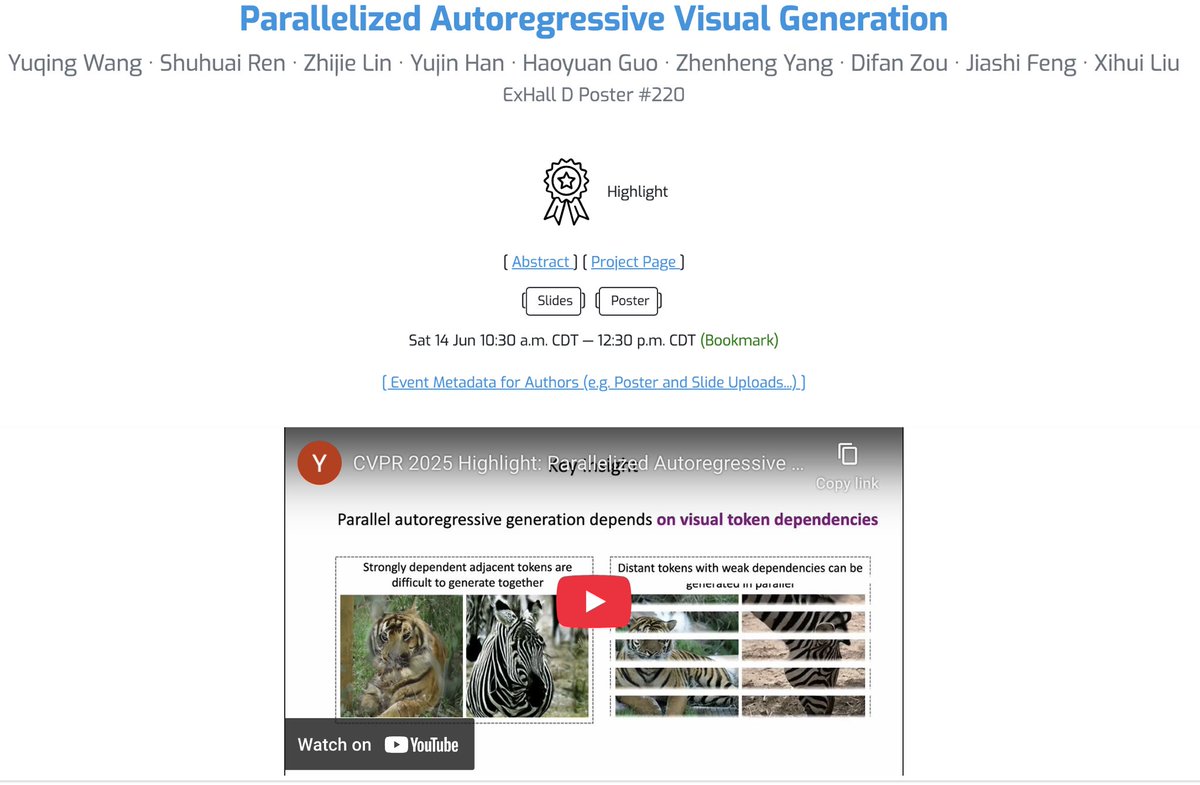

I am at #CVPR2025 this week looking forward to chat: Parallelized Autoregressive Visual Generation (Highlight yuqingwang1029.github.io/PAR-project/),Sat 10:30 am #220 T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation (t2v-compbench-2025.github.io) Fri 4:00 pm #290

The WorldModelBench workshop is happening tomorrow (June 12th) at #CVPR2025! We have an exciting series of talks, do attend! Place: Room 108 Time: Morning Session #NVIDIAResearch
Join us at the WorldModelBench workshop at #CVPR2025 where we'll tackle systematic evaluation of World Models! Focus: benchmarks, metrics, downstream tasks, and safety. Submit papers now: worldmodelbench.github.io
Excited to be presenting our new work–HMAR: Efficient Hierarchical Masked Auto-Regressive Image Generation– at #CVPR2025 this week. VAR (Visual Autoregressive Modelling) introduced a very nice way to formulate autoregressive image generation as a next-scale prediction task (from…
Thank TwelveLabs for organizing and inviting us! My Ph.D. student, Ms. Yi Chen, will share our recent research on benchmarking and improving the reasoning abilities of multimodal LLMs. May 30, 2025 Fri 9:30-10:30 AM PST Registration: mailchi.mp/twelvelabs/mul…
In the 85th session of #MultimodalWeekly, we have 3 exciting presentations on multimodal state-space models, multimodal reasoning, and multi-grained video editing.
Introducing GoT-R1, which enhances visual generation by using reinforcement learning to improve semantic-spatial chain-of-thought reasoning. Code available! Arxiv: arxiv.org/abs/2505.17022 Code: github.com/gogoduan/GoT-R1 huggingface.co/papers/2505.17…

(2/2) We release a survey of Interactive Generative Video (IGV). Paper: arxiv.org/abs/2504.21853 2. Framework of IGV, consisting of five main components: Generation, Control, Memory, Dynamics and Intelligence. Research work from @Kling_ai.
Excited to release the survey of interactive generative videos!
(1/2) We release a survey of Interactive Generative Video (IGV). Paper: arxiv.org/abs/2504.21853 1. Evolutionary tree of IGV, focusing on its applications in: Game Simulation, Embodied AI, and Autonomous Driving Thank coauthors: @yujiwenHK, @QuandeLiu, @wanfufeng, @XihuiLiu
Arrived at Singapore! Tengyao will present our work SJD in #ICLR tomorrow! Welcome to chat with us at Poster #161 tomorrow morning 10:00-12:30.
AR-based visual generative models have attracted great attention, but their inference is much slower than diffusion-based models. We propose Speculative Jacobi Decoding (SJD) to accelerate auto-regressive text-to-image generation. huggingface.co/papers/2410.01… arxiv.org/pdf/2410.01699
Why are discrete visual tokenizers difficult to scale? In GigaTok, we study the key factors for scaling tokenizers, and scale VQ tokenizers to 3B for better reconstruction, AR generation, and representation. Code and models released huggingface.co/papers/2504.08… silentview.github.io/GigaTok/

Check out our latest work SEED-Bench-R1!
🚀 Introducing SEED-Bench-R1: RL (GRPO) shines🌟 — but reveals critical gaps between perception and reasoning! 🔗 arxiv.org/pdf/2503.24376 💻 github.com/TencentARC/SEE… - 📹 Real-world egocentric videos - 🧠 Tasks balancing perception + logic - 📊 Rigorous in-distribution/OOD splits
My Ph.D. student, Mr. Tianwei Xiong, will introduce our long-take video dataset LVD-2M (NeurIPS 2024) in this webinar. silentview.github.io/LVD-2M/ arxiv.org/pdf/2410.10816
Correct webinar thumbnail here!
Excited to introduce our new work TokenBridge. We hope to inspire a new pathway to autoregressive visual generation by bridging discrete and continuous tokens. arxiv.org/abs/2503.16430 github.com/yuqingwang1029… yuqingwang1029.github.io/TokenBridge/ huggingface.co/papers/2503.16…
