
Run-Ze Fan
@Vfrz525_
Incoming PhD student @UMassAmherst. Research Assistant@GAIR Lab @sjtu1896. NLP/LLMs. | Prev @ucas1978
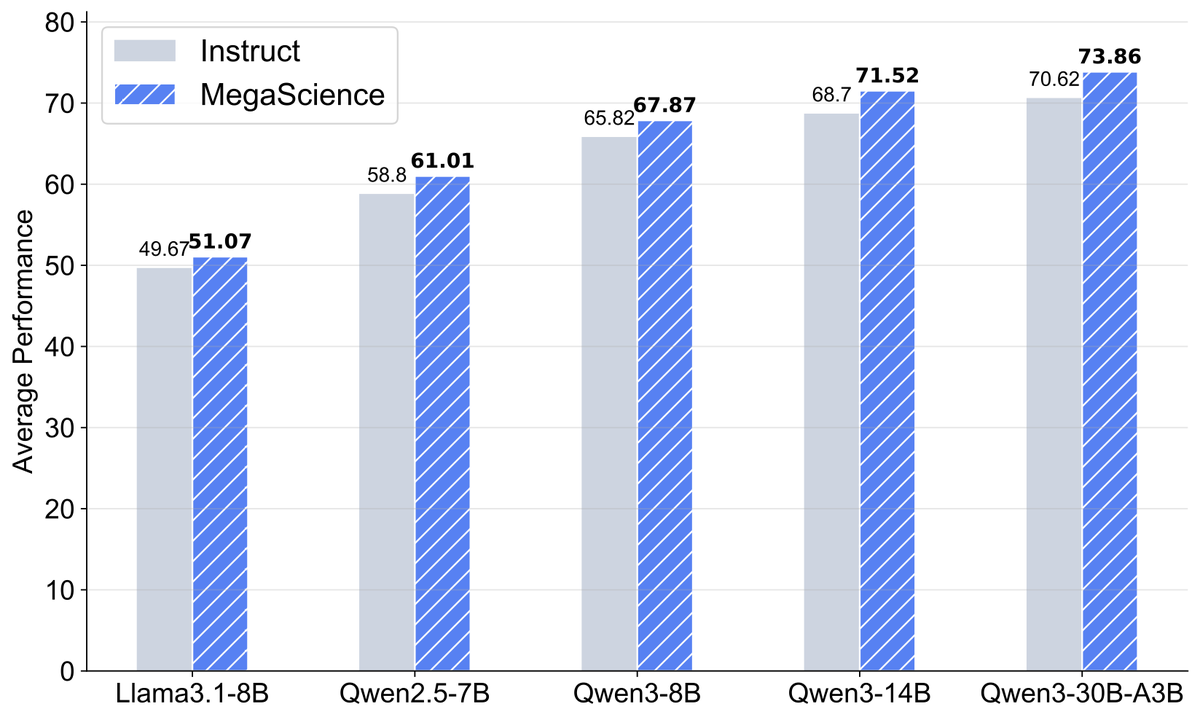
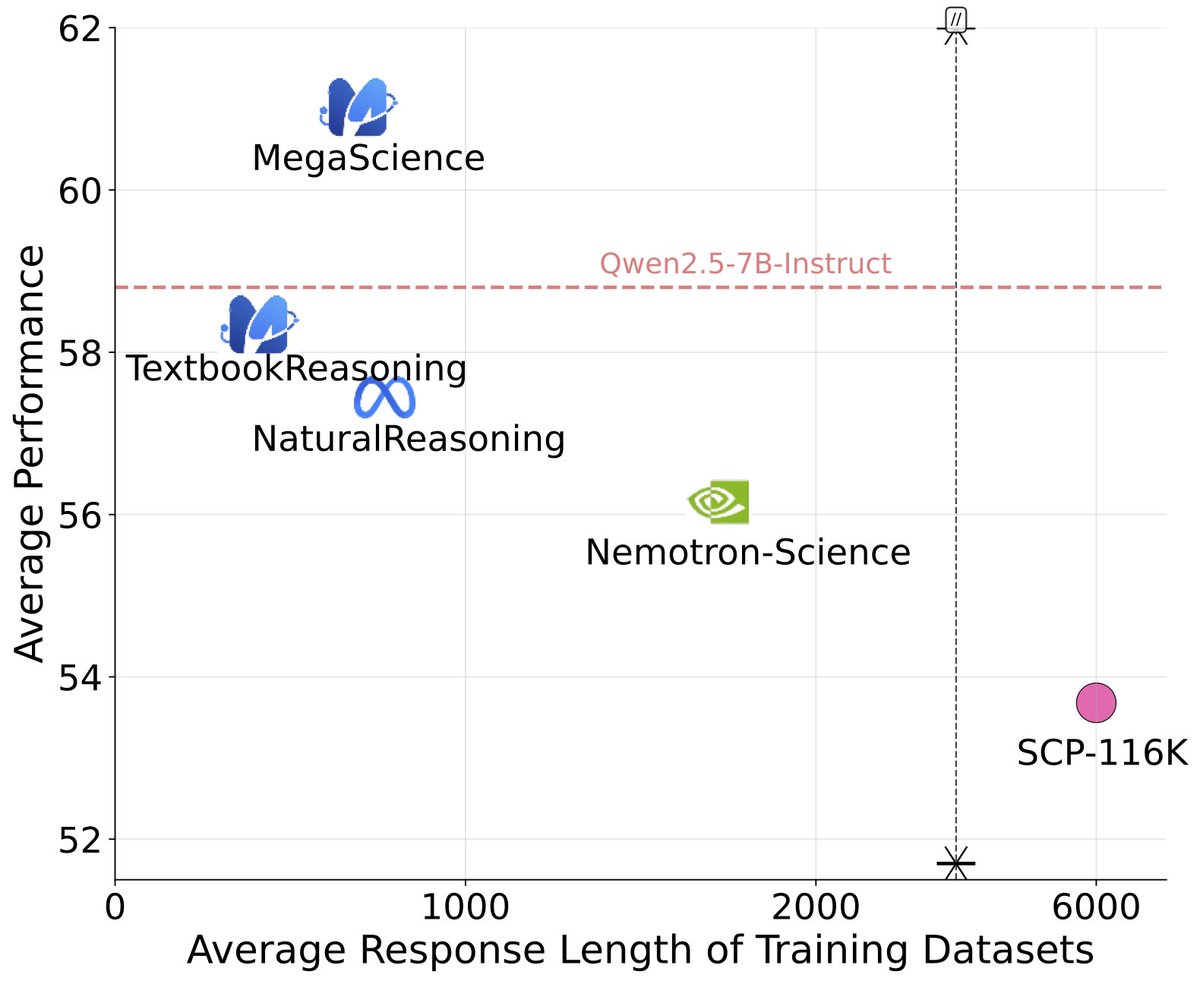
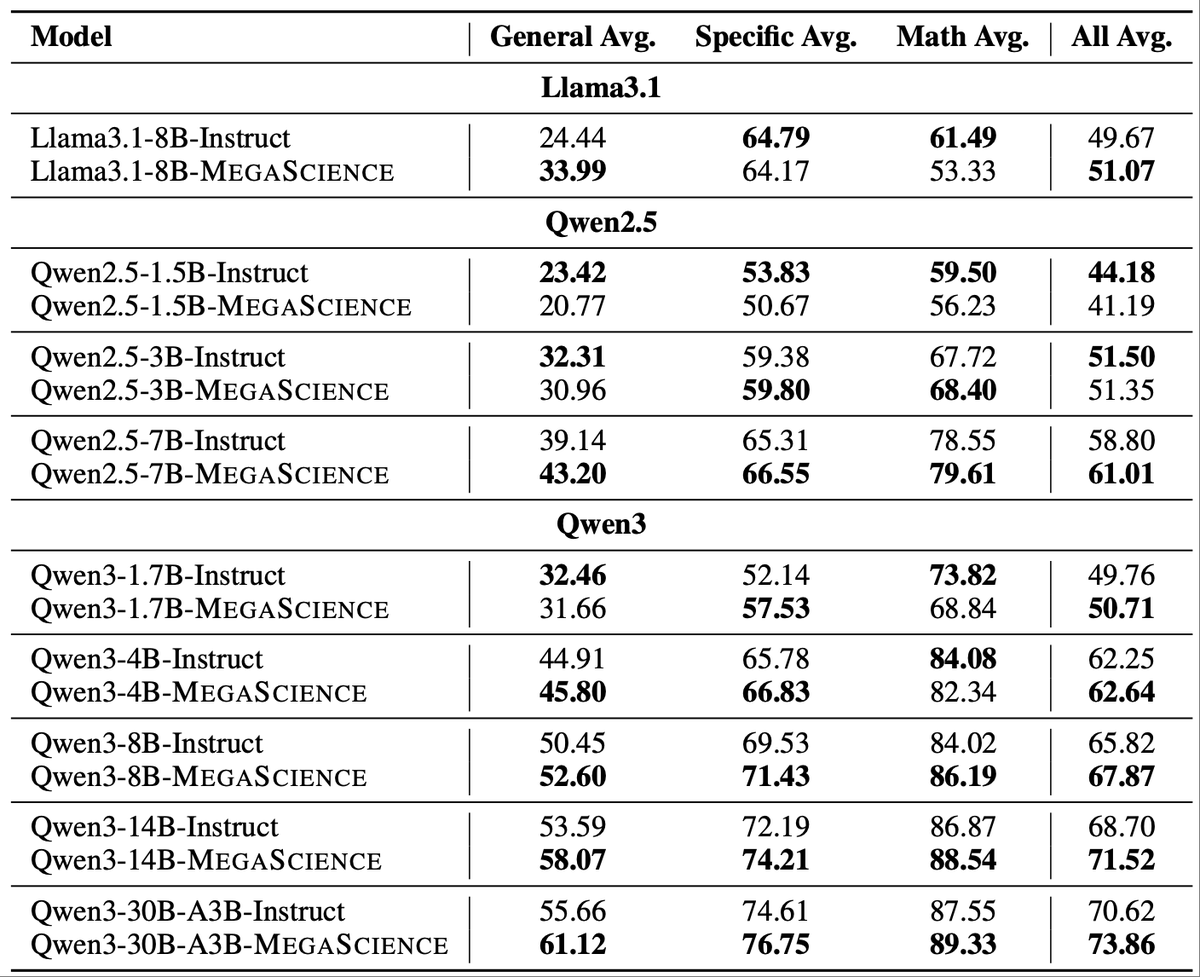
🚨 New release: MegaScience The largest & highest-quality post-training dataset for scientific reasoning is now open-sourced (1.25M QA pairs)! 📈 Trained models outperform official Instruct baselines 🔬 Covers 7+ disciplines with university-level textbook-grade QA 📄 Paper:…
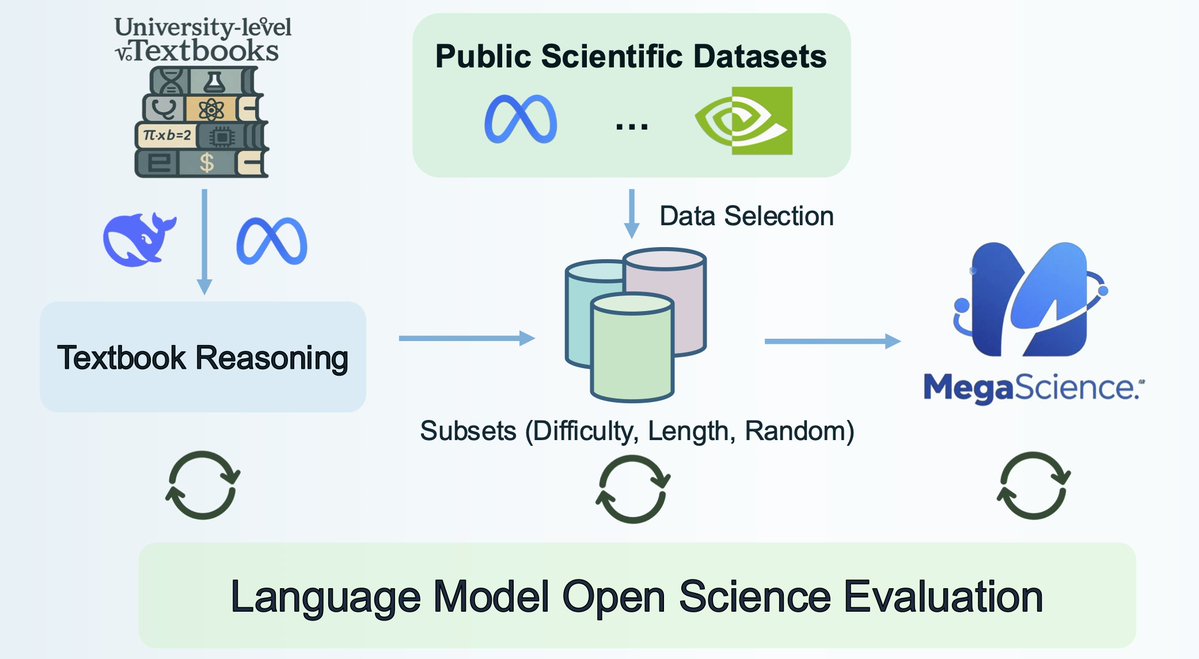
When building MegaScience, we learned the hard way: 📈 Strong datasets need strong proxy models. Our data was too spicy 🌶️ for small models like Qwen2.5-1.5B & 3B—they just flopped. But once we tried Qwen3-14B and 30B… boom 💥, everything clicked. Kinda terrifying to think: if…
🚨 New release: MegaScience The largest & highest-quality post-training dataset for scientific reasoning is now open-sourced (1.25M QA pairs)! 📈 Trained models outperform official Instruct baselines 🔬 Covers 7+ disciplines with university-level textbook-grade QA 📄 Paper:…
Thank you very much for your sharing!!! Check out our resources: Datasets & Models: huggingface.co/MegaScience Code base: github.com/GAIR-NLP/MegaS… Scientific Evaluation System: github.com/GAIR-NLP/lm-op…
MegaScience Pushing the Frontiers of Post-Training Datasets for Science Reasoning
🥳Happy to share that our paper "Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception" has been accepted by #ACL2025! We explore leveraging LLMs' internal states to improve their knowledge boundary perception from efficiency and risk perspectives.
Good work. It seems that long cot pre-training has a significant impact on RL.
I believe that we need a deeper understanding of the relationship between pre-training and RL scaling. How to perform pre-training better, making language models more suitable and smooth for RL scaling? That is to say, Pre-training for RL. If you are interested in it, welcome to…
🔥 Excited to share our work "Efficient Agent Training for Computer Use" Q: Do computer use agents need massive data or complex RL to excel? A: No, with just 312 high-quality trajectories, Qwen2.5-VL can outperform Claude 3.7, setting a new SOTA for Windows computer use. 1/6
Curious about the next paradigm shift in AI? Step into Generative AI Act II: Test Time Scaling Drives Cognition Engineering. We built this bilingual, research-meets-practical guide to Cognitive Engineering. Big ideas, tutorials, and code included. arxiv: arxiv.org/abs/2504.13828
🔥 Happy to share our paper on test-time scaling (TTS)! 🚀 We take the position that generative AI has entered Act II, that is cognition engineering driven by TTS. 🛠️ We provide many valuable resources to help community utilize TTS to develop the cognitive ability of models.
🥁🥁 Happy to share our latest efforts on math pre-training data, the MegaMath dataset! This is a 9-month project starting from 2024’s summer, and we finally deliver: the largest math pre-training data to date containing 💥370B 💥tokens of web, code, and synthetic data!
1/🚀Excited to share our AI Realtor project! 🏡 We challenge AI to help sell real estate! This is an interdisciplinary agent work combining economy, personalization & LLM persuasion. More details are below! 👇
📢 Some Updates 📢 We are happy to further release DCLM-pro, a cleaner and larger prox corpus (currently around 500B level) based on the great DCLM-baseline. In our preliminaty training study, the downstream performance on it seems outperform the baseline by 1.7%. We think it…
🚀 Still relying on human-crafted rules to improve pretraining data? Time to try Programming Every Example(ProX)! Our latest efforts use LMs to refine data with unprecedented accuracy, and brings up to 20x faster training in general and math domain! 👇 Curious about the details?
#LIMO: The "Less is More" Law in LLM Reasoning (1) 817 training data with 57.1% AIME: We discovered the "Less is More" law in complex reasoning: In the American Invitational Mathematics Examination (AIME), LIMO's accuracy soared from 6.5% (compared to traditional methods like…
🤔 How many examples does an LLM need to learn competition-level math? Conventional wisdom: 100,000+ examples Our discovery: Just 817 carefully chosen ones 🤩 With pure SFT, LIMO achieves: 57.1% on AIME 94.8% on MATH LIMO: Less is More for Reasoning 📝 🔗 arxiv.org/pdf/2502.03387
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training Shows that: - RL generalizes in rule-based envs, esp. when trained with an outcome-based reward - SFT tends to memorize the training data and struggles to generalize OOD
I've created slides for those curious about the recent rapid progress in linear attention: from linear attention to Lightning-Attention, Mamba2, DeltaNet, and TTT/Titans. Check it out here: sustcsonglin.github.io/assets/pdf/tal…
🤔Dreaming of AI agents that can handle complex work? Frustrated by the endless hunt for agent training data? 🚀Introducing PC Agent & PC Tracker, our human cognition transfer framework enabling AI to perform complex computer tasks: 📹 PC Tracker: the first lightweight…
Check out our scalable PC Agent data annotation framework (combining unsupervised and supervised data) and the training recipes we've developed.
🤔 Struggling to train capable AI agents due to lack of quality data? 🚀 Meet PC Tracker & PC Agent - our groundbreaking system that learns from real human computer operation process to handle complex digital work! Watch how PC Agent automatically creates slides about Attention…
🤔 Struggling to train capable AI agents due to lack of quality data? 🚀 Meet PC Tracker & PC Agent - our groundbreaking system that learns from real human computer operation process to handle complex digital work! Watch how PC Agent automatically creates slides about Attention…
[Long Tweet Ahead] Faculty Interview Tips & Common Questions: 🧘♀️0. Firstly, do not be nervous - Almost everything can be prepared in advance:) - Be grateful for everyone's time. - Think of it as an opportunity to share your research with others -- exciting, right? - Technical…
Sappy thanksgiving post: I believe humans are simply the product of their environment, and so I am thankful for the combined influence of the people I’ve worked with making me the researcher I am. A short history: Ryan Cotterell was the first really strong language AI researcher…
Prediction: within the next year there will be a pretty sharp transition of focus in AI from general user adoption to the ability to accelerate science and engineering. For the past two years it has been about user base and general adoption across the public. This is very…
Interesting work!
In Miami for #EMNLP2024! Come check out our findings poster, Weak-to-Strong Reasoning, on Wednesday at 10:30am. Super excited for my first in-person conference. Looking forward to connecting and chatting about reasoning, hallucination, self-correction, and all things LLMs! 🌴🌴