Hugo
@Mldhug
PhD student in multimodal learning for audio understanding at @telecomparis. Intern @AIatMeta
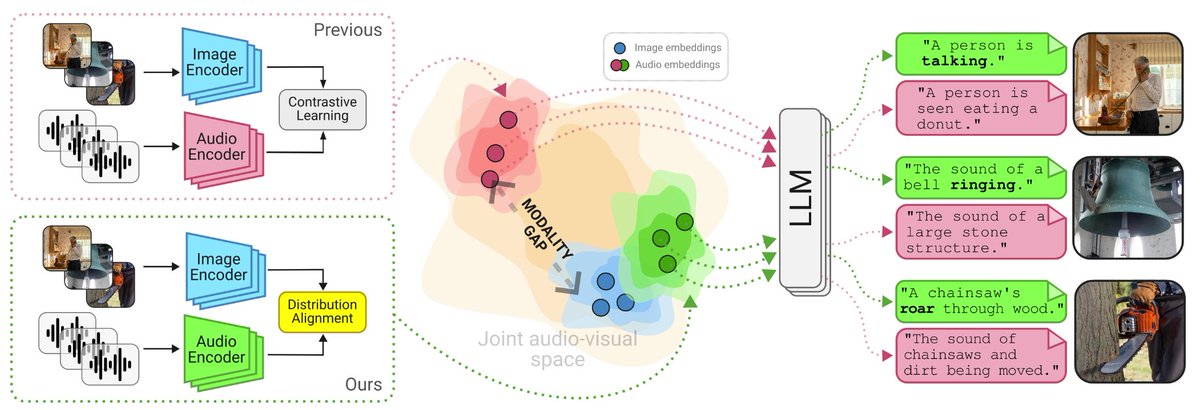
You want to give audio abilities to your VLM without compromising its vision performance? You want to align your audio encoder with a pretrained image encoder without suffering from the modality gap? Check our #NeurIPS2024 paper with @michelolzam @Steph_lat and Slim Essid
We are looking for audio and speech generation people, in Zurich, Paris or London to join our team at Google Deepmind. We build cutting-edge speech, music and audio (also audio-visual) generation capabilities. Reach out to Jason or me if interested. Retweets very appreciated !
Our incredible team built many models announced here, including image, voice, music and video generation! And: I'm moving to London this summer, and I'm hiring for research scientist and engineering roles! Our focus is on speech & music in Zurich, Paris & London. DM/email me.
An Eye for an Ear: Zero-shot Audio Description Leveraging an Image Captioner using Audiovisual Distribution Alignment
If you want to learn more about audio-visual alignment and how to use it to give audio abilities to your VLM, stop by our @NeurIPSConf poster #3602 (East exhibit hall A-C) tomorrow at 11am!
You want to give audio abilities to your VLM without compromising its vision performance? You want to align your audio encoder with a pretrained image encoder without suffering from the modality gap? Check our #NeurIPS2024 paper with @michelolzam @Steph_lat and Slim Essid
Great talk today by @LiuHaohe at the @tp_adasp group on Latent Diffusion Models (LDMs) as versatile audio decoder! Walked us through diffusion basics, AudioLDM for text-to-audio, audio quality enhancement, and neural codecs!
``An Eye for an Ear: Zero-shot Audio Description Leveraging an Image Captioner using Audiovisual Distribution Alignment,'' Hugo Malard, Michel Olvera, St\'ephane Lathuiliere, Slim Essid, ift.tt/lf5BrIC
Given a number of ASR models of different sizes, how can I allocate an audio sample to the smallest one that will be good enough ? @Mldhug worked on this question during his internship, and ended up with interesting conclusions you will find in our paper !
The preprint of our work (with @salah_zaiem and @AlgayresR) on sample dependent ASR model selection is available on arXiv! In this paper we propose to train a decision module, that allows, given an audio sample, to use the smallest sufficient model leading to a good transcription
It's really surprising how far one can go with *linear* predictors in the autoregressive setting. Interesting theory and experiments on TinyStories: a linear model (with 162M params :-) ) can generate totally coherent text with few grammatical mistakes. arxiv.org/abs/2309.06979
Why is Whisper so robust to background noise? Not because Whisper suppresses them, but because Whisper 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐬 them! Check out the amazing work by Yuan Gong @YGongND. They reveal this emergent capability of Whisper, and get SOTA *simultaneous* ASR + audio tagging
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language Looks promising; I'll have to try and see if it stands upto some poking ;-) Love that they get around the need for multimodal training. ar5iv.org/abs/2306.16410 github.com/ContextualAI/l…
DreamDiffusion: Generating High-Quality Images from Brain EEG Signals paper page: huggingface.co/papers/2306.16… paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate…
Super excited to finally launch Voicebox🤩, the most versatile speech generative model ever💬👄 Demo page: voicebox.metademolab.com
Introducing Voicebox, a new breakthrough generative speech system based on Flow Matching, a new method proposed by Meta AI. It can synthesize speech across six languages, perform noise removal, edit content, transfer audio style & more. More details on this work & examples ⬇️
Who killed non-contrastive image-text pretraining? @AlecRad and @_jongwook_kim with the below Fig2 in CLIP. Who collected the 7 Dragonballs and asked Shenron to resurrect it? Yours truly, in this new paper of ours. Generative captioning is not only competitive, it seems better!
Thanks for tweeting, @AK! We’re super excited about the future of text-only vision model selection! 🙏 @MarsScHuang @kcjacksonwang @syeung10
LOVM: Language-Only Vision Model Selection paper page: huggingface.co/papers/2306.08… Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot…
Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration paper page: huggingface.co/papers/2306.09… Although instruction-tuned large language models (LLMs) have exhibited remarkable capabilities across various NLP tasks, their effectiveness on other data…
We'll present GeneCIS at #CVPR2023 (Highlight) TL;DR: While most image representations are *fixed*, we present a general way to train and evaluate models which can adapt to different *conditions* on the fly. Code: github.com/facebookresear… Project page: sgvaze.github.io/genecis/ 🧵
GeneCIS: A Benchmark for General Conditional Image Similarity paper page: huggingface.co/papers/2306.07… argue that there are many notions of 'similarity' and that models, like humans, should be able to adapt to these dynamically. This contrasts with most representation learning…