Liyan Tang
@LiyanTang4
Fourth-year PhD @UTAustin || NLP || MiniCheck || Intern @GoogleDeepMind; Prev Intern @bespokelabsai, @AmazonScience
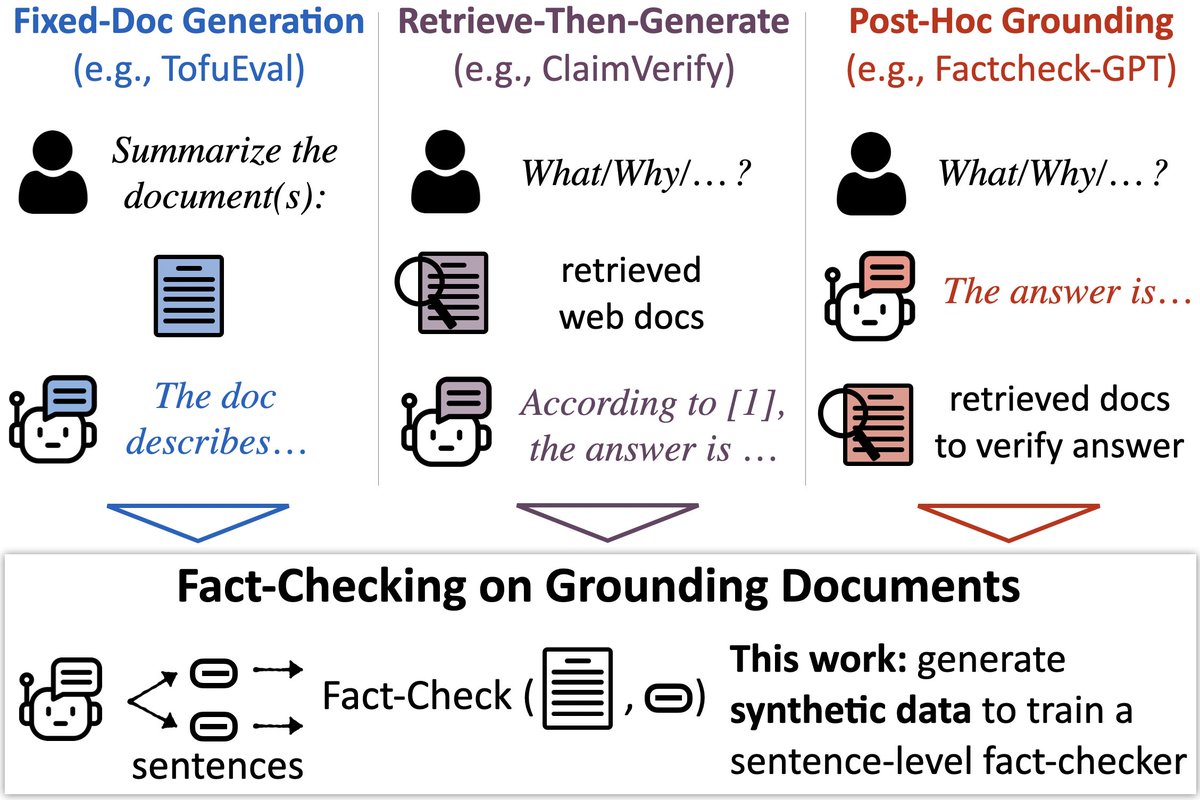
🔎📄New model & benchmark to check LLMs’ output against docs (e.g., fact-check RAG) 🕵️ MiniCheck: a model w/GPT-4 accuracy @ 400x cheaper 📚LLM-AggreFact: collects 10 human-labeled datasets of errors in model outputs arxiv.org/abs/2404.10774 w/ @PhilippeLaban, @gregd_nlp 🧵

Check out Ramya et al.'s work on understanding discourse similarities in LLM-generated text! We see this as an important step in quantifying the "sameyness" of LLM text, which we think will be a step towards fixing it!
Have that eerie feeling of déjà vu when reading model-generated text 👀, but can’t pinpoint the specific words or phrases 👀? ✨We introduce QUDsim, to quantify discourse similarities beyond lexical, syntactic, and content overlap.
LLMs trained to memorize new facts can’t use those facts well.🤔 We apply a hypernetwork to ✏️edit✏️ the gradients for fact propagation, improving accuracy by 2x on a challenging subset of RippleEdit!💡 Our approach, PropMEND, extends MEND with a new objective for propagation.
🤔 Recent mech interp work showed that retrieval heads can explain some long-context behavior. But can we use this insight for retrieval? 📣 Introducing QRHeads (query-focused retrieval heads) that enhance retrieval Main contributions: 🔍 Better head detection: we find a…
Solving complex problems with CoT requires combining different skills. We can do this by: 🧩Modify the CoT data format to be “composable” with other skills 🔥Train models on each skill 📌Combine those models Lead to better 0-shot reasoning on tasks involving skill composition!
The paper is out! arxiv.org/pdf/2505.19462
Announcing the new SotA voice-cloning TTS model: 𝗩𝗼𝗶𝗰𝗲𝗦𝘁𝗮𝗿 ⭐️ VoiceStar is - autoregressive, - voice-cloning, - robust, - duration controllable, - *test-time extrapolation*, generates speech longer than training duration! Code&Model: github.com/jasonppy/Voice…
Check out ChartMuseum from @LiyanTang4 @_grace_kim and many other collaborators from UT! Charts questions take us beyond current benchmarks for math/multi-hop QA/etc., which CoT is very good at, to *visual reasoning*, which is hard to express with text CoT!
Introducing ChartMuseum🖼️, testing visual reasoning with diverse real-world charts! ✍🏻Entirely human-written questions by 13 CS researchers 👀Emphasis on visual reasoning – hard to be verbalized via text CoTs 📉Humans reach 93% but 63% from Gemini-2.5-Pro & 38% from Qwen2.5-72B
🆕paper: LLMs Get Lost in Multi-Turn Conversation In real life, people don’t speak in perfect prompts. So we simulate multi-turn conversations — less lab-like, more like real use. We find that LLMs get lost in conversation. 👀What does that mean? 🧵1/N 📄arxiv.org/abs/2505.06120
🚀Introducing CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️ A dataset of 100 real-world C repositories across various domains, each paired with: 🦀 Handwritten safe Rust interfaces. 🧪 Rust test cases to validate correctness. 🧵[1/6]
New work led by @LiyanTang4 with a strong new model for chart understanding! Check out the blog post, model, and playground! Very fun to play around with Bespoke-MiniChart-7B and see what a 7B VLM can do!
Announcing Bespoke-MiniChart-7B, a new SOTA in chart understanding for models of comparable size on seven benchmarks, on par with Gemini-1.5-Pro and Claude-3.5! 🚀 Beyond its real-world applications, chart understanding is a good challenging problem for VLMs, since it requires…
Check out my work at @bespokelabsai We release Bespoke-MiniChart-7B, a new SOTA in chart understanding of its size Chart understanding is really fun and challenging and requires reasoning skills beyond math reasoning It's a great starting point for open chart model development!
Announcing Bespoke-MiniChart-7B, a new SOTA in chart understanding for models of comparable size on seven benchmarks, on par with Gemini-1.5-Pro and Claude-3.5! 🚀 Beyond its real-world applications, chart understanding is a good challenging problem for VLMs, since it requires…
Check out Manya's work on evaluation for open-ended tasks! The criteria from EvalAgent can be plugged into LLM-as-a-judge or used for refinement. Great tool with a ton of potential, and there's LOTS to do here for making LLMs better at writing!
Evaluating language model responses on open-ended tasks is hard! 🤔 We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️. EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
OpenAI’s o4 just showed that multi-turn tool use is a huge deal for AI agents. Today, we show how to do the same with your own agents, using RL and open-source models. We used GRPO on only 100 high quality questions from the BFCL benchmark, and post-trained a 7B Qwen model to…
Announcing Reasoning Datasets Competition📢in collaboration with @huggingface and @togethercompute Since the launch of DeepSeek-R1 this January, we’ve seen an explosion of reasoning-focused datasets: OpenThoughts-114k, OpenCodeReasoning, codeforces-cot, and more.…
Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe. The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchmarks and almost reaches the performance of DeepSeek-R1-Distill-Qwen-32B while…
Deepseek has done it again! This time, lots of action packed insights, stuff that the top labs are not willing to share. Some insights: 1. "We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step."…
🚀 DeepSeek-R1 is here! ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & technical report 🏆 MIT licensed: Distill & commercialize freely! 🌐 Website & API are live now! Try DeepThink at chat.deepseek.com today! 🐋 1/n