Jake Elder
@Jake_Elder52
Behavioral Scientist @Vanguard_Group | PhD @UCRiverside | BA @UCLA
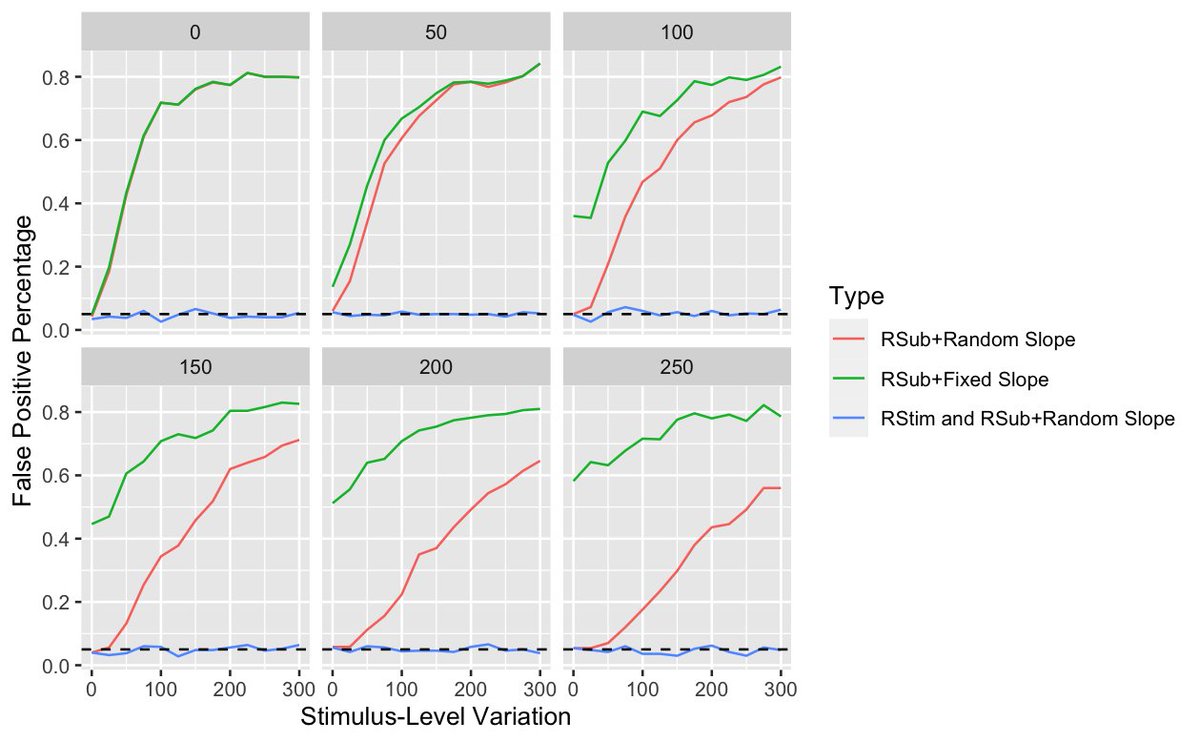
I implemented 3 different types of mixed models and compared false positive rates, while moving the stimulus-level intercept variation and subject-level slope variation (panel). Takeaway: Try to model crossed random effects with stimuli! Omitting stimulus RE inflates FP! #rstats
According to a recent paper, the vast majority of academics gain their elite status the old-fashioned way, they were born with rich parents.
Here is something I suspect happens *a lot*: Researchers have nested data. Run rmANOVA. Don't get significant results. "Hey, how about multilevel models?" Run MLM with only random intercept. Everything is significant. "I guess MLMs have more power!" Publish.
Here is something I suspect happens *a lot*: Researchers have nested data. Run rmANOVA. Don't get significant results. "Hey, how about multilevel models?" Run MLM with only random intercept. Everything is significant. "I guess MLMs have more power!" Publish.
Academics from poorer socio-economic backgrounds are more likely to - not publish - have outstanding publication records - introduce more novel scientific concepts - less likely to receive recognition, as measured by citations, Nobel Prize nominations, and awards.
Do a PhD and free yourself of such concerns
25-30 is such a weird age group. You have to excel in your career, find a life partner, stay healthy and save money.
{effectsize} version 1.0.0 has been released! 🍕👹 Not many changes in this update, but this is quite a milestone 🥳 - the second stable package from @easystats4u, with more to come soon! #rstats easystats.github.io/effectsize/
More languages, more insights! A few interesting takeaways: * Java and Kotlin are quick! Possible explanation: Google is heavily invested in performance here. * Js is really fast as far as interpreted / jit languages go. * Python is quite slow without things like PyPy.
Are singles with the least lifetime involvement in romantic relationships "single at heart" and therefore with the best well-being outcomes? Our new paper in Psychological Science suggests, on average, no (N = 77,064, mainly ≥ 50 years, 27 countries). journals.sagepub.com/doi/10.1177/09…
This is still one of my favorite #dataviz of all time. It shows how sensitive results are in small samples. It provides raincloud plots with N=20 (on the left) & N=500 (right). There is no difference between the two conditions other than the N.
Very exciting news to share!! My new (and first!) book, Building Optimism, is out now! The book is an exploration of why our cities and towns look the way they do, and how to make them more beautiful, walkable, healthy, genial, affordable, dynamic and generally more desirable.
I can't figure out if vaccines work or not. Tough one. I can see why RFK Jr is so concerned. Need Sherlock Holmes on this one.
In a remarkable new study, Simine Vizier (@siminevazire), Sarah Schiavone (@SchiavoneSays), and Mijke Rhemtulla (@mijkenijk) surveyed 724 personality/social psychology researchers to investigate what they think of their own field. First, the good news: 🧵
We think that all memory is stored in the brain. But our study published today in @NatureComms shows that all cells—even kidney cells—can count, detect patterns, store memories, and do so similarly to brain cells. My first (co)corresponding author paper!🧵nature.com/articles/s4146…
Very neat idea for depicting change in ordinal data
25-30 is such a weird age group. You have to excel in your career, find a life partner, stay healthy and save money.
Researchers find nearly 30% of papers “that stated significances (or their absence) are based on the presence of a single influential data point.” biorxiv.org/content/10.110…
One thing I want to see change in the narrative is that this outcome is the fault of policy wonks & other "coastal elites." It's not. It's the outcome of the subversion of democratic processes that began with the Supreme Court's demolishing of campaign finance controls. (1/4)
The informal poll results are in, & as I feared, most people are running ANOVAs in #R with functions that can give highly misleading (or flat out wrong) results. Follow along to see why using anova() and aov() is usually inadvisable & why you should be using car::Anova() 🧵
I will die on this one: pay is the single largest gatekeeper we have in academia. This crap isn’t viable. It’s hurting people, and limiting the pool of talented folks that think it’s a good idea to do science or have the resources to do so.
We’re all thinking it