
Gabe Orlanski
@GOrlanski
PhD student @WisconsinCS, MS @nyuniversity, Former @replit, @magicailabs, @Google, @MerlinAero, @Theteamatx
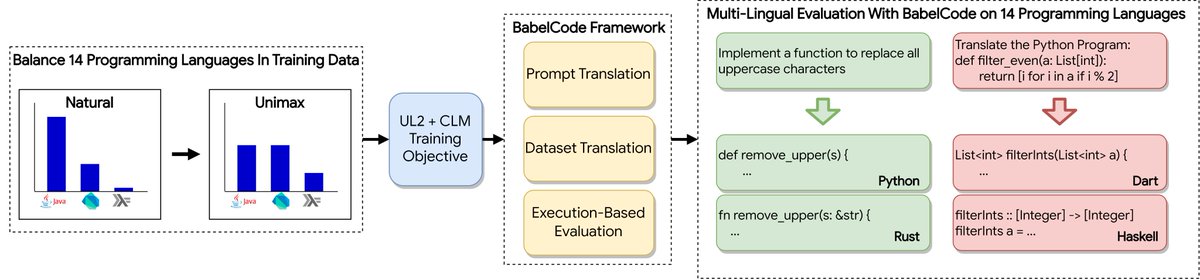
📢Measuring The Impact Of Programming Language Distribution We present the BabelCode framework for multi-lingual code evaluation and an investigation into the impact of PL distributions in training data. Paper: arxiv.org/abs/2302.01973 Code: github.com/google-researc… 🧵
come to our ai for math workshop tomorrow it'll be super fun!! 🎉🎉
Reinforcement learning has driven impressive gains in LLM reasoning—but what exactly does RL improve? SPARKLE answers this question with a fine-grained evaluation framework that dissects reasoning into plan-following, problem decomposition, and knowledge use. The results are…
🧠 New research reveals why Reinforcement Learning makes language models better at reasoning (spoiler: it's not what we thought!) 📝 Paper: arxiv.org/pdf/2506.04723 💻 Website: sparkle-reasoning.github.io We performed multi-stage curriculum-style RL training from base LLMs. Key…
Online data mixing reduces training costs for foundation models, but faces challenges: ⚠️ Human-defined domains miss semantic nuances ⚠️ Limited eval accessibility ⚠️ Poor scalability Introducing 🎵R&B: first regroup data, then dynamically reweight domains during training!
I will be talking about the Future of Multimodal AI applications at this @iclr_conf workshop on Monday 28th April at 2 pm local time #ICLR25 dl4c.github.io/schedule/
Today at #ICLR2025---come chat with @Changho_Shin_ about our work on what types of data drive weak-to-strong generalization!
📉📉NEW SCALING LAW PHENOMENON 📉📉 We find that knowledge and reasoning exhibit different scaling behaviors! Super excited to finally tell you all about our paper on the compute optimal scaling of skills: arxiv.org/pdf/2503.10061 [1/n]
Tired of evaluating frontier models on contrived math olympiad problems? We have a cure! Try your models on our new benchmark for theoretical physics TPBench.
Announcing Replit Agent v2, available in Early Access today! More highlights & how to get started in 🧵
Tons of model weights available, but what else can we do besides prediction? 🤔 📣 Introducing Grad-Mimic! A new data selection framework using well-trained model’s weights to find high-value samples for foundation models. Boost data curation & data efficiency!
If you are familiar with everything covered in this presentation, I got a job for you. Join me and the AI team at @Replit to build the most impactful project of your career — expect intensity, intellectual challenge and outsized glory once the mission is accomplished!
Curious about how Replit Agent works? At @Replit we hosted tech talks discussing agent's internals. Let's dive into what goes into an LLM that powers the agent - slides from my talk. 🧵