
Zichen Liu
@zzlccc
PhD student, RL believer @SeaAIL @NUSingapore | 💻 📄 🏸
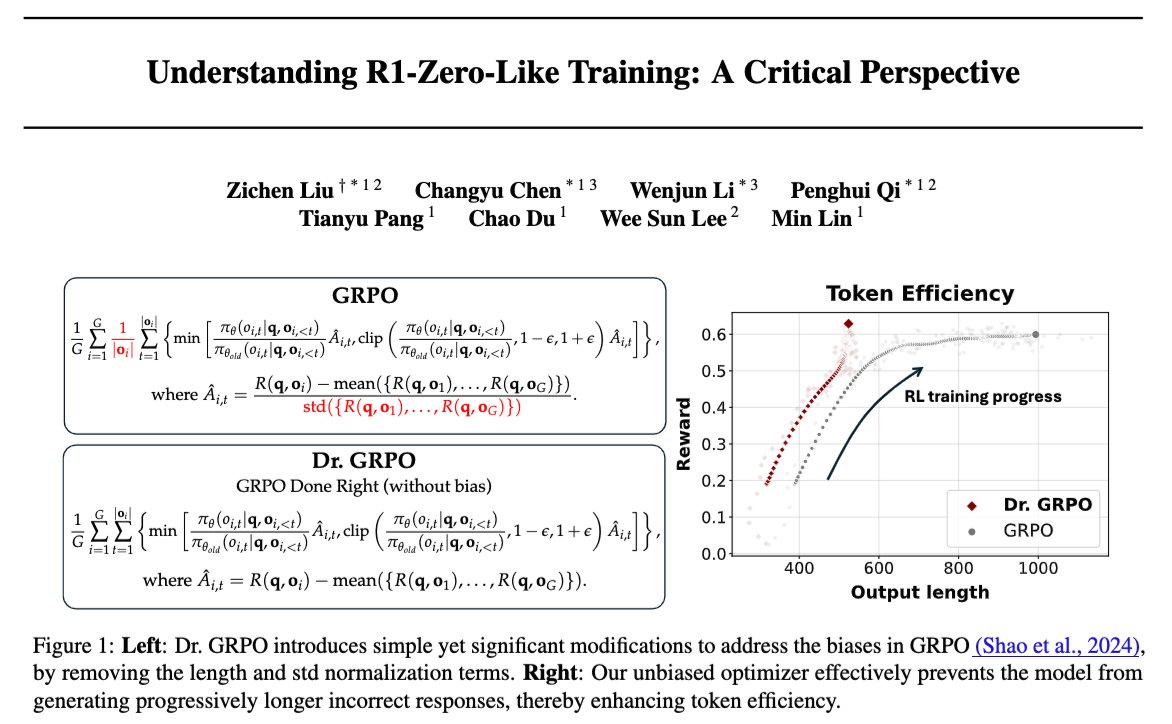
🪂Understanding R1-Zero-Like Training: A Critical Perspective * DeepSeek-V3-Base already exhibits "Aha moment" before RL-tuning?? * The ever-increasing output length in RL-tuning might be due to a BIAS in GRPO?? * Getting GRPO Done Right, we achieve a 7B AIME sota! 🧵 📜Full…

I would say it's not a bug but a technique by prior RL researchers... We can even treat the number of timesteps to be included for IS computation as a hyper-parameter, to get the best bias-variance tradeoff x.com/zzlccc/status/…
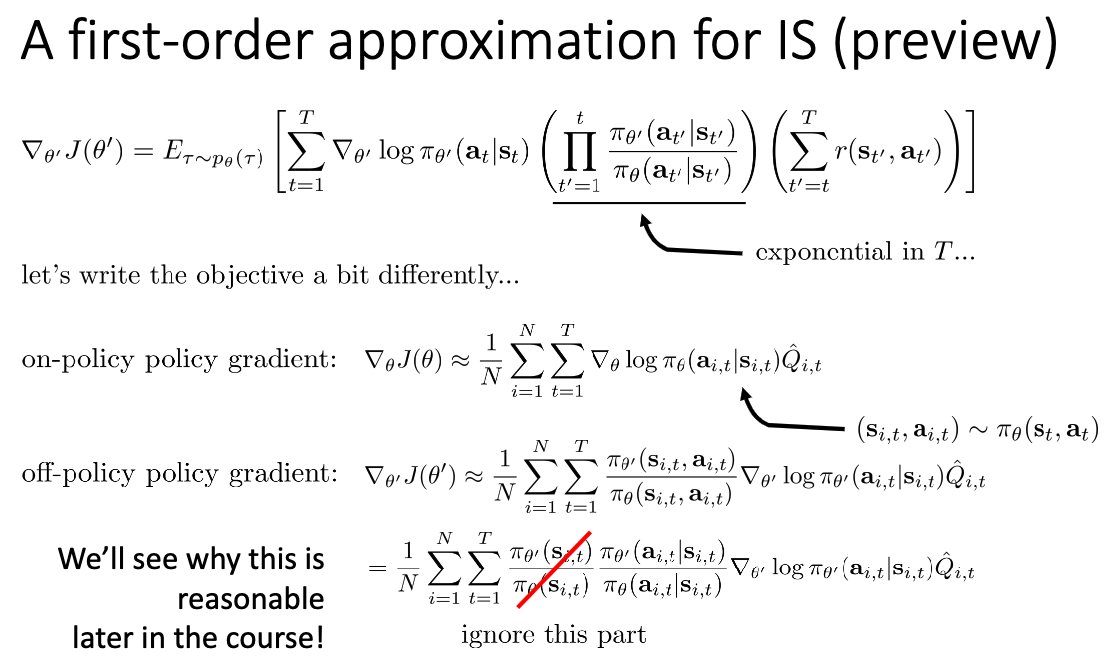
Learning GSPO proposed by Qwen team: fig 1. they propose to use sequence likelihood for importance sampling fig 2. but from the RL course by @svlevine, this is the original form of off-policy PG fig 3. per-token IS in (Dr) GRPO is an approximation of it Am I missing anything?
Learning GSPO proposed by Qwen team: fig 1. they propose to use sequence likelihood for importance sampling fig 2. but from the RL course by @svlevine, this is the original form of off-policy PG fig 3. per-token IS in (Dr) GRPO is an approximation of it Am I missing anything?


eat oat every morning; training with oat🌾the rest of the day: github.com/sail-sg/oat

no wonder Gemini used natural language-only solutions to achieve IMO gold

🚀🚀🚀 Ever wondered what it takes for robots to handle real-world household tasks? long-horizon execution, deformable object dexterity, and unseen object generalization — meet GR-3, ByteDance Seed’s new Vision-Language-Action (VLA) model! GR-3 is a generalizable…
🆕 Releasing our entire RL + Reasoning track! featuring: • @willccbb, Prime Intellect • @GregKamradt, Arc Prize • @natolambert, AI2/Interconnects • @corbtt, OpenPipe • @achowdhery, Reflection • @ryanmart3n, Bespoke • @ChrSzegedy, Morph with special 3 hour workshop from:…
100%, we should optimize for long-term returns instead of immediate reward, aka gamma > 0
Doing the right thing is important, even if you get penalized for it.
If life is a trajectory, and we are doing online continual RL, it seems that we are driven by many verifiable rewards 🤔
New blog post about asymmetry of verification and "verifier's law": jasonwei.net/blog/asymmetry… Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally. Great examples of…
Proud of my ml system colleagues who are doing amazing works with long-term vision
This is a part of our Zero Bubble Pipeline Parallelism series, pushing throughput🚀, memory💾 and scalability📈of LLM training to extreme! Project link: github.com/sail-sg/zero-b…
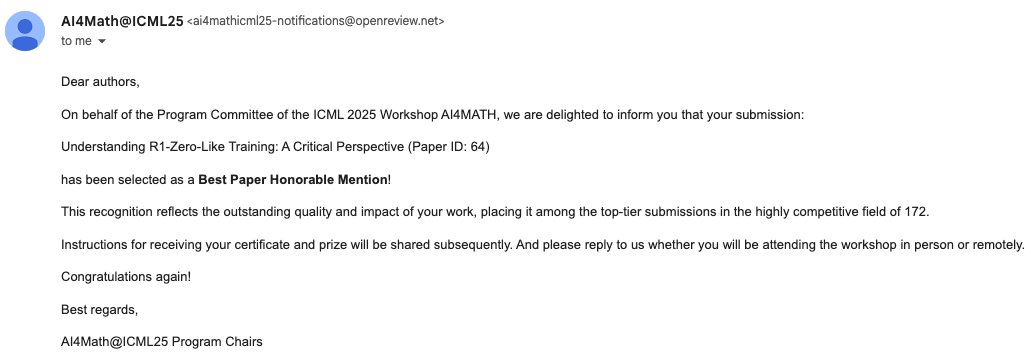
Honored our paper was selected as Best Paper Runner-Up at #ICML @ai4mathworkshop! Grateful to my incredible collaborators who will be presenting - wish I could join in person. Big thanks to the committee!
🪂Understanding R1-Zero-Like Training: A Critical Perspective * DeepSeek-V3-Base already exhibits "Aha moment" before RL-tuning?? * The ever-increasing output length in RL-tuning might be due to a BIAS in GRPO?? * Getting GRPO Done Right, we achieve a 7B AIME sota! 🧵 📜Full…
🚀 New at #ICML25: PipeOffload breaks the memory wall for LLM training with Pipeline Parallelism — linear activation memory scaling with zero performance loss. High memory usage is no longer a blocker. 👉 Follow our series of work pushing limits of PP!
Though not attending #ICML2025 in person, I'm super excited to share 3 accepted papers: 1.🎊Best Paper Honorable Mention @ AI4MATH workshop: Understanding R1-Zero-Like Training: A Critical Perspective (a.k.a Dr. GRPO but I think the paper is more than this loss fix) 2. Main…
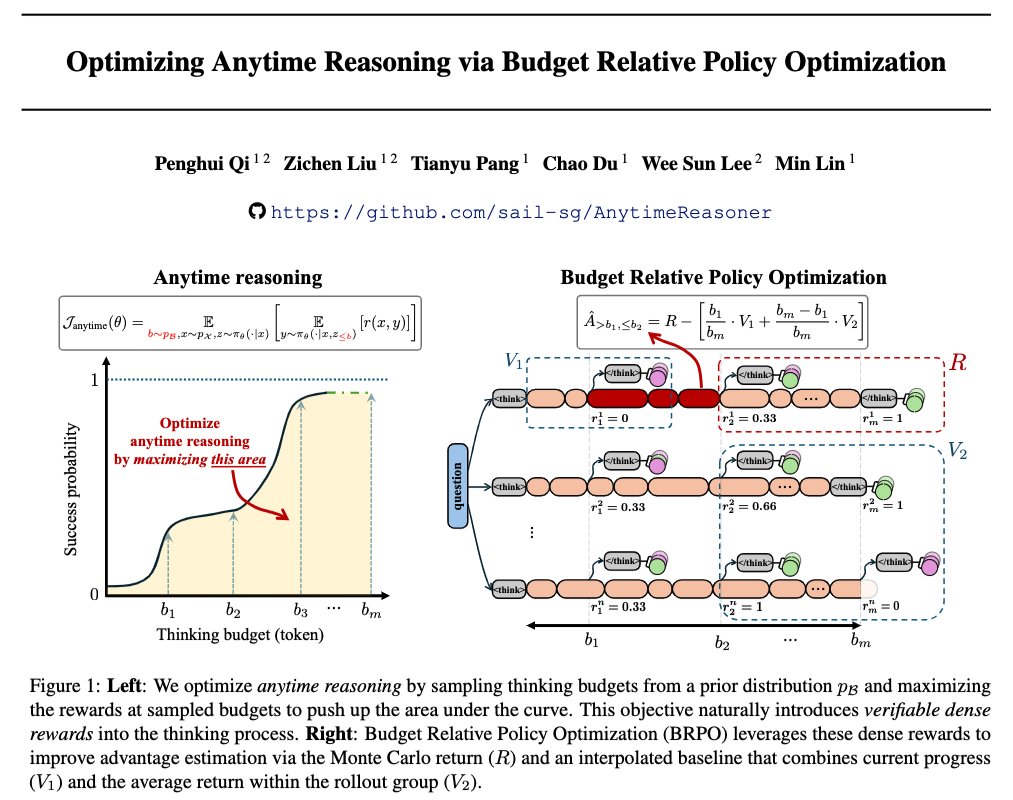
wow
This is the new kimi k2 instruct model running on claude-code - I had it make a 3D Snake game with a backend and a frontend -- it made this in about 2 hours of coding and headless testing -- cost about $1.5 of API usage - 3D snake game in threejs - Flask server, with a sqllite…
This work is accepted by @COLM_conf 2025 See you in Canada! 🍁
🪂Understanding R1-Zero-Like Training: A Critical Perspective * DeepSeek-V3-Base already exhibits "Aha moment" before RL-tuning?? * The ever-increasing output length in RL-tuning might be due to a BIAS in GRPO?? * Getting GRPO Done Right, we achieve a 7B AIME sota! 🧵 📜Full…
I can literally Ctrl+F those sentences but can't see them with my eyes. Sad for them.
"in 2025 we will have flying cars" 😂😂😂
LLM + RL + Self-Play + Game = ♾ Infinity Possibility ♾ 💥New Paper Alert💥 🔗Paper: huggingface.co/papers/2506.24… 🔗Code: github.com/spiral-rl/spir…
The future of RL+LLM? Self-play. Why? Competitive scenarios offer: ✅ Built-in verification ✅ Automated curriculum learning ✅ Infinite complexity scaling Games prove this works for multi-turn, multi-agent systems. But the real potential? Extending beyond games to real-world…
Self-play on zero-sum language games creates selection pressure for LLMs to develop transferrable reasoning patterns. Enjoyed building the multi-agent, multi-turn RL system and training agents that think strategically through self-play! Paper: huggingface.co/papers/2506.24… Code:…
We've always been excited about self-play unlocking continuously improving agents. Our insight: RL selects generalizable CoT patterns from pretrained LLMs. Games provide perfect testing grounds with cheap, verifiable rewards. Self-play automatically discovers and reinforces…
In our latest paper, we discovered a surprising result: training LLMs with self-play reinforcement learning on zero-sum games (like poker) significantly improves performance on math and reasoning benchmarks, zero-shot. Whaaat? How does this work? We analyze the results and find…
We've always been excited about self-play unlocking continuously improving agents. Our insight: RL selects generalizable CoT patterns from pretrained LLMs. Games provide perfect testing grounds with cheap, verifiable rewards. Self-play automatically discovers and reinforces…