
Zhengyang Tang
@zhengyang_42
PhD candidate @cuhksz, Intern @Alibaba_Qwen. Prev: @MSFTResearch, @TencentGlobal, @AlibabaGroup.
We’ve updated Qwen3 and made excellent progress. The non‑reasoning model now delivers significant improvements across a wide range of tasks and many of its capabilities already rival those of reasoning models. It’s truly remarkable, and we hope you enjoy it!
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507! After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing…
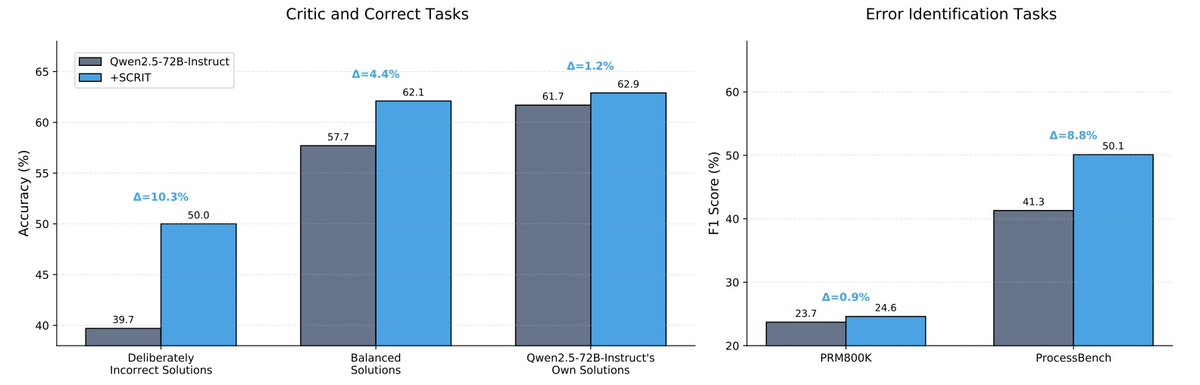
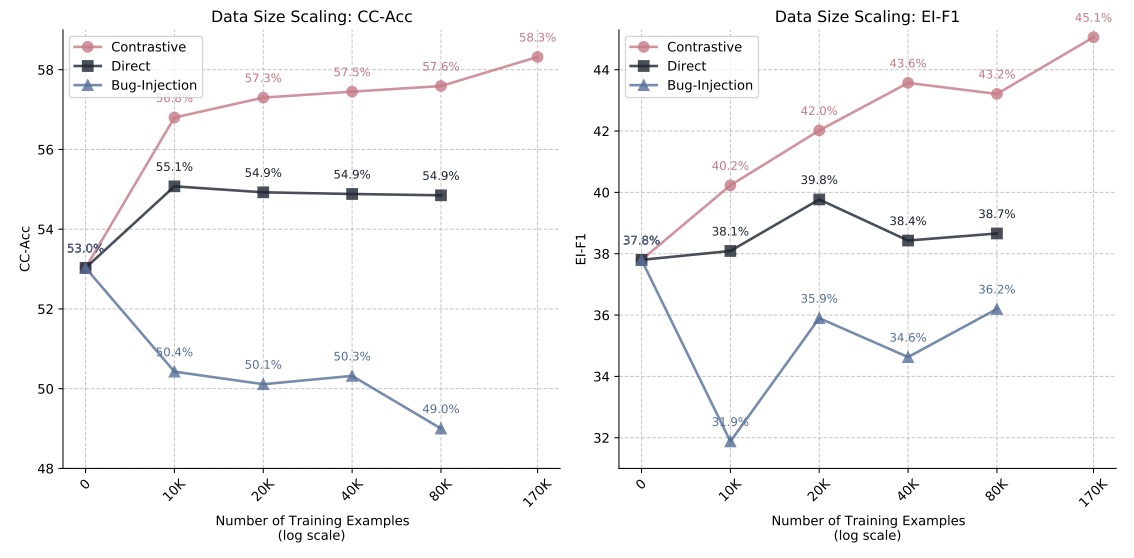
🚀 Thrilled to announce that our paper "SCRIT: Self-Evolving LLM Critique without Human or Stronger Models" was accepted to #COLM2025! We enable LLMs to self-improve critique abilities — zero human annotations, zero stronger models needed! 🔄✨ Looking forward to meeting…
🚀 Critique abilities are key for scaling LLMs, but current open-source models fall short. We introduce SCRIT: a framework with scalable oversight that enables LLMs to self-improve their critique skills✨ We’ve built a pipeline to generate high-quality synthetic critique data…
Happy to share that our paper "Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion" has been accepted to #ACL2025 as oral & panel presentation (25 out of 3000 accepted papers = top 0.8%)! 🎉 🚀 We introduce AceGPT with Progressive Vocabulary…
CoRT: Code-integrated Reasoning within Thinking "This paper introduces CoRT, a post-training framework for teaching LRMs to leverage Code Interpreter effectively and efficiently." "We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to…
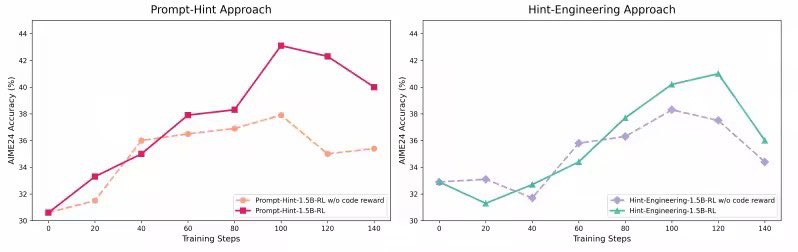
We’re excited to share our new paper “CoRT: Code-integrated Reasoning within Thinking”! 🤖 A post-training framework that teaches Large Reasoning Models (LRMs) to better leverage Code Interpreters for enhanced mathematical reasoning. 🔍 Key Highlights: Strategic hint…



Learning from Peers in Reasoning Models Large Reasoning Models often get stuck when they start reasoning incorrectly (the "Prefix Dominance Trap"). Propose LeaP (Learning from Peers), a method where parallel reasoning paths share intermediate summaries to learn from each other…
Super excited to have been part of the Qwen3 team! We just dropped our technical report - check it out if you're interested in what's under the hood. Hope it helps with your projects and research. Let us know what you think! #Qwen3 #AI
Please check out our Qwen3 Technical Report. 👇🏻 github.com/QwenLM/Qwen3/b…
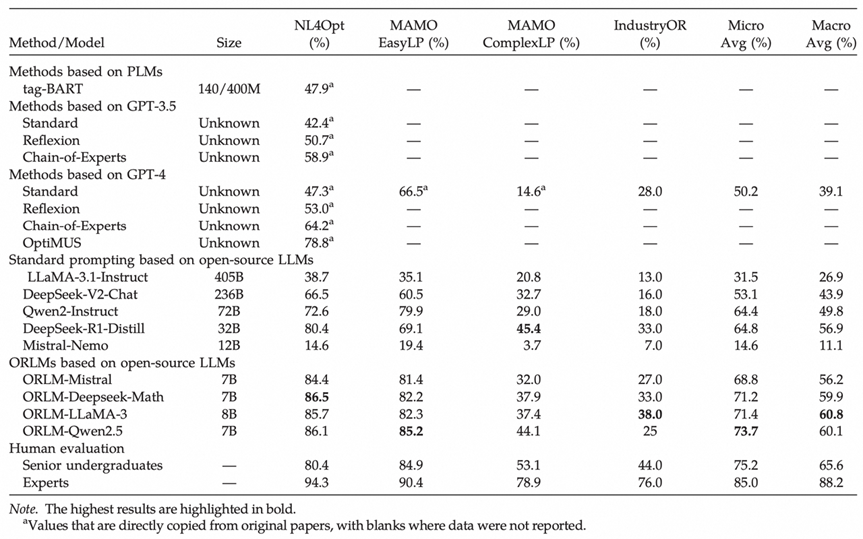
Thrilled to share our paper "ORLM: A Customizable Framework in Training Large Models for Automated Optimization Modeling" has been accepted by Operations Research! 🎉 This is the FIRST LLM paper in the 70+ year history of this prestigious journal. Our framework improves modeling…


🚀 Critique abilities are key for scaling LLMs, but current open-source models fall short. We introduce SCRIT: a framework with scalable oversight that enables LLMs to self-improve their critique skills✨ We’ve built a pipeline to generate high-quality synthetic critique data…
📢 Introducing SCRIT: A framework enabling LLMs to self-evolve their critique abilities without human annotations or stronger models. 💡 Key features: • Contrastive self-critic • Mathematical validity check • Zero external supervision 🔗 Paper: huggingface.co/papers/2501.05…


OpenAI o1 scores 94.8% on MATH dataset😲 Then...how should we proceed to track and evaluate the next-gen LLMs' math skills? 👉Omni-Math: a new, challenging benchmark with 4k competition-level problems, where OpenAI o1-mini only achieves 60.54 acc Paper: huggingface.co/papers/2410.07…
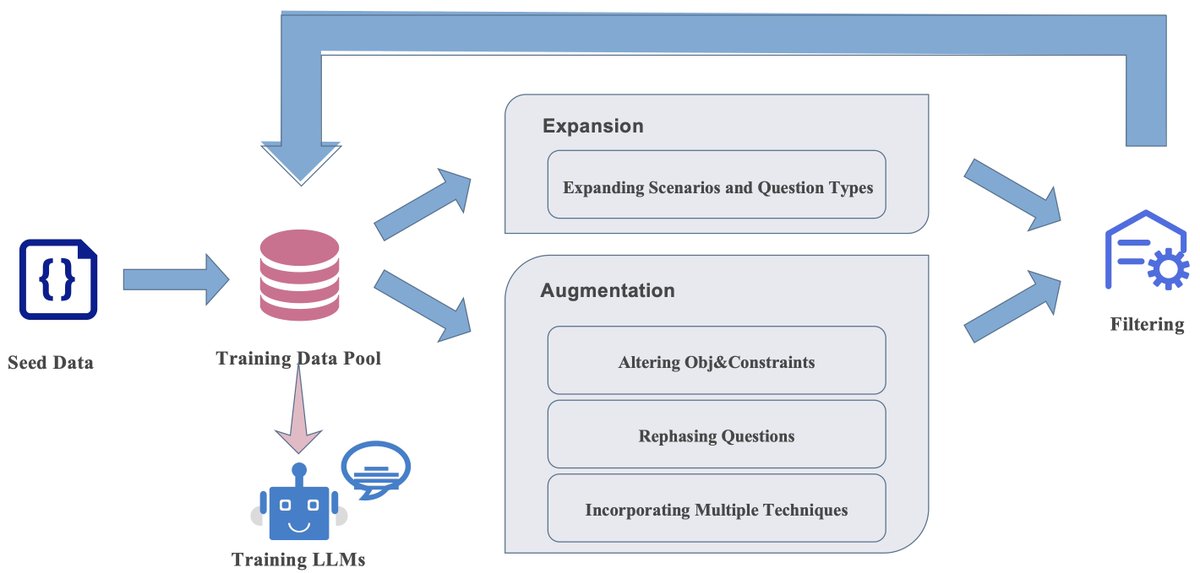
🚀 Launching ORLM: the first open-source Operations Research LLM, powered by our OR-Instruct process! 🛠️ 🏆 ORLMs achieves SOTA on NL4OPT, MAMO, & the new IndustryOR benchmarks based on different 7b backbones! 📄 Paper: arxiv.org/pdf/2405.17743 💻 Code: github.com/Cardinal-Opera…
MathScale Scaling Instruction Tuning for Mathematical Reasoning Large language models (LLMs) have demonstrated remarkable capabilities in problem-solving. However, their proficiency in solving mathematical problems remains inadequate.
Microsoft presents GLAN (Generalized Instruction Tuning) Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models GLAN excels without using task-specific training data arxiv.org/abs/2402.13064
DPTDR: Deep Prompt Tuning for Dense Passage Retrieval deepai.org/publication/dp… by @zhengyang_42 et al. including @wabyking #NaturalLanguageProcessing #Computation