
Yukang Cao
@yukangcao
3D Computer Vision || Postdoc @NTUsg | Ex-{Ph.D @HKUniversity, B.Eng @ZJU_China} (To learn, to fail; To learn more, to fail more)
Morph4Data has also been released now! It provides image pairs with diverse semantics and layouts, valuable for evaluating image morphing techniques.
🔥Tuning-free 2D image morphing🔥 Tired of complex training and strict semantic/layout demands? Meet #FreeMorph #ICCV2025: tuning-free image morphing across diverse situations -Project: yukangcao.github.io/FreeMorph -Paper: arxiv.org/abs/2507.01953 -Code: github.com/yukangcao/Free…
🤩Tuning-Free Image Morphing🤩 #FreeMorph enables tuning-free generalized image morphing that accommodates inputs with different semantics or layouts @ICCVConference - Paper @huggingface: huggingface.co/papers/2507.01… - Project: yukangcao.github.io/FreeMorph/ - Code: github.com/yukangcao/Free…
FreeMorph Tuning-Free Generalized Image Morphing with Diffusion Model
🔥Tuning-free 2D image morphing🔥 Tired of complex training and strict semantic/layout demands? Meet #FreeMorph #ICCV2025: tuning-free image morphing across diverse situations -Project: yukangcao.github.io/FreeMorph -Paper: arxiv.org/abs/2507.01953 -Code: github.com/yukangcao/Free…
FreeMorph Tuning-Free Generalized Image Morphing with Diffusion Model
📢 Welcome to check our GenAI work @iclr_conf 🇸🇬 * Video Gen - FasterCache: vchitect.github.io/FasterCache/ * 3D Gen - Phidias: rag-3d.github.io * 4D Gen - DynamicCity: dynamic-city.github.io - AvatarGO: yukangcao.github.io/AvatarGO/ * Multimodal LLM - Oryx: oryx-mllm.github.io
🥨Code has been released at github.com/yukangcao/Avat…
🧙♂️Equip your 4D human generation with object interactions We introduce #AvatarGO for zero-shot 4D Human-Object Interaction Generation and Animation. Project: yukangcao.github.io/AvatarGO/ Paper: arxiv.org/abs/2410.07164 Code: github.com/yukangcao/Avat…
🛠️Code for GS-VTON has been released at github.com/yukangcao/GS-V…
🔥Curious about how you'd look in different outfits? We present GS-VTON, a versatile pipeline that allows for editing the clothing of 3D human subjects with image prompts. - Project: yukangcao.github.io/GS-VTON - Paper: arxiv.org/abs/2410.05259 - Code: github.com/yukangcao/GS-V…
🔥4D Human-Object Interaction Generation🔥 * Wanna see "Iron Man lifting an axe of Thor"? * #AvatarGO is a zero-shot framework to generate 4D human-object interaction from texts - Project: yukangcao.github.io/AvatarGO/ - Paper: arxiv.org/pdf/2410.07164 - Code: github.com/yukangcao/Avat…
🧙♂️Equip your 4D human generation with object interactions We introduce #AvatarGO for zero-shot 4D Human-Object Interaction Generation and Animation. Project: yukangcao.github.io/AvatarGO/ Paper: arxiv.org/abs/2410.07164 Code: github.com/yukangcao/Avat…
🧙♂️Equip your 4D human generation with object interactions We introduce #AvatarGO for zero-shot 4D Human-Object Interaction Generation and Animation. Project: yukangcao.github.io/AvatarGO/ Paper: arxiv.org/abs/2410.07164 Code: github.com/yukangcao/Avat…
🤩Try On Any Outfit from Any Angle🤩 We introduce 🧥GS-VTON👠 to enable **free-view 3D virtual try-on** (VTON) by transferring the pre-trained knowledge from 2D VTON models to 3D - Project: yukangcao.github.io/GS-VTON/ - Paper: arxiv.org/pdf/2410.05259 - Code: github.com/yukangcao/GS-V…
🔥Curious about how you'd look in different outfits? We present GS-VTON, a versatile pipeline that allows for editing the clothing of 3D human subjects with image prompts. - Project: yukangcao.github.io/GS-VTON - Paper: arxiv.org/abs/2410.05259 - Code: github.com/yukangcao/GS-V…
🔥Curious about how you'd look in different outfits? We present GS-VTON, a versatile pipeline that allows for editing the clothing of 3D human subjects with image prompts. - Project: yukangcao.github.io/GS-VTON - Paper: arxiv.org/abs/2410.05259 - Code: github.com/yukangcao/GS-V…
🔥Experiencing issues with image generation due to visible artifacts like watermarks or invisible artifacts (e.g., adversarial noise) in the training images? 📢Check ArtiFade for generating high-quality subject from blemished images. 📖arxiv.org/abs/2409.03745 @haoshaozhe

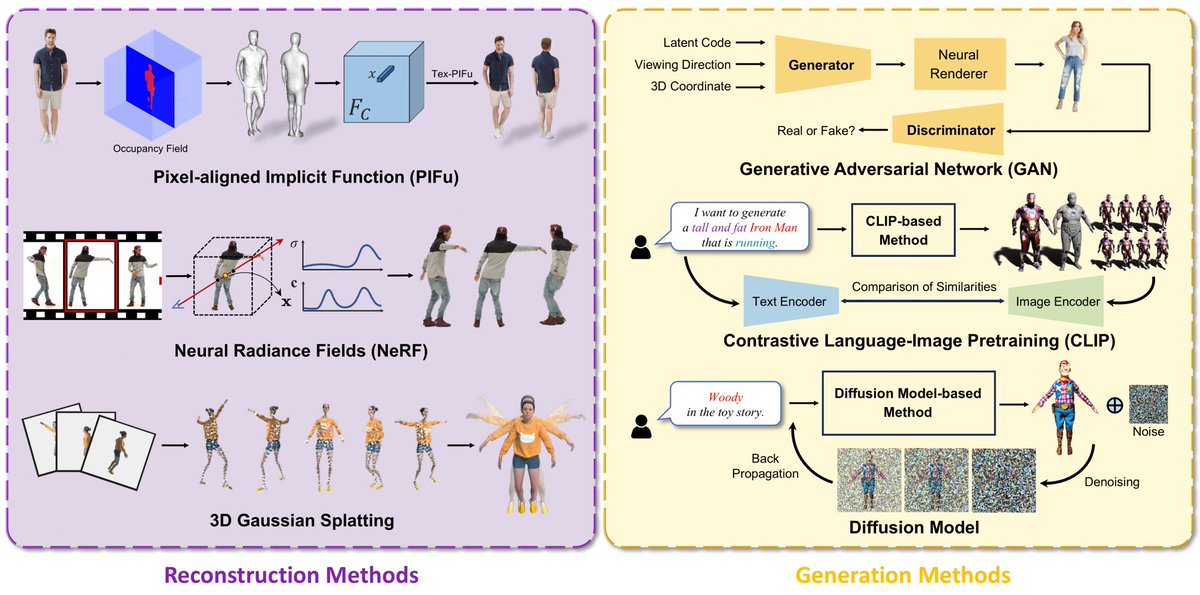
A Survey on 3D Human Avatar Modeling -- From Reconstruction to Generation arxiv.org/abs/2406.04253
Wants to learn more about the past, present, and future of 3D human modeling? Check our recent work: A Survey on 3D Human Avatar Modeling - From Reconstruction to Generation. Hope you will get some valuable insights from it! arxiv: arxiv.org/abs/2406.04253

🔥Interactive Text-to-Texture Synthesis🔥 We present #InTeX, an interactive framework for 3D text-to-texture synthesis, with *region repainting* and *real-time editing on laptop* - Project: me.kiui.moe/intex/ - Paper: arxiv.org/abs/2403.11878 - Code: github.com/ashawkey/InTeX
👏🏻 👏🏻We now have several major updates for OpenLRM: (1) We release the full model trained on both objaverse and MVImgNet. (2) We release the full training code, which can help reproduce image-to-3d models. Code: github.com/3DTopia/OpenLRM HF demo: huggingface.co/spaces/zxhezex…
🌟We release OpenLRM (github.com/3DTopia/OpenLRM), which is an open source codebase for large reconstruction models. OpenLRM achieves fast and high-quality image-to-3D generation (reconstruction). We hope this open source project can advance the field of 3D Gen. @he_zexin @liuziwei7
📢Text-to-3D Foundation Model📢 Our #3DTopia has major updates, with 1) newly released technical report, and 2) our own *refined captions* for the Objaverse quality set - Code: github.com/3DTopia/3DTopia - Paper: arxiv.org/pdf/2403.02234… - Refined Objaverse: github.com/3DTopia/3DTopi…
3DTopia demo is out on Hugging Face demo: huggingface.co/spaces/hongfz1… text-to-3D foundation model, which produces high-quality 3D assets within 5 minutes
DreamAvatar has been accepted to #CVPR2024. Congrats to the collaborators. See you in Seattle✈️!
💃Glad to re-introduce DreamAvatar!💃 DreamAvatar was the first to generate controllable 3D avatars via diffusion models. We are now happy to bring it to a higher level! - Project: yukangcao.github.io/DreamAvatar/ - Code: github.com/yukangcao/Drea… - arXiv: arxiv.org/abs/2304.00916
🔥Large Multi-View Gaussian Model (LGM)🔥 We introduce #LGM, a feed-forward foundation model for text-to-3D and image-to-3D, which generates high-res 3D content in 5s - Project: me.kiui.moe/lgm/ - Code: github.com/3DTopia/LGM - Demo @huggingface: huggingface.co/spaces/ashawke…
LGM Large Multi-View Gaussian Model for High-Resolution 3D Content Creation paper page: huggingface.co/papers/2402.05… 3D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds,…
#URHand is the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. 🫰With only a mobile phone, you can have YOUR (personalized 3D relightable) HAND🫰 - Project: frozenburning.github.io/projects/urhan… - Paper: arxiv.org/abs/2401.05334
Meta announces URHand Universal Relightable Hands paper page: huggingface.co/papers/2401.05… model is a high-fidelity Universal prior for Relightable Hands built upon light-stage data. It generalizes to novel viewpoints, poses, identities, and illuminations, which enables quick…