
Yiying Zhang
@yiying__zhang
Founder and CEO of GenseeAI, Associate Professor of Computer Science at UCSD. LLM serving, AI Workflows, Agents
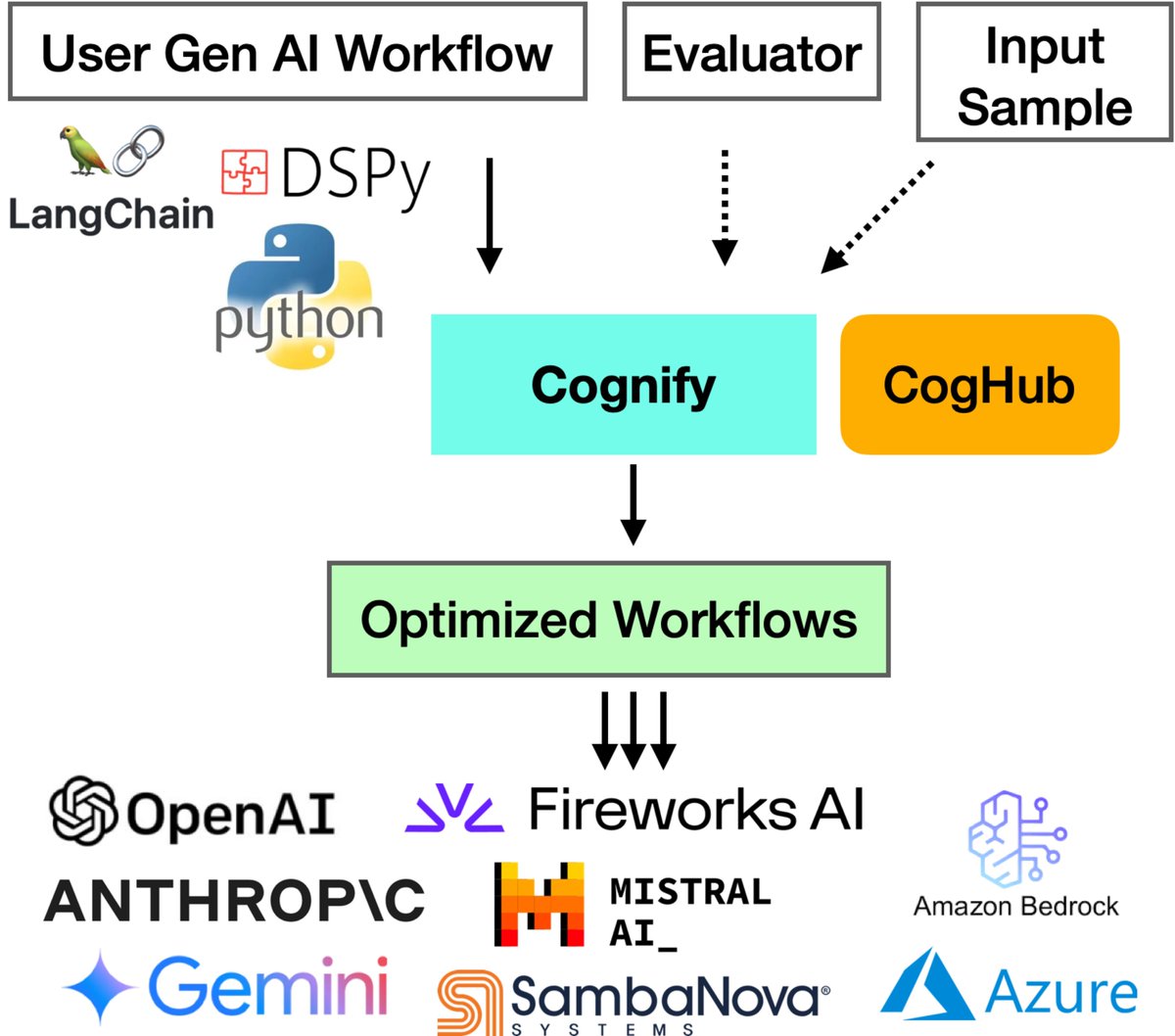
Struggling with developing high-quality gen-AI apps? Meet Cognify: an open-source tool for automatically optimizing gen-AI workflows. 48% higher generation quality, 9x lower cost, fully compatible with LangChain, DSPy, Python. Read & try Cognify: tinyurl.com/a8b9cdnj #GenseeAI
Announcing Gensee Beta! Start FREE: gensee.ai Take your AI agent/workflow from prototype to a deployed, high-quality product in minutes. ✅ One-Click Deployment ✅ 500 Free Credits/Month ✅ Auto-Optimize for Cost, Speed & Quality ✅ Advanced Testing & Custom…
Computer-use AI agents (CUAs) are powerful, but way too slow. A 2-minute human task can take a CUA over 20 minutes! At Wuklab, we're building faster CUAs. Recently, we created OSWorld-Human, a new benchmark to close the speed gap between humans and machines. Read our full blog…
We are excited to launch the free beta of our AI agent/workflow serving platform, designed for intelligent execution optimization; tester.gensee.ai. Send me a direct message for an invitation code if you want to try it out. #AI #AIAgent #GenseeAI #LLMs #Infrastructure
We're collecting insights on the current & potential use of AI agents to help build better future infrastructure. Please take our quick 1-2 minute survey: lnkd.in/gcWU9mmQ. Your responses are valuable for our R&D (anonymous option available), and you will receive a $25-$50…
My team and I will be at Nvidia GTC in person next week. Happy to chat about GenseeAI and more! 🤝 #NVIDIA #GTC #GenAI

Check how Cognify uses only $5 and 24 minutes to cover a search space of $168K and weeks when autotuning gen-AI workflows in the pt.2 of our tech blog: tinyurl.com/yutx334k. Code tinyurl.com/2tp9bndr. Paper tinyurl.com/3kx2xjn9

Boost your gen-AI workflow's quality by 2.8x with just $5 in 24 minutes! Check how Cognify autotunes gen-AI workflow’s quality and execution efficiency with a tiny budget in our latest blog post tinyurl.com/4tyvvdks. Paper tinyurl.com/3kx2xjn9. Code tinyurl.com/2tp9bndr.

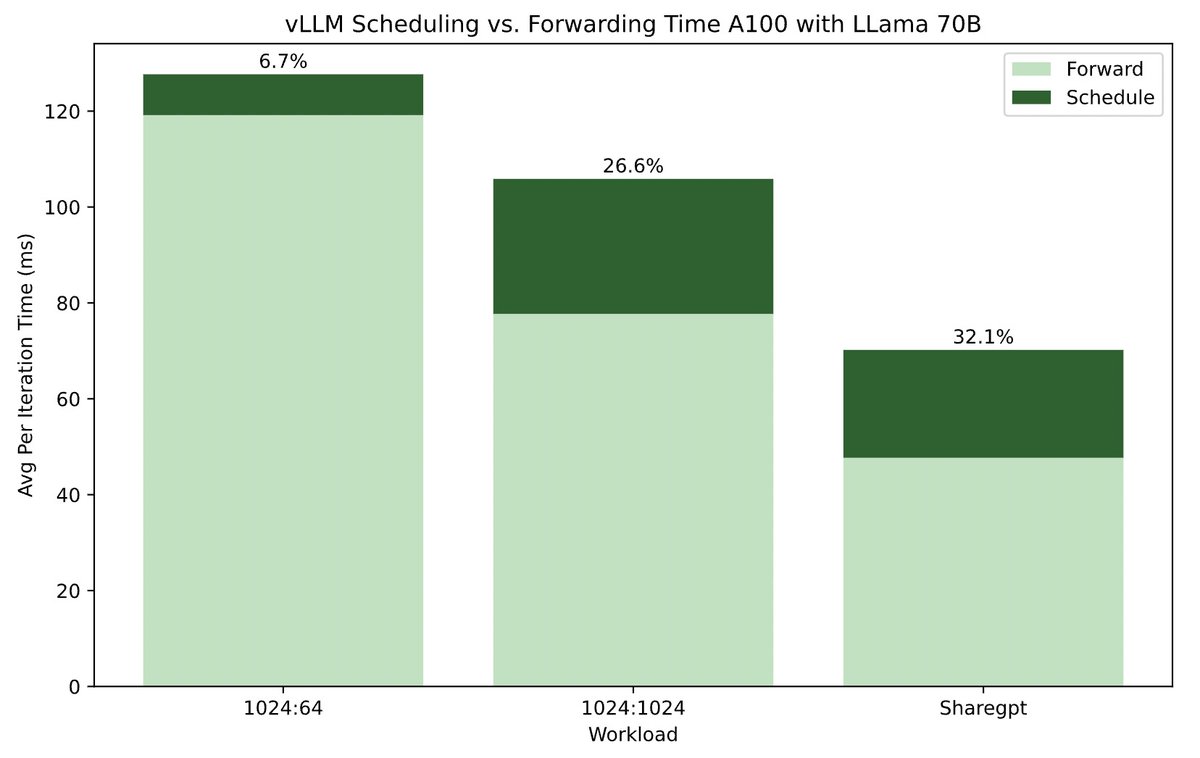
WukLab's new study reveals CPU scheduling overhead can dominate LLM inference time—up to 50% in systems like vLLM! Scheduling overhead can no longer be ignored as model forwarding speeds increase and more scheduling tasks get added.#LLM #vLLM #SGLang Read tinyurl.com/yk4jeaz8


Join us at ICML in Vienna next Thursday 11:30-1pm local time (poster session 5) for our poster on InfeCept (Augmented, or compound, AI serving system) at Hall C 4-9 #709 Know more about InferCept with our newly posted video: youtube.com/watch?v=iOs1b0…
LLM prompts are getting longer and increasingly shared with agents, tools, documents, etc. We introduce Preble, the first distributed LLM serving system targeting long and shared prompts. Preble reduces latency by 1.5-14.5x over SOTA serving systems. #LLM mlsys.wuklab.io/posts/preble/