
Yifu Qiu@ACL2025 🇦🇹
@yifuqiu98
@ELLISforEurope PhD Student in NLP @EdinburghUni /@Cambridge_Uni | Intern @Meta FAIR | formerly @Apple AIML @Baidu_inc NLP | 2023 Apple AI/ML Scholar
🔁 What if you could bootstrap a world model (state1 × action → state2) using a much easier-to-train dynamics model (state1 × state2 → action) in a generalist VLM? 💡 We show how a dynamics model can generate synthetic trajectories & serve for inference-time verification 🧵👇
Most importantly, I will be in job market for 2026. If you have any research positions about language grounding (world model), hallucinations, safety for foundation models. Let’s discuss about it!
Heading to ACL @aclmeeting. I will, 1. Present my paper done with @Apple, “Eliciting In-context Retrieval and Reasoning for Long-Context Language Models” at 18:00 - 19:30, Monday, 27th July, Hall 4/5 2. Be in @AIatMeta booth at 1-2PM, Tuesday, 28th July. Chat if you’re around.
Heading to ACL @aclmeeting. I will, 1. Present my paper done with @Apple, “Eliciting In-context Retrieval and Reasoning for Long-Context Language Models” at 18:00 - 19:30, Monday, 27th July, Hall 4/5 2. Be in @AIatMeta booth at 1-2PM, Tuesday, 28th July. Chat if you’re around.
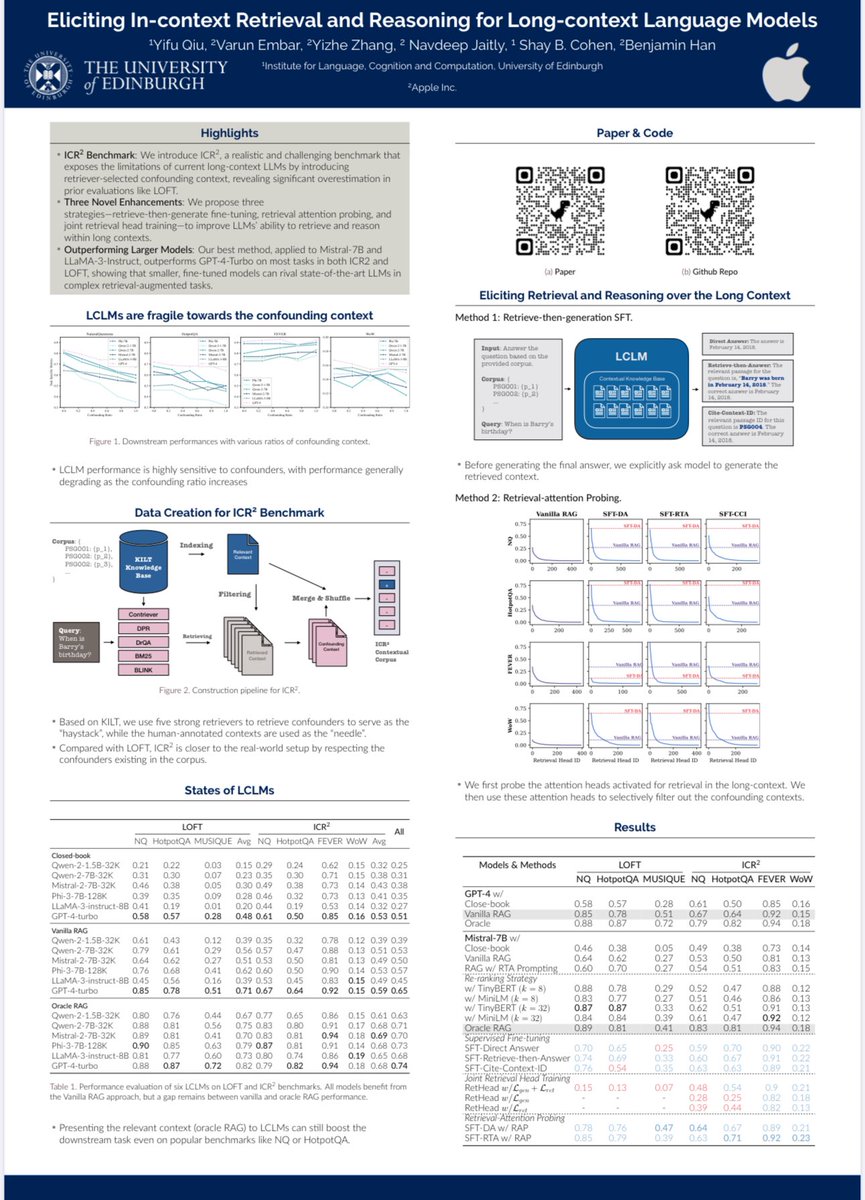
🚀 Check out our paper done jointly with Apple. Eliciting In-context Retrieval and Reasoning for Long-Context Language Models 18:00 - 19:30, Monday, July 28. - In-Person 1, Hall 4/5. 🇦🇹
The amazing folks at @EdinburghNLP will be presenting a few papers at ACL 2025 (@aclmeeting); if you're in Vienna, touch base with them! Here are the papers in the main track 🧵
Why do AI assistants feel so generic? Our new #ACL2025 paper, PersonaLens🔎, tackles this head-on. We built a new benchmark to test personalization in ways that matter. I'll be presenting our work at the poster session in Vienna next week! 🧵[1/4]
🚀 Introducing Prefix-RFT to blend SFT and RFT! SFT can learn more complex problems by mimicking, but can have poor generalization. RFT has better overall performance but is limited by the initial policy. Our method, Prefix-RFT, makes the best of both worlds!
🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget. This unlocks *inference-time hyper-scaling* For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
Only in China you can write up your ACL camera-ready version on a high-speed train in the area crossing lots of tunnels and mountains. Though passing few relatively under-developed provinces in the southwest China, my networks only stuck for 10 seconds. Amazing.

Happy to share that our work, ICR^2, is accepted by ACL, let’s meet in Vienna 🇦🇹 this summer!
🚀Happy to share my last-year Apple's internship work! A promising use case of long-context LLMs is enabling the entire knowledge base to fit in the prompt as contextual knowledge for tasks like QA, rather than RAG pipeline. But are they up to this? If not, how to improve?
Check out if you are interested in multimodal summarization for scientific publications👇 Amazing work, well done!@dongqi_me
🚨 Long Paper Accepted at @aclmeeting 2025 main conference! 🚨 🎥 Our work "What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations" introduces VISTA, a large-scale benchmark for scientific video summarization. #ACL2025 #NLProc #LLMs 🧵(1/3)
Main takeaway: Optimal scaling is not just about increasing model size but also attention sparsity.
Sparse attention is one of the most promising strategies to unlock long-context processing and long generation reasoning in LLMs. We performed the most comprehensive study on training-free sparse attention to date. Here is what we found:
Can multimodal LLMs truly understand research poster images?📊 🚀 We introduce PosterSum—a new multimodal benchmark for scientific poster summarization! 🪧 📂 Dataset: huggingface.co/datasets/rohit… 📜 Paper: arxiv.org/abs/2502.17540