
Tiago Pimentel
@tpimentelms
Postdoc at @ETH_en. Formerly, PhD student at @Cambridge_Uni.
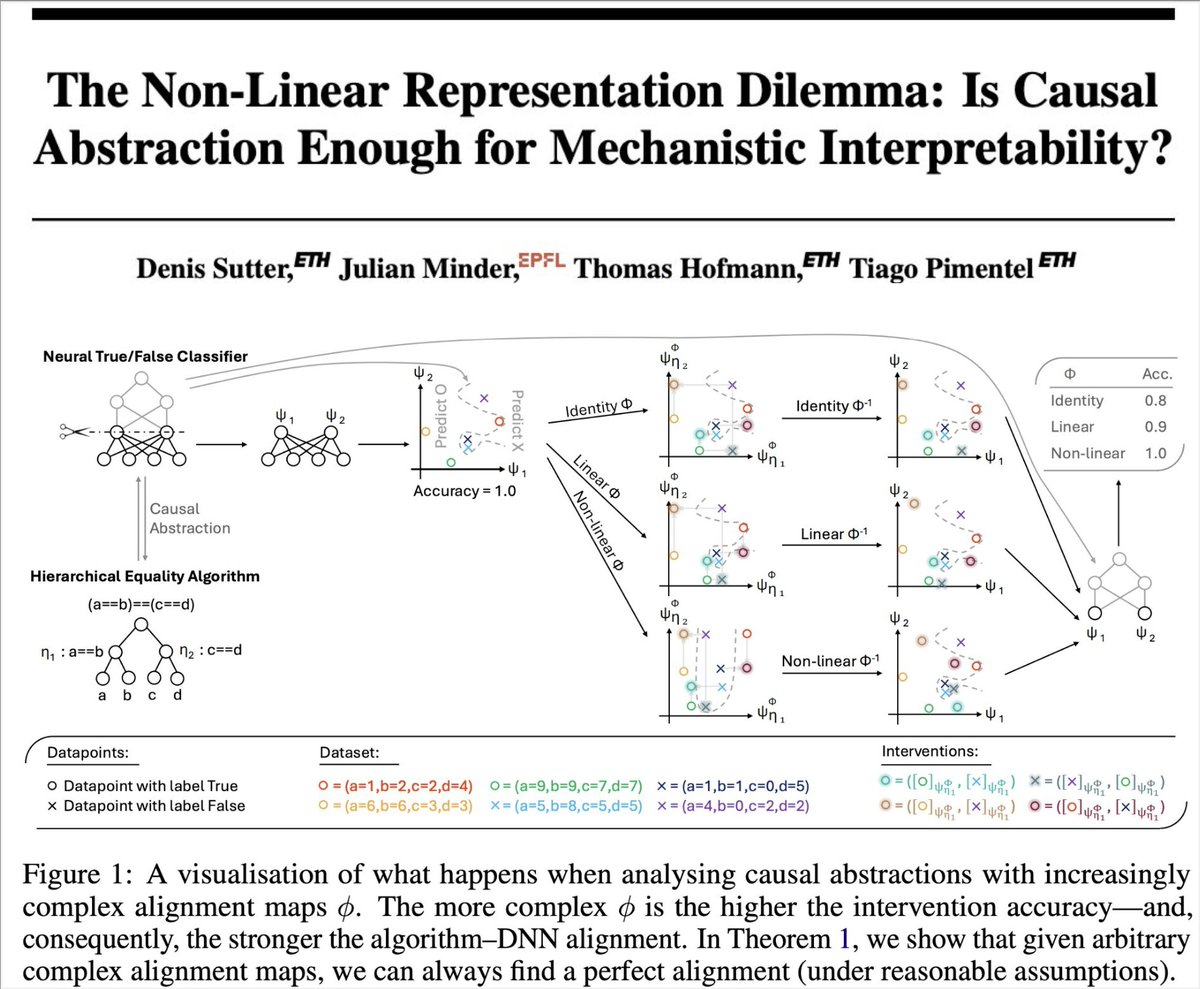
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵
🎤 Meet our expert panelists! Join Albert Gu, Alisa Liu, Kris Cao, Sander Land, and Yuval Pinter as they discuss the Future of Tokenization on July 18 at 3:30 PM at TokShop at #ICML2025.
Life update: I’m excited to share that I’ll be starting as faculty at the Max Planck Institute for Software Systems(@mpi_sws_) this Fall!🎉 I’ll be recruiting PhD students in the upcoming cycle, as well as research interns throughout the year: lasharavichander.github.io/contact.html
I'm in Vancouver for TokShop @tokshop2025 at ICML @icmlconf to present joint work with my labmates, @tweetByZeb, @pietro_lesci and @julius_gulius, and Paula Buttery. Our work, ByteSpan, is an information-driven subword tokenisation method inspired by human word segmentation.
I will also be sharing more Tokenisation work from @cambridgenlp at TokShop– this time on Tokenisation Bias by @pietro_lesci and @vlachos_nlp, @clara__meister, Thomas Hofmann and @tpimentelms.
Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @DenisSutte9310, T. Hofmann, @tpimentelms) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.
Our team is hiring a postdoc in (mech) interpretability! The ideal candidate will have research experience in interpretability for text and/or image generation models and be excited about open science! Please consider applying or sharing with colleagues: metacareers.com/jobs/222395396…
🎓For today's lab seminar, we had the pleasure to host @MiriamSchirmer with her presentation on Measuring and Reducing the Psychological Impact of Online Harm and @tpimentelms with How Much Does Tokenisation Impact Language Models? #NLProc #onlineharms #tokenisation
Some personal news ✨ In September, I’m joining @ucl as Associate Professor of Computational Linguistics. I’ll be building a lab, directing the MSc programme, and continuing research at the intersection of language, cognition, and AI. 🧵
Is equivariance necessary for a good 3D molecule generative model? Check out our #icml2025 paper, which closes the performance gap between non-equivariant and equivariant diffusion models via rotational alignment, while also being more efficient (1/7): arxiv.org/abs/2506.10186
Check out log-linear attention—our latest approach to overcoming the fundamental limitation of RNNs’ constant state size, while preserving subquadratic time and space complexity
We know Attention and its linear-time variants, such as linear attention and State Space Models. But what lies in between? Introducing Log-Linear Attention with: - Log-linear time training - Log-time inference (in both time and memory) - Hardware-efficient Triton kernels
Longer 🧵 about tokenisation bias! The effects we measured are quite strong: models have up to a 17x difference in outputs due only to tokenisation 😱 If your model uses tokens, maybe you should read this! :)
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias. Let’s talk about it and why it matters👇 @aclmeeting #ACL2025 #NLProc