
dag
@theDrewDag
Not a data scientist, but it's the closest title to what I am. I like data, machine learning and the brain. http://skillsherpa.ai http://diariodiunanalista.it
ChatGPT really can't work with Juypter Notebooks. It just won't understand shit of the notebook's content.
The aspect of LLMs that genuinely excites me is the offline scenario + small, portable models to enrich your code with code gen, testing and labeling. Having huge, paid LLMs whose providers steal your data is not something I want to see more in the future.
Graphical representation of how binary search works. In data science, binary search can be used as a building block for more complex algorithms used in machine learning, such as algorithms for training neural networks or for finding the optimal hyperparameters for a model.
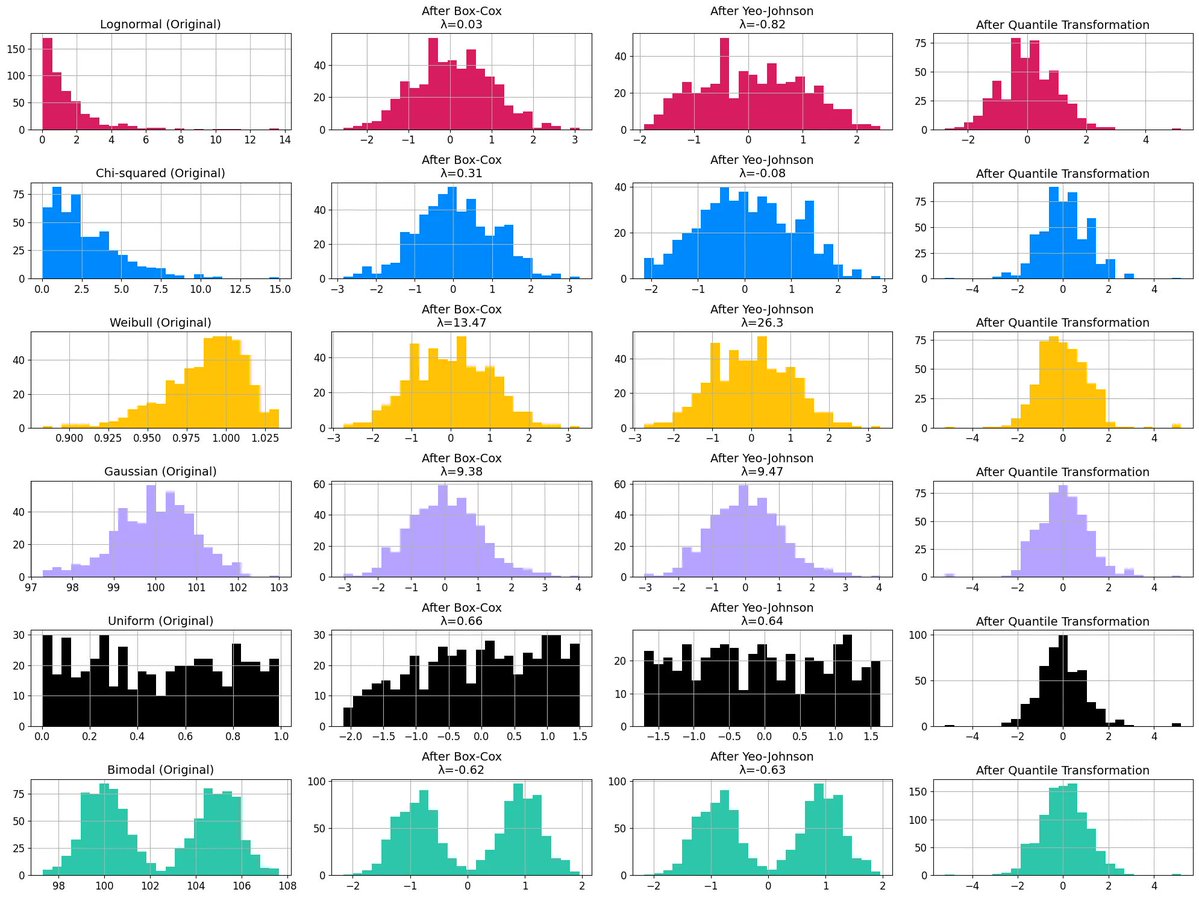
Examples of transformations: from specific distributions to normal. Below is a graphical visualization that compares different non-normal distributions and their relative transformation using known functions from the field. This image highlights the limitations of some…
Missed @theDrewDag's insights? He's back! His latest article unpacks POSETs – a powerful approach to represent complex data by preserving original information and recognizing incomparability. Inspired to share your own expertise? We're always looking for new contributors to our…
There is joy in solving data problems with traditional statistical methods. Not relying on LLMs saves time and money and fosters pride.
Profound thinking for long periods of times on a specific topic is the key to expertise.
I am back posting on @TDataScience. In this post I cover POSET representations for business analytics. POSET (partially ordered sets) representation is a strategy for comparing multidimensional data while respecting their intrinsic "incomparability" relationships. This is often…

Creating datasets for training and fine-tuning is a key skill for data scientists. The ecosystem of model-building tools (Hugging Face, Sentence Transformers, etc.) streamlines training and fine-tuning. Model and architecture knowledge matters, but is secondary to well-designed…
Hugging Face is magnitudes more impactful than OpenAI in creating value for the technological future of humanity.
Tired of arbitrary weights in your aggregate scores? 📊 @theDrewDag's article introduces POSETs (Partially Ordered Sets), a powerful mathematical framework that transforms how we represent multi-dimensional data. towardsdatascience.com/poset-represen…
Delegating auth to an external service is something I advise against, especially in cases where LLM-based services are behind login. Should these services go down, your system either crashes or it defaults to (possibly) unknown behaviors. In a production setting this is a big…
Tired of forcing your data into linear rankings? Explore @theDrewDag's latest article on POSET indicators and learn how they preserve your data's multi-dimensional semantic structure by explicitly revealing incomparability. towardsdatascience.com/poset-represen…
I am moving my first steps with neovim. Can't believe I've been missing out so much. Lot's of fun writing Lua to get my wanted config going.
Signal detection, network science and graph ML and genetic / evolutionary algorithms are the interesting, exciting frontiers of data. Too much hype in the LLM area to be genuinely excited about stuff there.
Little trick to recognize Big O complexity: Look at the number of cycles. Each cycle denotes processing on one input unit. The more cycles an algorithm has, the higher its Big O complexity.
Regardless of your lifestyle and work routine, normalize stretching for 30 mins before going to bed. It will help you release all of that built up tension during the day and sleep better.