Tarik Hammadou
@thammadou
2 x startup founder, started career @Motorola Labs. Today, Director Developer’ Relations @Nvidia. Driven by passion & guided by experience. Opinions my own.
Struggling with slow pandas workflows on large datasets? We turned on GPUs—and everything changed: 1. Time-series stock analysis – Rolling-window ops (e.g., 50‑ and 200‑day moving averages) on 18 M rows took minutes on CPU, but seconds with GPU—up to 20× speedups. 2.…
This is still the greatest Bitcoin explanation of all time.
This is solid work, yet for me to understand it 100% and go over the repo but its showing clearly that high-quality synthetic data from DeepSeek-R1 can drive major reasoning improvements through SFT alone - no RL needed. The cross-domain generalization from math to code with…
We've released a series of OpenReasoning-Nemotron models (1.5B, 7B, 14B and 32B) that set new SOTA on a wide range of reasoning benchmarks across open-weight models of corresponding size. The models are based on Qwen2.5 architecture and are trained with SFT on the data…
Good luck @marquinhos_m5 and @PSG_English was nice seeing you this morning before the game #soccer #PSGvsChelsea #football

Why SLMs (Small Language Models) Shine in Agentic AI? The paper “Small Language Models are the Future of Agentic AI,” submitted June 2, 2025, by NVIDIA Research, argues that small language models (SLMs) will surpass large ones (LLMs) in the realm of agentic systems. Here is a…
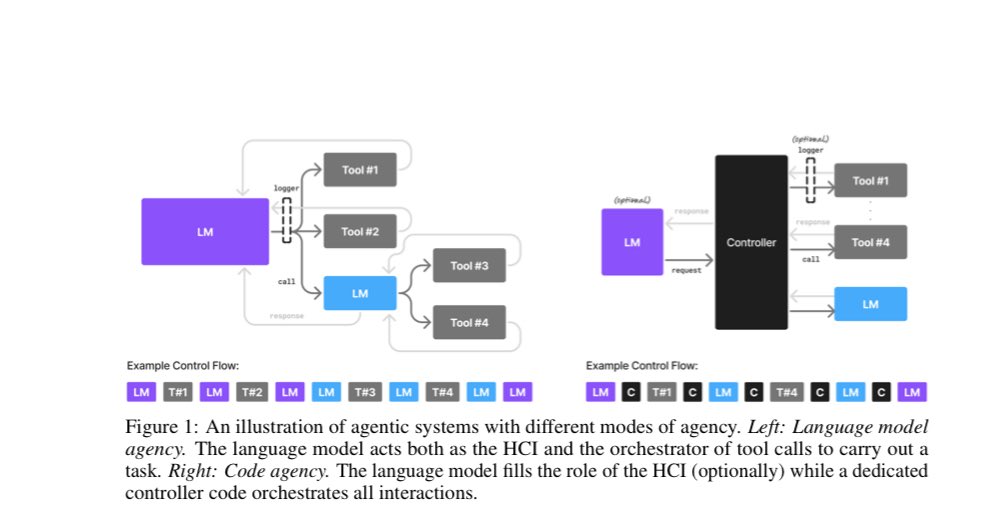
I’m excited to share NVIDIA’s new blog published on June 25, 2025, by my colleague Igor Gitman “How to Streamline Complex LLM Workflows Using NVIDIA NeMo‑Skills.” This is a must-read if you’re working on robust LLM pipelines. developer.nvidia.com/blog/how-to-st… Here are the standout…
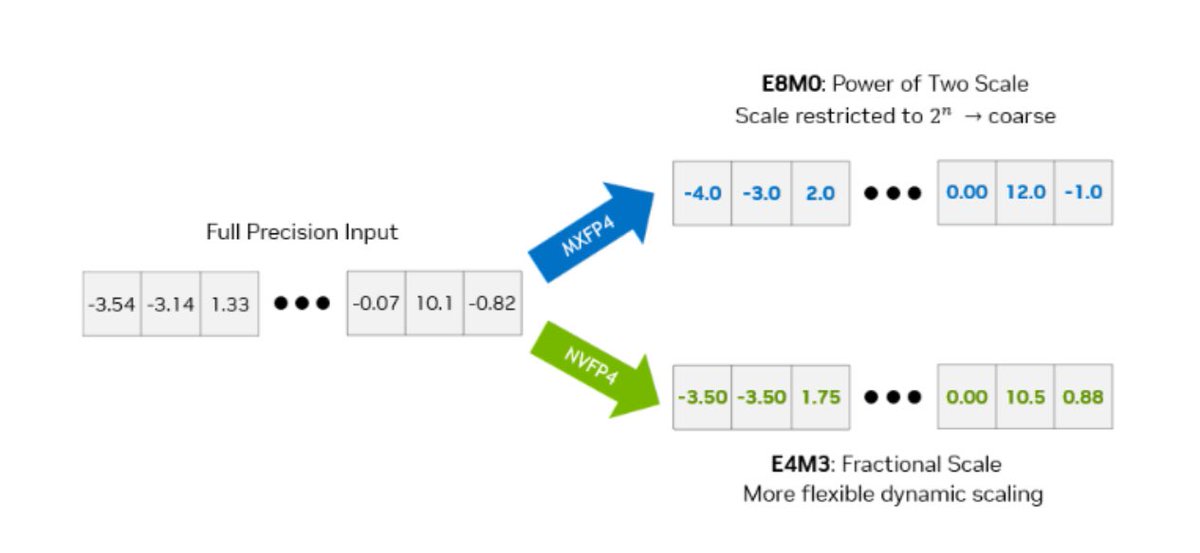
NVFP4, a game-changing 4‑bit floating‑point format designed for ultra‑efficient, high‑accuracy model inference on Blackwell GPUs. Why NVFP4 matters •Superior precision: Utilizes a two‑level scaling approach with FP8 micro‑block scales and per‑tensor FP32 normalization, reducing…
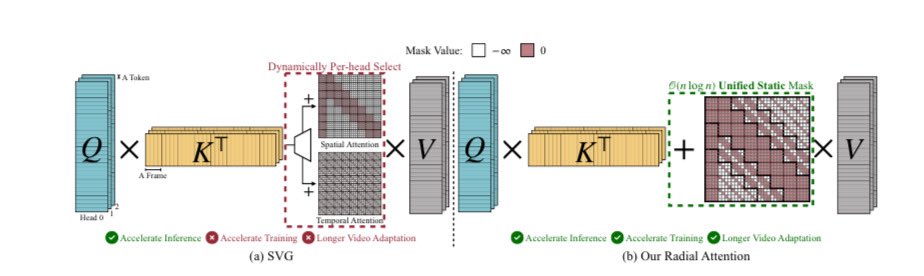
In a collaborative effort between MIT, Nvidia, Princeton, UC Berkeley, Satanford and First Intelligence: Introducing Radial Attention: Efficient Sparse Attention for Long Video Generation Published June 24, 2025 by Xingyang Li et al. Challenge: Video diffusion models produce…
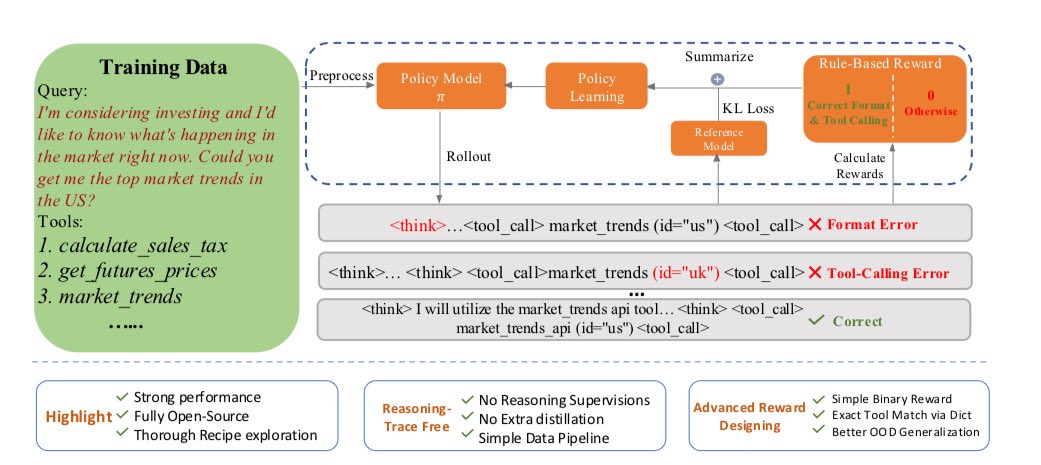
Great paper to read this weekend: “Exploring Tool‑Using Language Models with Reinforced Reasoning” (arXiv:2505.00024), arxiv.org/pdf/2505.00024 a contribution by Zhang et al. from NVIDIA and Penn State, diving into a novel way of teaching LLMs how to call tools intelligently.…
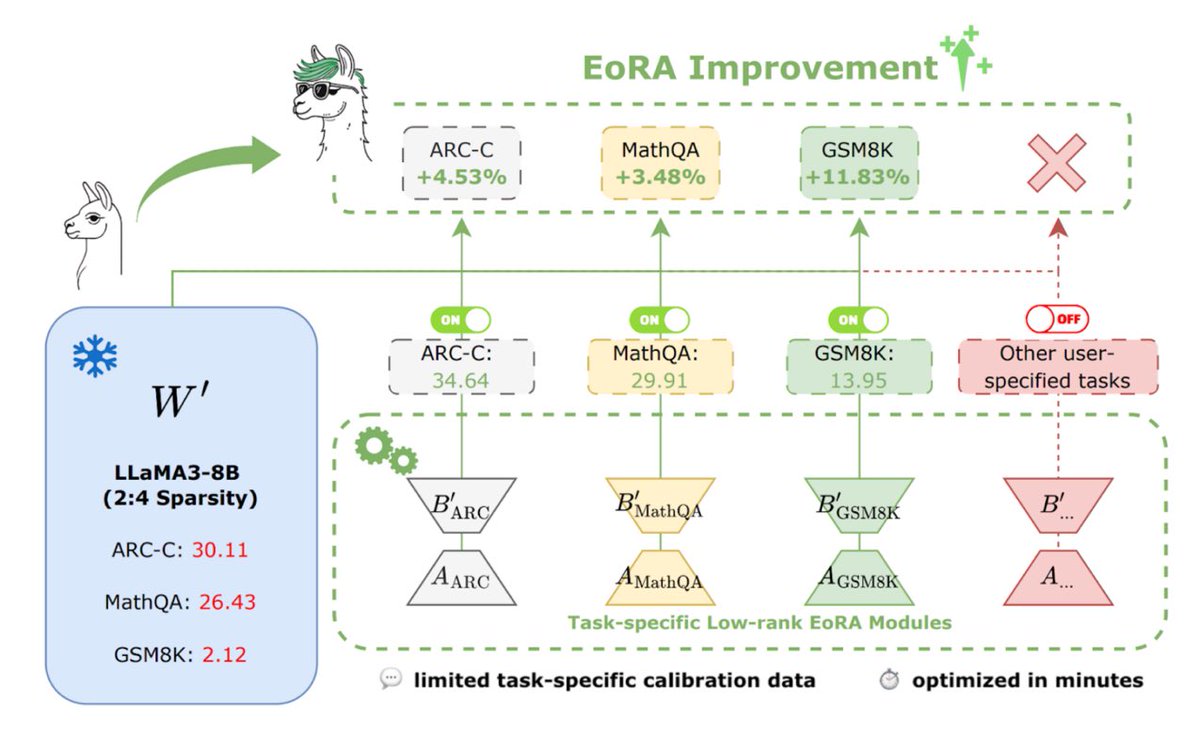
NVIDIA’s EoRA Makes LLM Compression Lightning Fast⚡ The AI community just got a major breakthrough! NVIDIA Research has unveiled EoRA (Eigenspace Low-Rank Approximation) - a revolutionary approach that recovers LLM compression errors in MINUTES, not hours. Why this matters: ✅…
Oh boy! Are AI Reasoning Models Really Hitting a “Complexity Wall”? alphaxiv.org/abs/2506.09250 A fascinating debate is unfolding about whether Large Reasoning Models (LRMs) truly face fundamental limitations when tackling complex problems. Lets take a step back & look at the…
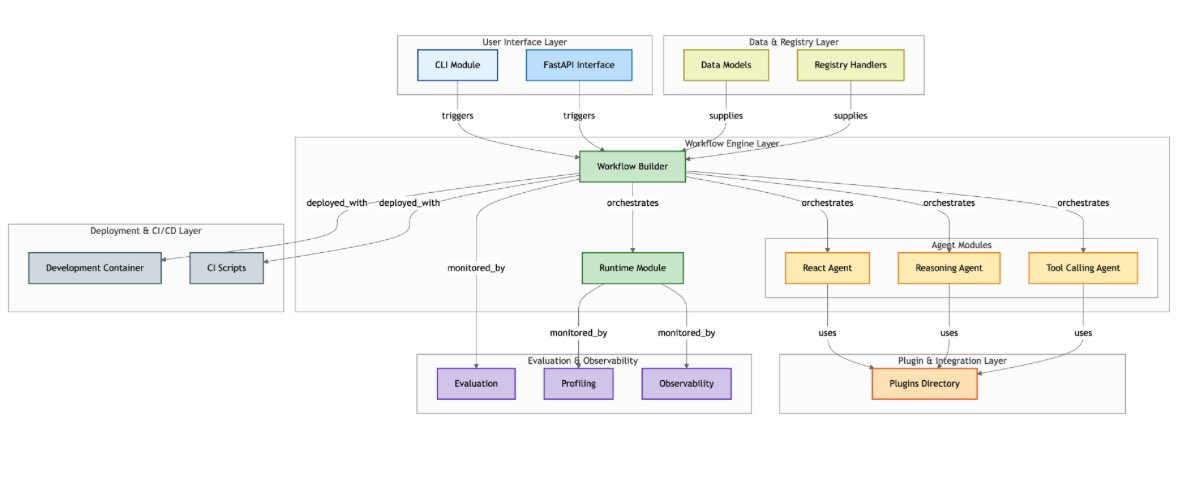
I spent this morning exploring NVIDIA's open-source Agent Intelligence toolkit, which today provides a unified framework for orchestrating collaborative AI agent systems at scale. Key highlights: • Creates a standardized interface across major frameworks (LangChain,…
COMING SOON 😇: Part 2 of my NeMo LoRA fine-tuning series: "Perfecting LLM Fine-tuning: The Data Quality Advantage with NeMo Curator" Following up on my first guide (medium.com/@thammadou/pra…), this upcoming deep dive focuses on the critical role of data quality. In Part 1, we…

AgentIQ: Orchestrate AI Agents with True Composability In today’s rapidly evolving AI landscape, enterprises are deploying agents everywhere—but integration remains a challenge. Enter AgentIQ, an open-source library by NVIDIA designed to seamlessly integrate AI agents, tools,…