
Ted Zadouri
@tedzadouri
PhD Student @PrincetonCS @togethercompute | Previously: @cohere @UCLA
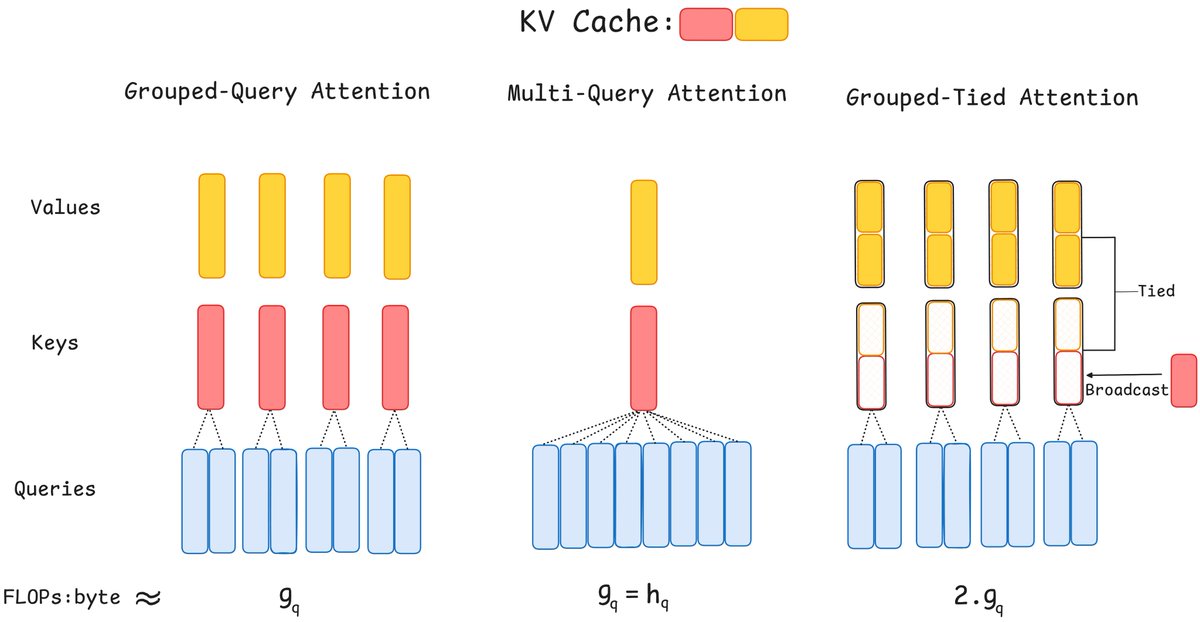
"Pre-training was hard, inference easy; now everything is hard."-Jensen Huang. Inference drives AI progress b/c of test-time compute. Introducing inference aware attn: parallel-friendly, high arithmetic intensity – Grouped-Tied Attn & Grouped Latent Attn

Congrats to @parastooabtahi, @tri_dao and Alex Lombardi on being named 2025 Google Research Scholars. 🎉 The @googleresearch scholars program funds world-class research conducted by early-career professors. bit.ly/4kvpvFx
CuTe DSL feels almost unreal: minimal Python code hits peak memory throughput on H100, as we show in QuACK. Can't wait for the addition of kernels optimized for Blackwell in QuACK 🦆
🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
Getting mem-bound kernels to speed-of-light isn't a dark art, it's just about getting the a couple of details right. We wrote a tutorial on how to do this, with code you can directly use. Thanks to the new CuTe-DSL, we can hit speed-of-light without a single line of CUDA C++.
🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
🦆QuACK: blazing fast cute-DSL GPU kernels with 3TB/s goodness! Optimizing your kernels as much as possible is important... unless you are okay with leaving throughput on the table. check out this work from @wentao, @tedzadouri and @tri_dao
🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
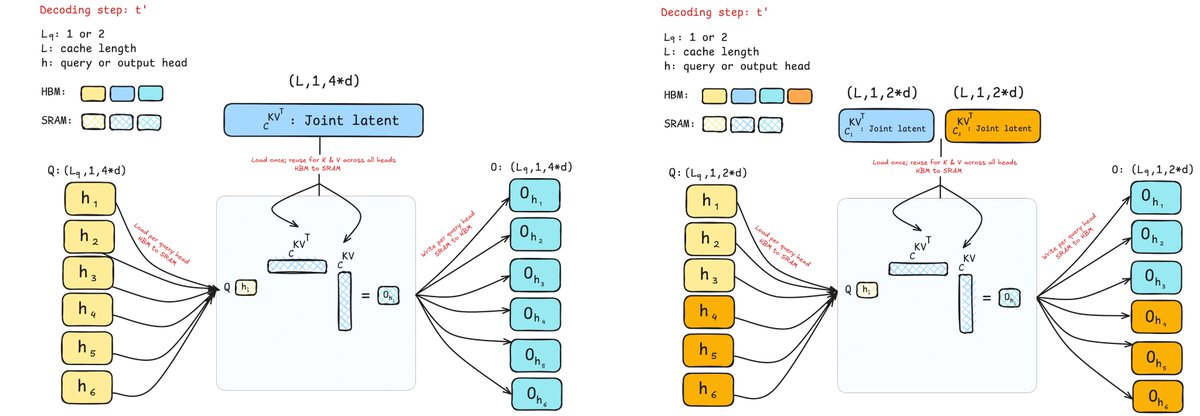
Great project where we rethink attention for inference: Grouped-Tied Attn (GTA) ties the KV, and Grouped Latent Attn (GLA) shards low-rank latents across GPUs. Results: high arithmetic intensity, high quality models and parallel-friendly. Kudos to the team !!
"Pre-training was hard, inference easy; now everything is hard."-Jensen Huang. Inference drives AI progress b/c of test-time compute. Introducing inference aware attn: parallel-friendly, high arithmetic intensity – Grouped-Tied Attn & Grouped Latent Attn
Hardware-Efficient Attention for Fast Decoding Princeton optimizes decoding by maximizing arithmetic intensity (FLOPs/byte) for better memory–compute efficiency: - GTA (Grouped-Tied Attention) Ties key/value states + partial RoPE → 2× arithmetic intensity vs. GQA, ½ KV cache,…
Hardware-Efficient Attention for Fast Decoding "We first propose Grouped-Tied Attention (GTA), a simple variant that combines and reuses key and value states, reducing memory transfers without compromising model quality. We then introduce Grouped Latent Attention (GLA), a…
We've been thinking about what the "ideal" architecture should look like in the era where inference is driving AI progress. GTA & GLA are steps in this direction: attention variants tailored for inference: high arithmetic intensity (make GPUs go brr even during decoding), easy to…
"Pre-training was hard, inference easy; now everything is hard."-Jensen Huang. Inference drives AI progress b/c of test-time compute. Introducing inference aware attn: parallel-friendly, high arithmetic intensity – Grouped-Tied Attn & Grouped Latent Attn