
skcd
@skcd42
hacking @aide_dev ex fb engineer ICPC WF its just code 👨🏼💻
CodeStory agent is now SOTA on swebench-verified with 62.2% resolution rate. We did this by scaling our agent on test time inference and re-learning the bitter lesson. Sonnet3.5(new) was the only LLM we used for this run

one of the greatest joys of debugging systems for me is: - removing debug logs once I gain confidence in different parts and hone in onto the bugs no more grepping 500MB+ files, but 30MB+ files now
Humanity has prevailed (for now!) I'm completely exhausted. I figured, I had 10h of sleep in the last 3 days and I'm barely alive. I'll post more about the contest when I get some rest. (To be clear, those are provisional results, but my lead should be big enough)
be like Scott! goated leader 🫡
It’s a privilege to welcome Windsurf to Cognition. Here are more details in the note I sent to our Cognition team this morning: Team, As discussed during our all-hands, we are acquiring Windsurf. We have now signed a definitive agreement and we couldn’t be more excited. Here’s…
No grand plans, follow the gradient of user value
I have never seen it expressed exactly like that, but I wholeheartedly endorse it: Feedback beats planning. My plea at Meta was “No grand plans, follow the gradient of user value”.
Codebase understanding: Level 1: Embeddings search + summarization Level 2: Workflow based routine to get relevant snippets + summarization Level 3: Basic tool calling in a loop with sonnet3.7 + summarization Level 4: Dev environment where the agent purposefully adds debug logs,…
I recall talking to a lot of people this week about sonnet3.7 very effectively using a Think tool. an extrapolation of this is: - think tool use points are pivot points in the agents trajectory (you can branch off at these points) - smarter rollbacks to the last thinking tool…
New research from our team at @AnthropicAI shows how giving Claude a simple 'think' tool dramatically improves instruction adherence and multi-step problem solving for agents. We've documented our findings in a blog post:
been reading the SWE-RL research, I am not sure if calling it full on RL for SWE is the right description. effectively they are using Agentless which is a framework and reduces/takes away so much freedom from the LLM and the RL training is done on the edit generation. pretty…
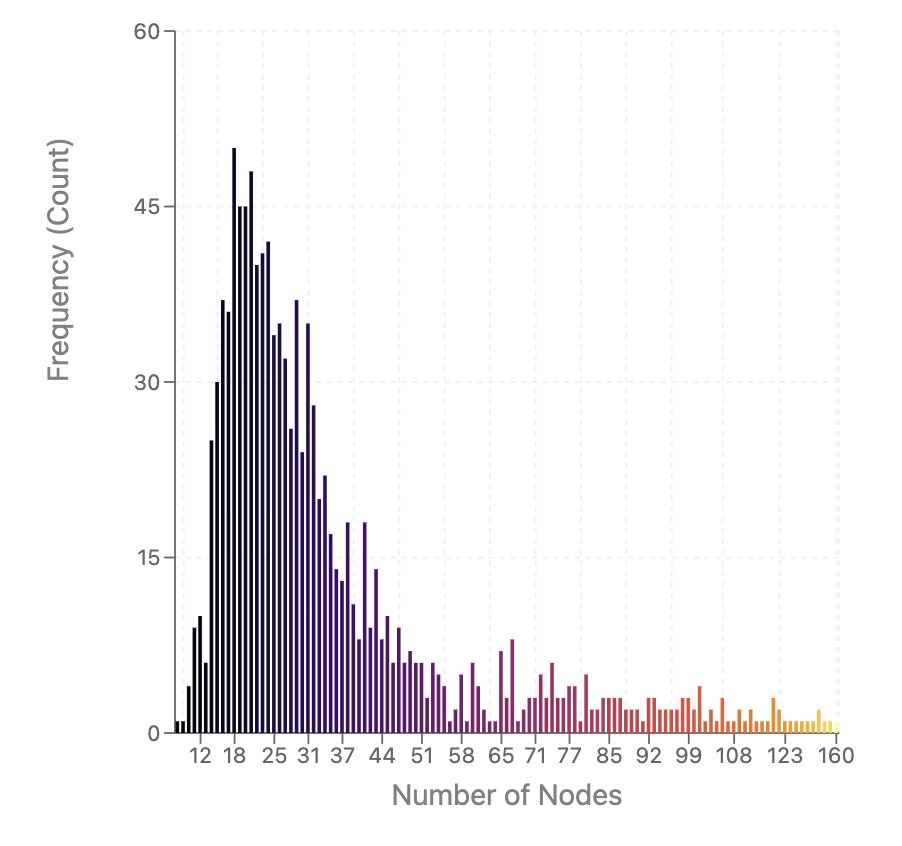
spending time looking at data distribution of O(num_nodes) and their count over 1k agent trajectories Peaks around the range of 18-20 steps, but do pay attention to the long tail here, they tell an important story - how do you make the agent maintain coherence over these long…
sonnet3.7 system card literally spills out what product developers should focus on: > During our evaluations we noticed that Claude 3.7 Sonnet occasionally resorts to special-casing in order to pass test cases in agentic coding environments like Claude Code Thankfully with our…

malenia no hit run when?
Claude-3.7 was tested on Pokémon Red, but what about more real-time games like Super Mario 🍄🌟? We threw AI gaming agents into LIVE Super Mario games and found Claude-3.7 outperformed other models with simple heuristics. 🤯 Claude-3.5 is also strong, but less capable of…