
rowan
@rowankwang
@anthropicai
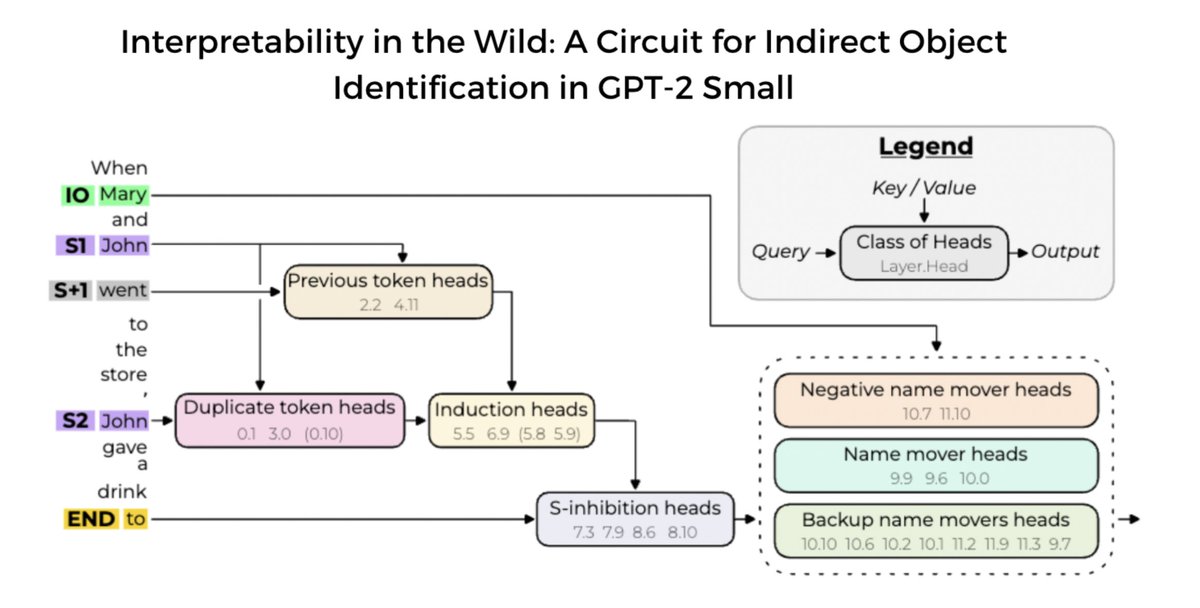
Announcing our new mechanistic interpretability paper! We use causal interventions to reverse-engineer a 26-head circuit in GPT-2 small (inspired by @ch402’s circuits work) The largest end-to-end explanation of a natural LM behavior, our circuit is localized + interpretable 🧵
We've made Claude Opus 4 and Claude Sonnet 4 significantly better at avoiding reward hacking behaviors (like hard-coding and special-casing in code settings) that we frequently saw in Claude Sonnet 3.7.
Ever wonder how a language model decides what to say next? Our method, the tuned lens (arxiv.org/abs/2303.08112), can trace an LM’s prediction as it develops from one layer to the next. It's more reliable and applies to more models than prior state-of-the-art. 🧵
New paper walkthrough: Interpretability in the Wild is a great new paper on mechanistic interpretability of GPT-2. In Part 1, authors @kevrowan @A_Variengien & @ArthurConmy join me to discuss what the paper is about and what's most exciting about it! youtu.be/gzwj0jWbvbo
@kevrowan's paper is one of the coolest interp papers I've seen in a while, super excited about this line of work! They reverse engineer a 26 head circuit in GPT-2 Small, with 7 types of head and 4 layers composing. And @kevrowan is still in high school!! A 🧵 of my takeaways:
Announcing our new mechanistic interpretability paper! We use causal interventions to reverse-engineer a 26-head circuit in GPT-2 small (inspired by @ch402’s circuits work) The largest end-to-end explanation of a natural LM behavior, our circuit is localized + interpretable 🧵